Just rephrase it! Uncertainty estimation in closed-source language models via multiple rephrased queries

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) are increasingly being provided as closed-source services, but these models often do not provide estimates of their own uncertainty when answering queries.
- Lack of uncertainty estimates can limit the applicability of these models in critical settings, as even the best models may "hallucinate" false information with high confidence.
- The researchers explore methods for estimating the uncertainty of closed-source LLMs by asking multiple rephrased versions of a base query and using the similarity of the answers as an estimate of uncertainty.
- Their approach provides simple rephrasing rules and a theoretical framework for why this method can obtain calibrated uncertainty estimates.
Plain English Explanation
Large artificial intelligence (AI) language models are increasingly being made available as closed-source services, meaning the public can use them but the inner workings are not openly shared. While these closed-source models are widely used, they often do not provide any information about how certain they are in their responses.
This lack of "uncertainty quantification" can be problematic, as even the most advanced language models can sometimes produce false information confidently. If a model is unsure about its answer but presents it as fact, it could lead to serious problems in critical applications like healthcare or financial decisions.
To address this issue, the researchers propose a method to estimate the uncertainty of closed-source language models. The key idea is to ask the model multiple slightly different versions of the same question and then use the similarity of the responses as a measure of the model's confidence. If the answers are very different, that suggests the model is unsure. If the answers are very similar, that suggests the model is confident.
The researchers provide simple guidelines for rephrasing questions in a way that works well for this approach. They also develop a theoretical justification for why this method can produce well-calibrated uncertainty estimates.
Overall, this research aims to make closed-source language models more transparent and trustworthy by allowing users to better understand the models' confidence in their responses.
Technical Explanation
The researchers propose a method to estimate the uncertainty of closed-source, black-box large language models (LLMs) by leveraging multiple rephrased versions of an original query.
Specifically, they ask the model several slightly different questions related to the same underlying topic and use the similarity of the responses as a proxy for the model's uncertainty. If the answers are very different, it suggests the model is unsure. If the answers are very similar, it suggests the model is confident.
The key innovations of this work are:
- Providing a set of simple rephrasing rules that are easy to memorize and apply in practice.
- Developing a theoretical framework to explain why this query rephrasing approach can produce well-calibrated uncertainty estimates.
The researchers evaluate their method on several benchmark tasks and demonstrate significant improvements in the calibration of uncertainty estimates compared to baseline approaches.
Critical Analysis
The researchers acknowledge several limitations and areas for future work:
- The proposed rephrasing rules, while simple, may not generalize well to all types of queries or model capabilities. More sophisticated rephrasing strategies may be needed in some cases.
- The theoretical framework makes certain assumptions about the underlying model and data distribution that may not always hold in practice.
- The evaluation is limited to closed-source models, and it's unclear how the method would perform on open-source models where more internal information is available.
- The impact of this approach on downstream task performance (beyond just uncertainty estimation) is not thoroughly explored.
Additionally, one could argue that the reliance on multiple queries to estimate uncertainty introduces additional overhead and latency, which may not be practical in some real-world applications.
Overall, this research represents an important step towards making closed-source language models more transparent and trustworthy. However, further work is needed to address the identified limitations and explore the broader implications of uncertainty-aware language models.
Conclusion
This paper presents a novel method for estimating the uncertainty of closed-source, black-box large language models by leveraging multiple rephrased versions of an original query. The key contributions are simple rephrasing rules and a theoretical framework that explain why this approach can produce well-calibrated uncertainty estimates.
While the method has some limitations, it represents a significant advance in making language models more transparent and uncertainty-aware, which is crucial for the responsible deployment of these powerful AI systems in critical applications. The research also highlights the importance of continued innovation in the area of uncertainty quantification for large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Just rephrase it! Uncertainty estimation in closed-source language models via multiple rephrased queries
Adam Yang, Chen Chen, Konstantinos Pitas
State-of-the-art large language models are sometimes distributed as open-source software but are also increasingly provided as a closed-source service. These closed-source large-language models typically see the widest usage by the public, however, they often do not provide an estimate of their uncertainty when responding to queries. As even the best models are prone to ``hallucinating false information with high confidence, a lack of a reliable estimate of uncertainty limits the applicability of these models in critical settings. We explore estimating the uncertainty of closed-source LLMs via multiple rephrasings of an original base query. Specifically, we ask the model, multiple rephrased questions, and use the similarity of the answers as an estimate of uncertainty. We diverge from previous work in i) providing rules for rephrasing that are simple to memorize and use in practice ii) proposing a theoretical framework for why multiple rephrased queries obtain calibrated uncertainty estimates. Our method demonstrates significant improvements in the calibration of uncertainty estimates compared to the baseline and provides intuition as to how query strategies should be designed for optimal test calibration.
Read more6/18/2024

0
Question Rephrasing for Quantifying Uncertainty in Large Language Models: Applications in Molecular Chemistry Tasks
Zizhang Chen, Pengyu Hong, Sandeep Madireddy
Uncertainty quantification enables users to assess the reliability of responses generated by large language models (LLMs). We present a novel Question Rephrasing technique to evaluate the input uncertainty of LLMs, which refers to the uncertainty arising from equivalent variations of the inputs provided to LLMs. This technique is integrated with sampling methods that measure the output uncertainty of LLMs, thereby offering a more comprehensive uncertainty assessment. We validated our approach on property prediction and reaction prediction for molecular chemistry tasks.
Read more8/9/2024

0
Uncertainty Estimation of Large Language Models in Medical Question Answering
Jiaxin Wu, Yizhou Yu, Hong-Yu Zhou
Large Language Models (LLMs) show promise for natural language generation in healthcare, but risk hallucinating factually incorrect information. Deploying LLMs for medical question answering necessitates reliable uncertainty estimation (UE) methods to detect hallucinations. In this work, we benchmark popular UE methods with different model sizes on medical question-answering datasets. Our results show that current approaches generally perform poorly in this domain, highlighting the challenge of UE for medical applications. We also observe that larger models tend to yield better results, suggesting a correlation between model size and the reliability of UE. To address these challenges, we propose Two-phase Verification, a probability-free Uncertainty Estimation approach. First, an LLM generates a step-by-step explanation alongside its initial answer, followed by formulating verification questions to check the factual claims in the explanation. The model then answers these questions twice: first independently, and then referencing the explanation. Inconsistencies between the two sets of answers measure the uncertainty in the original response. We evaluate our approach on three biomedical question-answering datasets using Llama 2 Chat models and compare it against the benchmarked baseline methods. The results show that our Two-phase Verification method achieves the best overall accuracy and stability across various datasets and model sizes, and its performance scales as the model size increases.
Read more7/12/2024
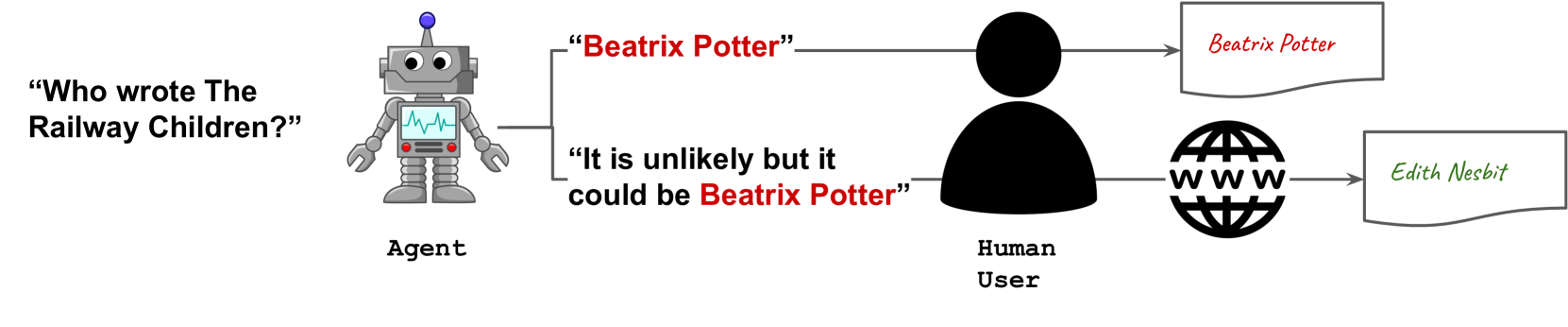
0
Finetuning Language Models to Emit Linguistic Expressions of Uncertainty
Arslan Chaudhry, Sridhar Thiagarajan, Dilan Gorur
Large language models (LLMs) are increasingly employed in information-seeking and decision-making tasks. Despite their broad utility, LLMs tend to generate information that conflicts with real-world facts, and their persuasive style can make these inaccuracies appear confident and convincing. As a result, end-users struggle to consistently align the confidence expressed by LLMs with the accuracy of their predictions, often leading to either blind trust in all outputs or a complete disregard for their reliability. In this work, we explore supervised finetuning on uncertainty-augmented predictions as a method to develop models that produce linguistic expressions of uncertainty. Specifically, we measure the calibration of pre-trained models and then fine-tune language models to generate calibrated linguistic expressions of uncertainty. Through experiments on various question-answering datasets, we demonstrate that LLMs are well-calibrated in assessing their predictions, and supervised finetuning based on the model's own confidence leads to well-calibrated expressions of uncertainty, particularly for single-claim answers.
Read more9/19/2024