Unveiling Linguistic Regions in Large Language Models
2402.14700
0
0
Abstract
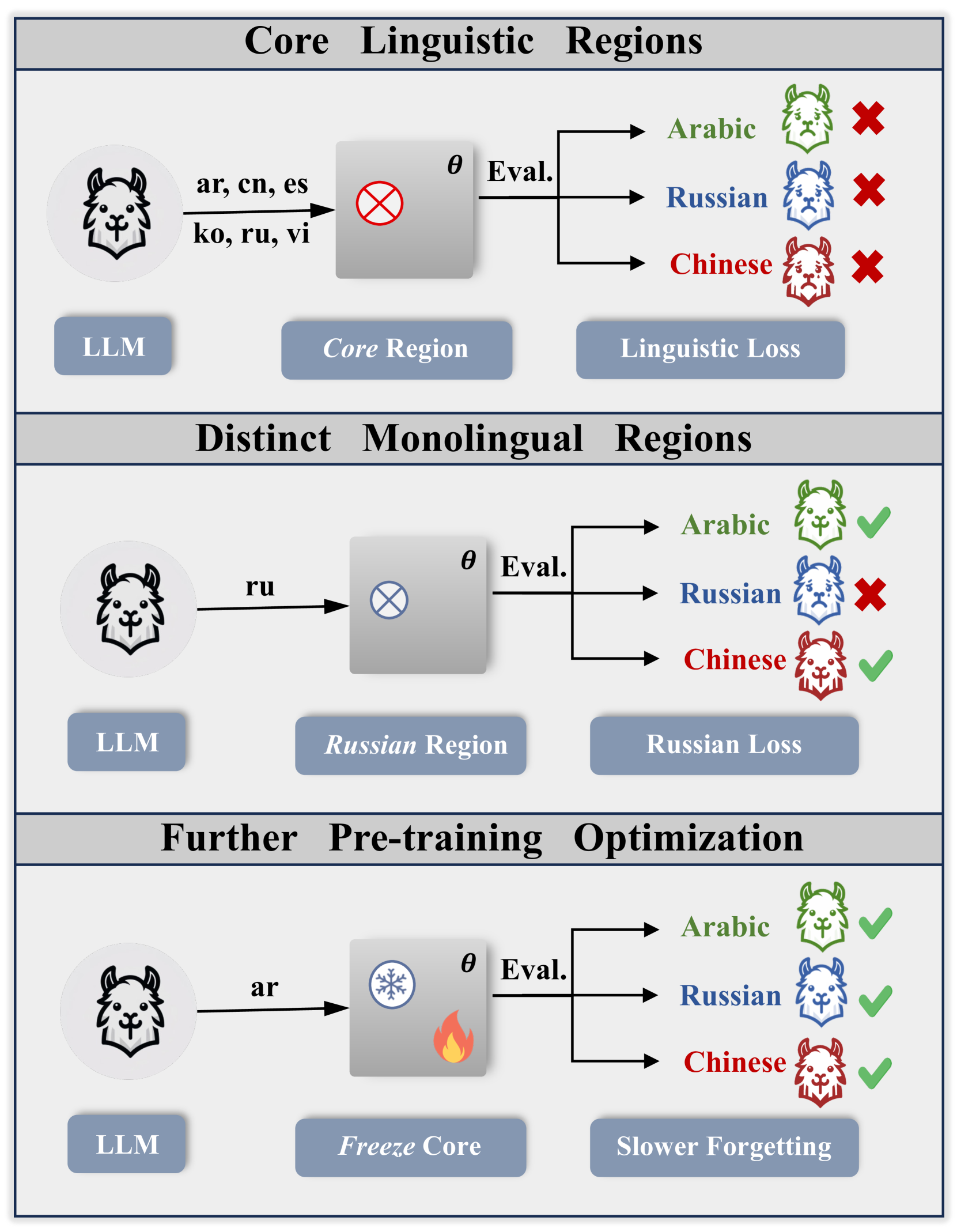
Large Language Models (LLMs) have demonstrated considerable cross-lingual alignment and generalization ability. Current research primarily focuses on improving LLMs' cross-lingual generalization capabilities. However, there is still a lack of research on the intrinsic mechanisms of how LLMs achieve cross-lingual alignment. From the perspective of region partitioning, this paper conducts several investigations on the linguistic competence of LLMs. We discover a core region in LLMs that corresponds to linguistic competence, accounting for approximately 1% of the total model parameters. Removing this core region by setting parameters to zero results in a significant performance decrease across 30 different languages. Furthermore, this core region exhibits significant dimensional dependence, perturbations to even a single parameter on specific dimensions leading to a loss of linguistic competence. Moreover, we discover that distinct monolingual regions exist for different languages, and disruption to these specific regions substantially reduces the LLMs' proficiency in those corresponding languages. Our research also indicates that freezing the core linguistic region during further pre-training can mitigate the issue of catastrophic forgetting (CF), a common phenomenon observed during further pre-training of LLMs. Overall, exploring the LLMs' functional regions provides insights into the foundation of their intelligence.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can uncover distinct linguistic regions within their representations.
- The researchers introduce a novel metric called "Linguistic Region Dispersion" (LRD) to quantify the degree of linguistic separation in LLM embeddings.
- They apply this metric to analyze the multilingual capabilities of several state-of-the-art LLMs, including XLMR, mT5, and ByT5.
- The findings provide insights into the multilingual encoding abilities of these LLMs and suggest directions for improving multilingual LLM performance and cross-lingual transfer.
Plain English Explanation
This research paper looks at how large language models, which are AI systems trained on massive amounts of text data, can recognize and separate different languages within their internal representations. The researchers developed a new way to measure how well a language model can distinguish between linguistic regions, which are groups of languages that share common features.
They applied this measurement to several state-of-the-art language models, including XLMR, mT5, and ByT5. These models are designed to handle multiple languages, but the researchers wanted to understand how well they actually encode the distinctions between those languages.
The findings from this study provide insight into the multilingual capabilities of these language models. This can help researchers and developers find ways to improve the performance of language models when working with diverse languages, and make it easier for them to transfer knowledge between languages, especially for languages that have fewer available training resources.
Technical Explanation
The paper introduces a novel metric called "Linguistic Region Dispersion" (LRD) to quantify the degree of linguistic separation in the internal representations of large language models (LLMs). LRD measures how well a model's embeddings cluster languages into distinct groups based on their linguistic similarities.
The researchers applied the LRD metric to analyze the multilingual encoding capabilities of several state-of-the-art LLMs, including XLMR, mT5, and ByT5. They found that these models exhibited varying degrees of linguistic region separation, with ByT5 showing the most well-defined language clusters.
The insights from this analysis suggest that LLMs can indeed learn to distinguish between linguistic regions during pre-training, but the extent to which they do so can vary across model architectures and training approaches. This has implications for improving multilingual LLM performance and enabling more effective cross-lingual transfer.
Critical Analysis
The paper provides a novel and interesting approach to quantifying the multilingual encoding capabilities of large language models. The LRD metric appears to be a useful tool for probing the internal representations of these models and understanding how they handle linguistic diversity.
However, the paper does not delve into the potential reasons why certain models, like ByT5, exhibit more well-defined linguistic regions compared to others. Exploring the architectural and training characteristics that contribute to these differences could yield valuable insights for designing more effective multilingual language models.
Additionally, the paper focuses on a limited set of LLMs and languages. Expanding the analysis to a broader range of models and language families could provide a more comprehensive understanding of the landscape of multilingual encoding in large language models.
Conclusion
This research paper presents a novel approach to analyzing the multilingual encoding capabilities of large language models. By introducing the Linguistic Region Dispersion (LRD) metric, the researchers were able to quantify the degree to which LLMs, such as XLMR, mT5, and ByT5, can distinguish between different linguistic regions in their internal representations.
The findings from this study offer valuable insights into the multilingual abilities of state-of-the-art language models, which can inform efforts to improve their performance and enable more effective cross-lingual transfer. As the field of natural language processing continues to advance, this type of research can help us better understand the underlying mechanisms that allow language models to handle linguistic diversity and pave the way for the development of more robust and versatile multilingual systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Probing the Emergence of Cross-lingual Alignment during LLM Training
Hetong Wang, Pasquale Minervini, Edoardo M. Ponti
0
0
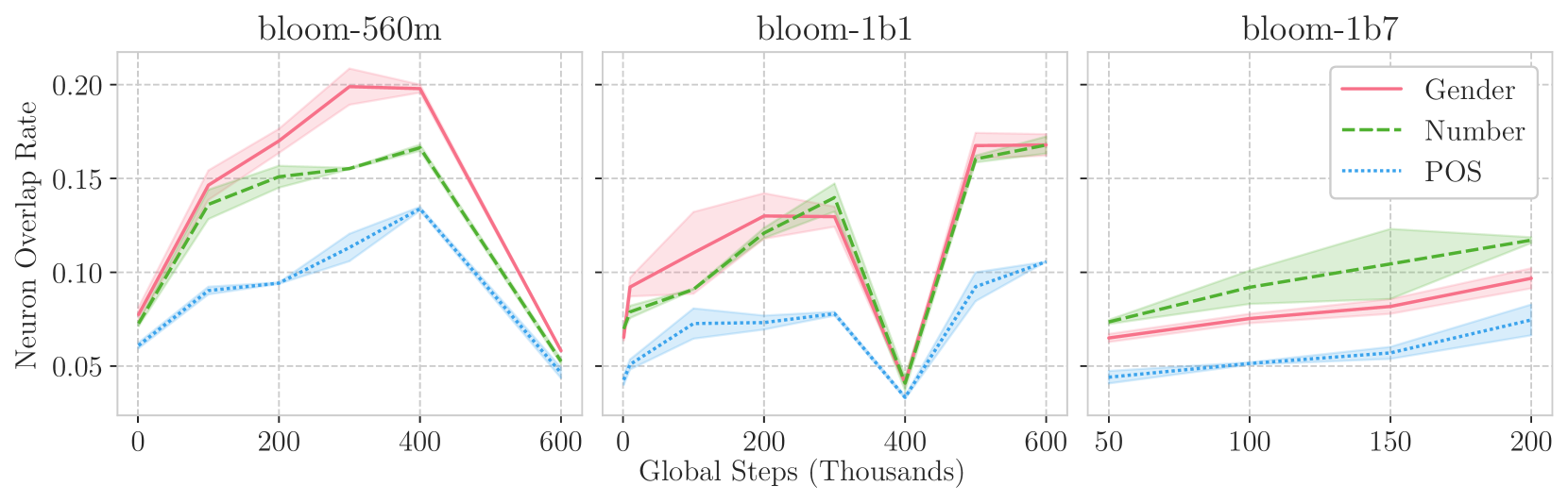
Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.
6/21/2024

Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
0
0
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
6/26/2024

Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Xin Zhao, Furu Wei, Ji-Rong Wen
0
0
Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on several representative LLMs, such as LLaMA-2, BLOOM, and Mistral. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to steer the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
6/7/2024
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
Yuemei Xu, Ling Hu, Jiayi Zhao, Zihan Qiu, Yuqi Ye, Hanwen Gu
0
0
Based on the foundation of Large Language Models (LLMs), Multilingual Large Language Models (MLLMs) have been developed to address the challenges of multilingual natural language processing tasks, hoping to achieve knowledge transfer from high-resource to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolution, key techniques, and multilingual capacities. Secondly, we explore widely utilized multilingual corpora for MLLMs' training and multilingual datasets oriented for downstream tasks that are crucial for enhancing the cross-lingual capability of MLLMs. Thirdly, we survey the existing studies on multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs including its category and evaluation metrics, and summarize the existing debiasing techniques. Finally, we discuss existing challenges and point out promising research directions. By demonstrating these aspects, this paper aims to facilitate a deeper understanding of MLLMs and their potentiality in various domains.
6/7/2024