Learning More Generalized Experts by Merging Experts in Mixture-of-Experts

0

Sign in to get full access
Overview
- The paper introduces a novel approach to merging experts in a Mixture-of-Experts (MoE) model, which can lead to more generalized experts.
- The proposed method, called Soft Merging of Experts (SoME), allows the model to dynamically learn to merge or split experts during training, enabling it to adapt to the complexity of the task.
- The paper presents experimental results on various benchmark datasets, demonstrating the effectiveness of SoME in improving model performance and generalization compared to traditional MoE approaches.
Plain English Explanation
In machine learning, a Mixture-of-Experts (MoE) model is a type of neural network that consists of multiple "expert" sub-models, each specializing in a different part of the problem. The overall model then learns to route the input to the most appropriate expert based on the input's characteristics.
The paper introduces a new way to improve this MoE approach, called Soft Merging of Experts (SoME). The key idea is to allow the model to dynamically merge or split the expert sub-models during training, rather than keeping them fixed. This enables the model to adapt to the complexity of the task, potentially leading to more generalized and effective experts.
The paper demonstrates the effectiveness of SoME through experiments on various benchmark datasets, showing that it can improve the model's overall performance and generalization capabilities compared to traditional MoE approaches that keep the experts fixed.
Technical Explanation
The key technical contribution of the paper is the Soft Merging of Experts (SoME) approach, which extends the Mixture-of-Experts (MoE) framework. In a traditional MoE model, the expert sub-models are kept fixed during training, with the overall model learning to route the input to the most appropriate expert.
The paper evaluates SoME on various benchmark datasets, including language modeling and image classification tasks. The results demonstrate that SoME can outperform traditional MoE approaches in terms of both performance and generalization, particularly on more complex tasks.
Critical Analysis
The paper presents a promising approach to improving Mixture-of-Experts models, but there are a few potential areas for further research and consideration:
Despite these potential areas for improvement, the overall concept of Soft Merging of Experts represents a valuable contribution to the field of Mixture-of-Experts models, and the experimental results demonstrate its potential to enhance model performance and generalization.
Conclusion
The paper presents a novel approach called Soft Merging of Experts (SoME) that extends the Mixture-of-Experts (MoE) framework by allowing the expert sub-models to be dynamically merged or split during training. This adaptive expert structure enables the model to better match the complexity of the task, potentially leading to more generalized and effective experts.
The experimental results on various benchmark datasets show that SoME can outperform traditional MoE approaches in terms of both performance and generalization. This suggests that the ideas introduced in this paper could have a significant impact on the development of more powerful and versatile machine learning models, with applications across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning More Generalized Experts by Merging Experts in Mixture-of-Experts
Sejik Park
We observe that incorporating a shared layer in a mixture-of-experts can lead to performance degradation. This leads us to hypothesize that learning shared features poses challenges in deep learning, potentially caused by the same feature being learned as various different features. To address this issue, we track each expert's usage frequency and merge the two most frequently selected experts. We then update the least frequently selected expert using the combination of experts. This approach, combined with the subsequent learning of the router's expert selection, allows the model to determine if the most frequently selected experts have learned the same feature differently. If they have, the combined expert can be further trained to learn a more general feature. Consequently, our algorithm enhances transfer learning and mitigates catastrophic forgetting when applied to multi-domain task incremental learning.
Read more5/21/2024

0
Theory on Mixture-of-Experts in Continual Learning
Hongbo Li, Sen Lin, Lingjie Duan, Yingbin Liang, Ness B. Shroff
Continual learning (CL) has garnered significant attention because of its ability to adapt to new tasks that arrive over time. Catastrophic forgetting (of old tasks) has been identified as a major issue in CL, as the model adapts to new tasks. The Mixture-of-Experts (MoE) model has recently been shown to effectively mitigate catastrophic forgetting in CL, by employing a gating network to sparsify and distribute diverse tasks among multiple experts. However, there is a lack of theoretical analysis of MoE and its impact on the learning performance in CL. This paper provides the first theoretical results to characterize the impact of MoE in CL via the lens of overparameterized linear regression tasks. We establish the benefit of MoE over a single expert by proving that the MoE model can diversify its experts to specialize in different tasks, while its router learns to select the right expert for each task and balance the loads across all experts. Our study further suggests an intriguing fact that the MoE in CL needs to terminate the update of the gating network after sufficient training rounds to attain system convergence, which is not needed in the existing MoE studies that do not consider the continual task arrival. Furthermore, we provide explicit expressions for the expected forgetting and overall generalization error to characterize the benefit of MoE in the learning performance in CL. Interestingly, adding more experts requires additional rounds before convergence, which may not enhance the learning performance. Finally, we conduct experiments on both synthetic and real datasets to extend these insights from linear models to deep neural networks (DNNs), which also shed light on the practical algorithm design for MoE in CL.
Read more10/3/2024
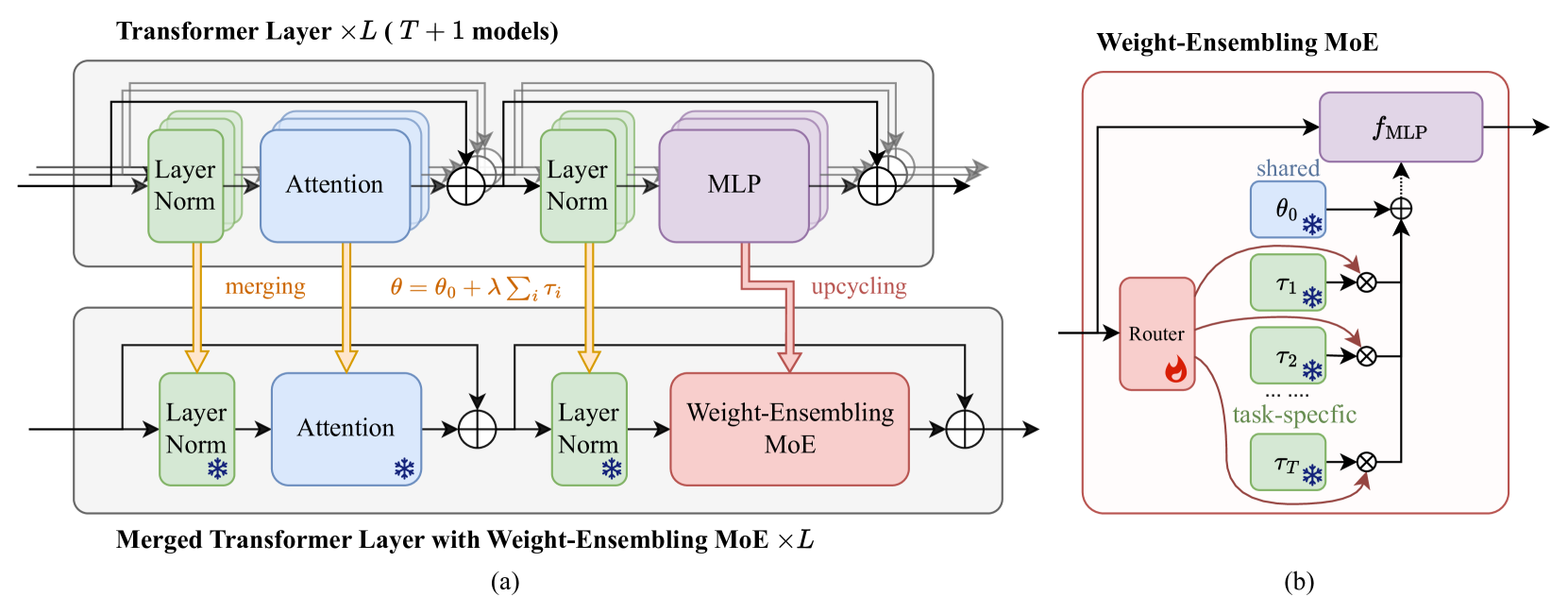
0
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
Read more6/10/2024

0
Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Zhenyi Lu, Chenghao Fan, Wei Wei, Xiaoye Qu, Dangyang Chen, Yu Cheng
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
Read more6/26/2024