LASER: Tuning-Free LLM-Driven Attention Control for Efficient Text-conditioned Image-to-Animation

0

Sign in to get full access
Overview
• This paper proposes a tuning-free, large language model (LLM)-driven attention control method called LASER for efficient text-conditioned image-to-animation generation.
• The method leverages the text-to-visual alignment capabilities of LLMs to guide the attention of a diffusion-based animation model, without the need for additional fine-tuning or prompt engineering.
• The approach demonstrates improved performance and efficiency compared to previous text-conditioned animation systems.
Plain English Explanation
• The researchers have developed a new way to create animated images from text descriptions, without the need for complex fine-tuning or prompt design.
• The key idea is to use a powerful large language model (LLM) to guide the attention of an animation-generating model, helping it focus on the relevant parts of the image based on the text input.
• This "tuning-free" approach, called LASER, allows for more efficient and effective text-to-animation generation compared to previous methods that required extensive customization.
• By leveraging the text-to-visual alignment capabilities of LLMs, the LASER system can generate animated images that closely match the provided text descriptions, without the need for laborious prompt engineering or model fine-tuning.
Technical Explanation
• The LASER method uses a diffusion-based animation model as the core generative component, which is guided by the attention mechanism of a pre-trained LLM.
• The LLM, such as CLIP or Stable Diffusion, is used to compute text-image similarity scores, which are then used to modulate the attention of the animation model.
• This attention control allows the diffusion model to focus on the relevant regions of the image based on the text input, without the need for additional fine-tuning or prompt engineering.
• The researchers demonstrate that the LASER approach outperforms previous text-conditioned animation systems in terms of both performance and efficiency, highlighting the benefits of leveraging pre-trained LLMs for this task.
Critical Analysis
• The paper acknowledges that the LASER method is currently limited to generating relatively simple animations, and further research is needed to extend it to more complex and diverse animation styles.
• Additionally, the authors note that the method's performance is still dependent on the quality and capabilities of the underlying LLM, which could potentially introduce biases or limitations.
• It would be interesting to see further investigation into the generalization capabilities of the LASER approach, as well as its robustness to different text prompts and animation domains.
Conclusion
• The LASER method presents a novel and efficient approach to text-conditioned image-to-animation generation, leveraging the power of pre-trained large language models to guide the attention of a diffusion-based animation model.
• This tuning-free approach demonstrates improved performance and efficiency compared to previous text-to-animation systems, and highlights the potential of combining powerful language models with generative animation models.
• While there are still some limitations and areas for further research, the LASER method represents an exciting step forward in the field of multimodal content generation, with potential applications in areas such as interactive storytelling, visual effects, and content creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LASER: Tuning-Free LLM-Driven Attention Control for Efficient Text-conditioned Image-to-Animation
Haoyu Zheng, Wenqiao Zhang, Yaoke Wang, Hao Zhou, Jiang Liu, Juncheng Li, Zheqi Lv, Siliang Tang, Yueting Zhuang
Revolutionary advancements in text-to-image models have unlocked new dimensions for sophisticated content creation, e.g., text-conditioned image editing, allowing us to edit the diverse images that convey highly complex visual concepts according to the textual guidance. Despite being promising, existing methods focus on texture- or non-rigid-based visual manipulation, which struggles to produce the fine-grained animation of smooth text-conditioned image morphing without fine-tuning, i.e., due to their highly unstructured latent space. In this paper, we introduce a tuning-free LLM-driven attention control framework, encapsulated by the progressive process of LLM planning, prompt-Aware editing, StablE animation geneRation, abbreviated as LASER. LASER employs a large language model (LLM) to refine coarse descriptions into detailed prompts, guiding pre-trained text-to-image models for subsequent image generation. We manipulate the model's spatial features and self-attention mechanisms to maintain animation integrity and enable seamless morphing directly from text prompts, eliminating the need for additional fine-tuning or annotations. Our meticulous control over spatial features and self-attention ensures structural consistency in the images. This paper presents a novel framework integrating LLMs with text-to-image models to create high-quality animations from a single text input. We also propose a Text-conditioned Image-to-Animation Benchmark to validate the effectiveness and efficacy of LASER. Extensive experiments demonstrate that LASER produces impressive, consistent, and efficient results in animation generation, positioning it as a powerful tool for advanced digital content creation.
Read more4/24/2024
0
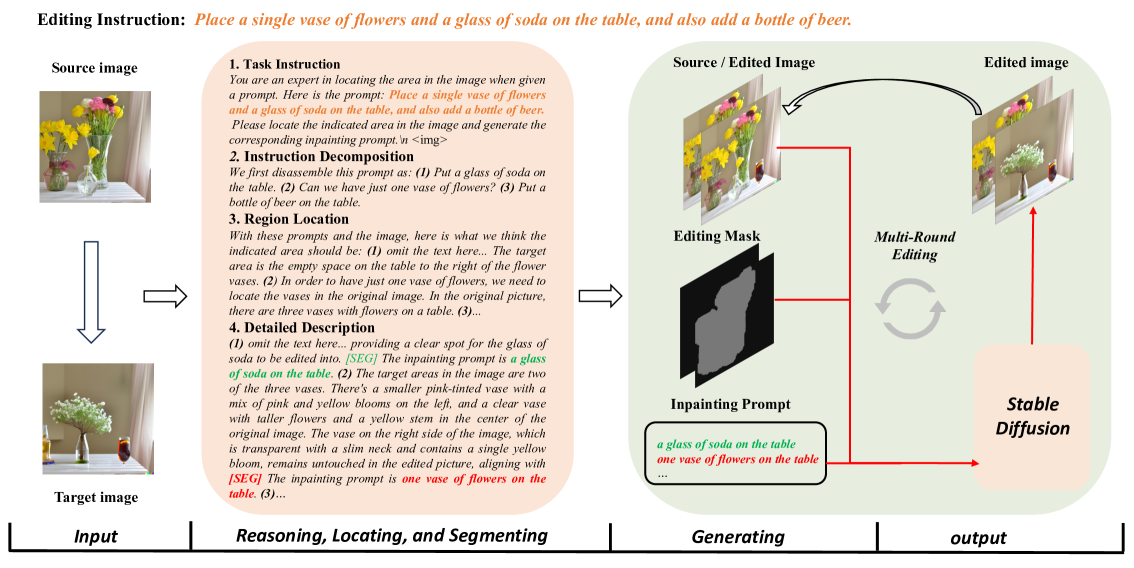
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
Read more5/28/2024

0
Zero-shot Text-guided Infinite Image Synthesis with LLM guidance
Soyeong Kwon, Taegyeong Lee, Taehwan Kim
Text-guided image editing and generation methods have diverse real-world applications. However, text-guided infinite image synthesis faces several challenges. First, there is a lack of text-image paired datasets with high-resolution and contextual diversity. Second, expanding images based on text requires global coherence and rich local context understanding. Previous studies have mainly focused on limited categories, such as natural landscapes, and also required to train on high-resolution images with paired text. To address these challenges, we propose a novel approach utilizing Large Language Models (LLMs) for both global coherence and local context understanding, without any high-resolution text-image paired training dataset. We train the diffusion model to expand an image conditioned on global and local captions generated from the LLM and visual feature. At the inference stage, given an image and a global caption, we use the LLM to generate a next local caption to expand the input image. Then, we expand the image using the global caption, generated local caption and the visual feature to consider global consistency and spatial local context. In experiments, our model outperforms the baselines both quantitatively and qualitatively. Furthermore, our model demonstrates the capability of text-guided arbitrary-sized image generation in zero-shot manner with LLM guidance.
Read more7/18/2024

0
Paying More Attention to Image: A Training-Free Method for Alleviating Hallucination in LVLMs
Shi Liu, Kecheng Zheng, Wei Chen
Existing Large Vision-Language Models (LVLMs) primarily align image features of vision encoder with Large Language Models (LLMs) to leverage their superior text generation capabilities. However, the scale disparity between vision encoder and language model may led to LLMs assuming a predominant role in multi-modal comprehension. This imbalance in LVLMs may result in the instances of hallucinatory. Concretely, LVLMs may generate consistent descriptions with or without visual input, indicating that certain outputs are influenced solely by context text. We refer to this phenomenon as text inertia. To counteract this issue, we introduce a training-free algorithm to find an equilibrium point between image comprehension and language inference. Specifically, we adaptively involve adjusting and amplifying the attention weights assigned to image tokens, thereby granting greater prominence to visual elements. Meanwhile, we subtract the logits of multi-modal inputs from ones of pure text input, which can help LVLMs be not biased towards LLMs. By enhancing images tokens and reducing the stubborn output of LLM, we can let LVLM pay more attention to images, towards alleviating text inertia and reducing the hallucination in LVLMs. Our extensive experiments shows that this method substantially reduces the frequency of hallucinatory outputs in various LVLMs in terms of different metrics. Project page is available at https://lalbj.github.io/projects/PAI/.
Read more8/1/2024