Language-guided Image Reflection Separation

0
🖼️
Sign in to get full access
Overview
- This paper addresses the problem of separating reflections from images, which is a challenging task in computer vision.
- The researchers propose a unified framework that leverages language descriptions to help guide the reflection separation process.
- The framework uses cross-attention mechanisms and contrastive learning to connect language descriptions with the corresponding image layers.
- The researchers also introduce a gated network design and a randomized training strategy to handle the ambiguity of recognizable layers.
- The proposed method outperforms existing reflection separation techniques in both quantitative and qualitative evaluations.
Plain English Explanation
When you take a picture, the final image can sometimes contain unwanted reflections, like the reflection of a window or a mirror. Removing these reflections is a difficult problem in computer vision, as it's not always clear where the reflections are coming from or what the original scene should look like.
This research paper presents a new approach to solving this "reflection separation" problem. Instead of relying solely on the visual information in the image, the researchers incorporate language descriptions to provide additional context about the scene. For example, a language description might say "this is a picture of a person standing in front of a window with some reflections."
The key idea is to use this language information to help the computer system understand which parts of the image are the actual scene and which parts are reflections. The system uses an attention-based approach to find the connections between the language and the image layers, and it also has a clever way of dealing with ambiguity in the layers.
Overall, the researchers show that their language-guided approach outperforms existing reflection separation methods, both in terms of the quantitative results and the visual quality of the separated reflections. This work demonstrates how combining language and vision can lead to better solutions for challenging computer vision problems.
Technical Explanation
The paper proposes a unified framework to solve the language-guided reflection separation problem. The framework leverages the cross-attention mechanism with contrastive learning strategies to construct the correspondence between language descriptions and image layers.
A gated network design and a randomized training strategy are employed to tackle the recognizable layer ambiguity. The gated network helps the system focus on the relevant parts of the image, while the randomized training strategy makes the system more robust to different types of reflections.
The effectiveness of the proposed method is validated through significant performance advantages over existing reflection separation techniques, as demonstrated by both quantitative and qualitative comparisons.
Critical Analysis
The paper provides a comprehensive solution to the challenging problem of language-guided reflection separation. The proposed framework leverages the power of cross-attention and contrastive learning to effectively connect language descriptions with the corresponding image layers.
However, the paper does not discuss the potential limitations of the approach, such as the reliance on the availability and quality of language descriptions. In real-world scenarios, the language descriptions may not always be complete or accurate, which could impact the performance of the system.
Additionally, the paper does not explore the potential for self-supervised learning to extract relevant language information from the image context, without the need for explicit language descriptions. This could be an interesting direction for future research.
Overall, the paper presents a strong and innovative solution to the reflection separation problem, but it would be valuable to see further discussions on the limitations and potential future research directions to address them.
Conclusion
This paper introduces a novel framework for language-guided reflection separation, a challenging computer vision problem. By incorporating language descriptions to provide contextual information about the scene, the researchers demonstrate a significant performance improvement over existing reflection separation techniques.
The key innovations of the proposed framework include the use of cross-attention mechanisms and contrastive learning to establish the connection between language and image layers, as well as the gated network design and randomized training strategy to handle layer ambiguity.
This work highlights the potential of combining language and vision to solve complex computer vision problems, and it opens up new avenues for further research in this direction. The advancements made in this paper could have important implications for a wide range of applications, such as computational photography, augmented reality, and scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Language-guided Image Reflection Separation
Haofeng Zhong, Yuchen Hong, Shuchen Weng, Jinxiu Liang, Boxin Shi
This paper studies the problem of language-guided reflection separation, which aims at addressing the ill-posed reflection separation problem by introducing language descriptions to provide layer content. We propose a unified framework to solve this problem, which leverages the cross-attention mechanism with contrastive learning strategies to construct the correspondence between language descriptions and image layers. A gated network design and a randomized training strategy are employed to tackle the recognizable layer ambiguity. The effectiveness of the proposed method is validated by the significant performance advantage over existing reflection separation methods on both quantitative and qualitative comparisons.
Read more6/5/2024

0
Towards Flexible Interactive Reflection Removal with Human Guidance
Xiao Chen, Xudong Jiang, Yunkang Tao, Zhen Lei, Qing Li, Chenyang Lei, Zhaoxiang Zhang
Single image reflection removal is inherently ambiguous, as both the reflection and transmission components requiring separation may follow natural image statistics. Existing methods attempt to address the issue by using various types of low-level and physics-based cues as sources of reflection signals. However, these cues are not universally applicable, since they are only observable in specific capture scenarios. This leads to a significant performance drop when test images do not align with their assumptions. In this paper, we aim to explore a novel flexible interactive reflection removal approach that leverages various forms of sparse human guidance, such as points and bounding boxes, as auxiliary high-level prior to achieve robust reflection removal. However, incorporating the raw user guidance naively into the existing reflection removal network does not result in performance gains. To this end, we innovatively transform raw user input into a unified form -- reflection masks using an Interactive Segmentation Foundation Model. Such a design absorbs the quintessence of the foundational segmentation model and flexible human guidance, thereby mitigating the challenges of reflection separations. Furthermore, to fully utilize user guidance and reduce user annotation costs, we design a mask-guided reflection removal network, comprising our proposed self-adaptive prompt block. This block adaptively incorporates user guidance as anchors and refines transmission features via cross-attention mechanisms. Extensive results on real-world images validate that our method demonstrates state-of-the-art performance on various datasets with the help of flexible and sparse user guidance. Our code and dataset will be publicly available here https://github.com/ShawnChenn/FlexibleReflectionRemoval.
Read more6/4/2024
0
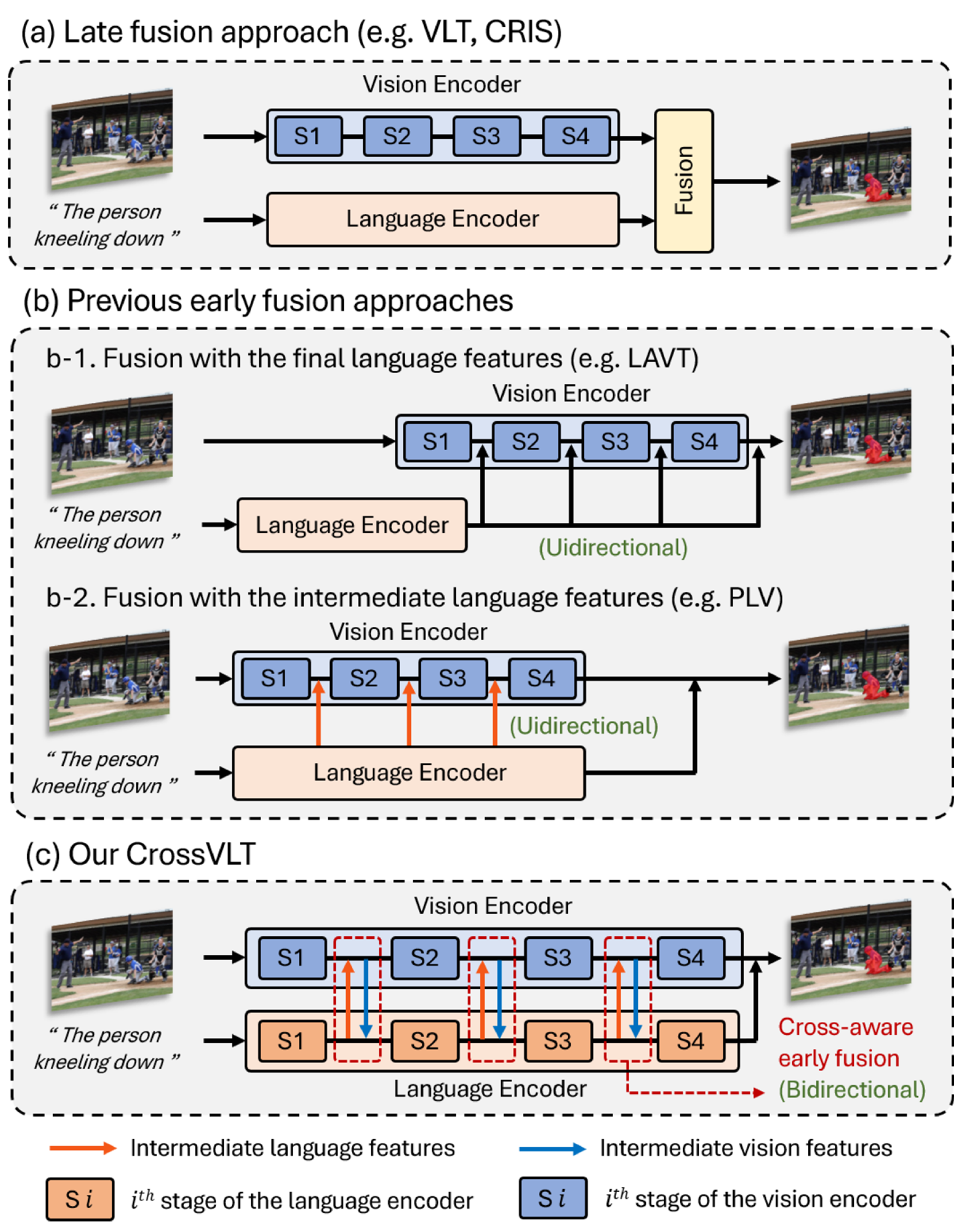
Cross-aware Early Fusion with Stage-divided Vision and Language Transformer Encoders for Referring Image Segmentation
Yubin Cho, Hyunwoo Yu, Suk-ju Kang
Referring segmentation aims to segment a target object related to a natural language expression. Key challenges of this task are understanding the meaning of complex and ambiguous language expressions and determining the relevant regions in the image with multiple objects by referring to the expression. Recent models have focused on the early fusion with the language features at the intermediate stage of the vision encoder, but these approaches have a limitation that the language features cannot refer to the visual information. To address this issue, this paper proposes a novel architecture, Cross-aware early fusion with stage-divided Vision and Language Transformer encoders (CrossVLT), which allows both language and vision encoders to perform the early fusion for improving the ability of the cross-modal context modeling. Unlike previous methods, our method enables the vision and language features to refer to each other's information at each stage to mutually enhance the robustness of both encoders. Furthermore, unlike the conventional scheme that relies solely on the high-level features for the cross-modal alignment, we introduce a feature-based alignment scheme that enables the low-level to high-level features of the vision and language encoders to engage in the cross-modal alignment. By aligning the intermediate cross-modal features in all encoder stages, this scheme leads to effective cross-modal fusion. In this way, the proposed approach is simple but effective for referring image segmentation, and it outperforms the previous state-of-the-art methods on three public benchmarks.
Read more8/15/2024
0
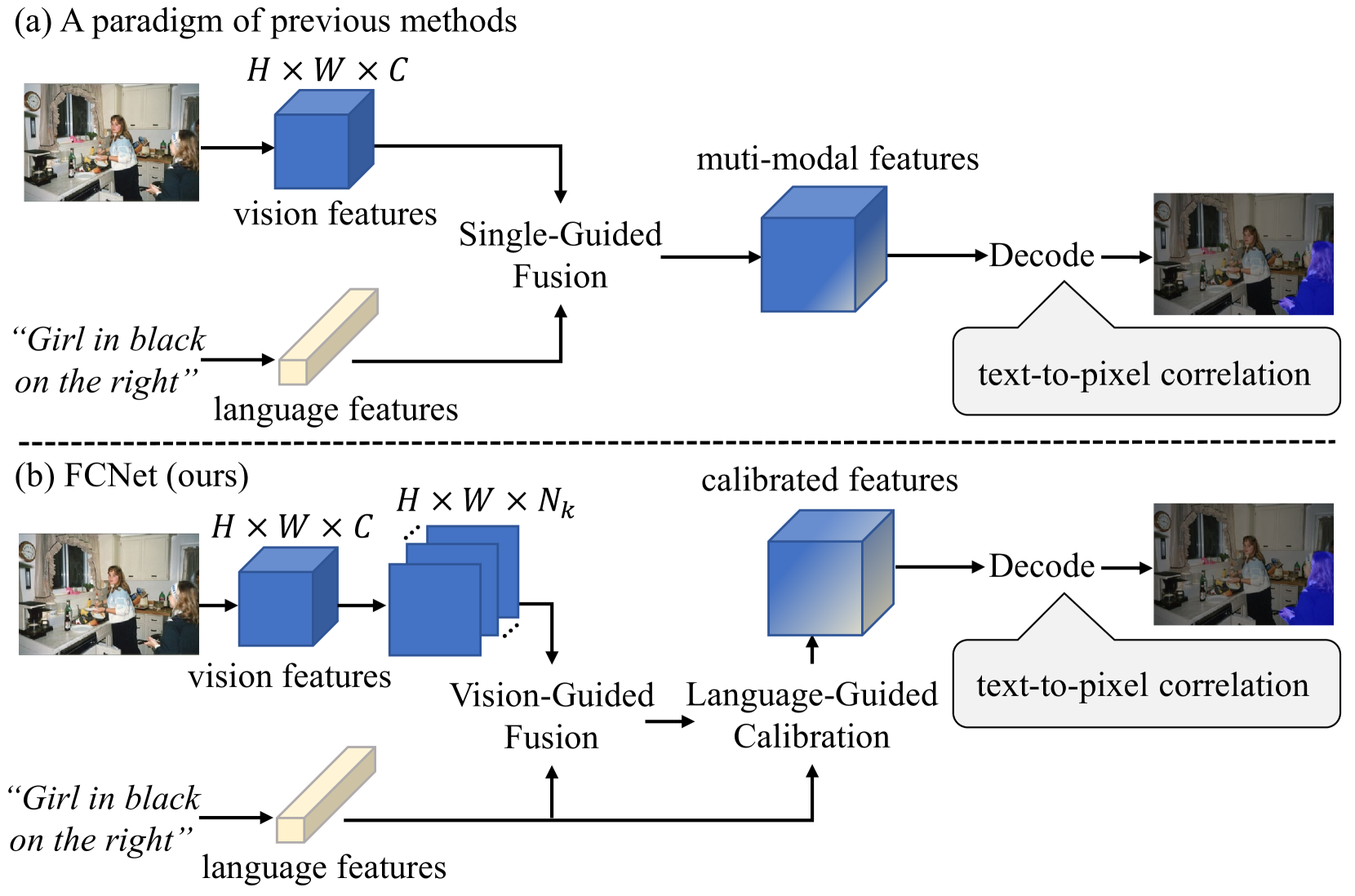
Fuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation
Yichen Yan, Xingjian He, Sihan Chen, Shichen Lu, Jing Liu
Referring Image Segmentation (RIS) aims to segment an object described in natural language from an image, with the main challenge being a text-to-pixel correlation. Previous methods typically rely on single-modality features, such as vision or language features, to guide the multi-modal fusion process. However, this approach limits the interaction between vision and language, leading to a lack of fine-grained correlation between the language description and pixel-level details during the decoding process. In this paper, we introduce FCNet, a framework that employs a bi-directional guided fusion approach where both vision and language play guiding roles. Specifically, we use a vision-guided approach to conduct initial multi-modal fusion, obtaining multi-modal features that focus on key vision information. We then propose a language-guided calibration module to further calibrate these multi-modal features, ensuring they understand the context of the input sentence. This bi-directional vision-language guided approach produces higher-quality multi-modal features sent to the decoder, facilitating adaptive propagation of fine-grained semantic information from textual features to visual features. Experiments on RefCOCO, RefCOCO+, and G-Ref datasets with various backbones consistently show our approach outperforming state-of-the-art methods.
Read more5/21/2024