Leftover Lunch: Advantage-based Offline Reinforcement Learning for Language Models
2305.14718
0
2
🏅
Abstract
Reinforcement Learning with Human Feedback (RLHF) is the most prominent method for Language Model (LM) alignment. However, RLHF is an unstable and data-hungry process that continually requires new high-quality LM-generated data for finetuning. We introduce Advantage-Leftover Lunch RL (A-LoL), a new class of offline policy gradient algorithms that enable RL training on any pre-existing data. By assuming the entire LM output sequence as a single action, A-LoL allows incorporating sequence-level classifiers or human-designed scoring functions as rewards. Subsequently, by using LM's value estimate, A-LoL only trains on positive advantage (leftover) data points, making it resilient to noise. Overall, A-LoL is an easy-to-implement, sample-efficient, and stable LM training recipe. We demonstrate the effectiveness of A-LoL and its variants with a set of four different language generation tasks. We compare against both online RL (PPO) and recent preference-based (DPO, PRO) and reward-based (GOLD) offline RL baselines. On the commonly-used RLHF benchmark, Helpful and Harmless Assistant (HHA), LMs trained with A-LoL methods achieve the highest diversity while also being rated more safe and helpful than the baselines according to humans. Additionally, in the remaining three tasks, A-LoL could optimize multiple distinct reward functions even when using noisy or suboptimal training data. We also release our experimental code. https://github.com/abaheti95/LoL-RL
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Reinforcement Learning with Human Feedback (RLHF) is a prominent method for aligning Language Models (LMs), but it is an unstable and data-hungry process.
- The paper introduces Advantage-Leftover Lunch RL (A-LoL), a new class of offline policy gradient algorithms that enable RL training on any pre-existing data.
- A-LoL assumes the entire LM output sequence as a single action, allowing it to incorporate sequence-level classifiers or human-designed scoring functions as rewards.
- A-LoL only trains on positive advantage (leftover) data points, making it resilient to noise.
Plain English Explanation
The paper introduces a new method called Advantage-Leftover Lunch RL (A-LoL) for training language models (LMs) to behave in a more desirable way. The current leading method, Reinforcement Learning with Human Feedback (RLHF), has some problems - it's unstable and requires a lot of high-quality data to work well.
A-LoL is designed to be more robust and efficient. It treats the entire output sequence from the LM as a single "action" and uses that to calculate a reward. This reward can come from a classifier that judges how good the output is, or from a scoring function designed by humans. Crucially, A-LoL only trains on the data points where the LM output is better than expected, making it less sensitive to noisy or suboptimal training data.
The researchers show that LMs trained with A-LoL methods perform well on several language generation tasks, including a benchmark called Helpful and Harmless Assistant (HHA). These models are rated as more safe and helpful by humans, while also being more diverse in their outputs.
Technical Explanation
The core idea behind Advantage-Leftover Lunch RL (A-LoL) is to enable reinforcement learning (RL) training of language models (LMs) on any pre-existing data, rather than requiring the continuous generation of new high-quality training data as in Reinforcement Learning with Human Feedback (RLHF).
A-LoL achieves this by treating the entire LM output sequence as a single "action" and using that to calculate a reward. This reward can come from a sequence-level classifier (e.g., a model that judges how safe, helpful, or informative the output is) or from a human-designed scoring function.
Crucially, A-LoL only trains on the "positive advantage" data points - those where the LM output is better than expected according to the reward function. This makes the training process more robust to noise or suboptimal rewards, as the model only learns from the best examples.
The researchers demonstrate the effectiveness of A-LoL and its variants on four different language generation tasks, including the commonly-used Helpful and Harmless Assistant (HHA) benchmark. Compared to both online RL methods like PPO and recent offline RL baselines like DPO, PRO, and GOLD, LMs trained with A-LoL achieve the highest diversity while also being rated as more safe and helpful by human evaluators.
Critical Analysis
The paper presents a novel and promising approach to aligning large language models through reinforcement learning. The key strengths of A-LoL are its sample efficiency, stability, and ability to work with any pre-existing data, which address some of the limitations of RLHF.
However, the paper does not delve deeply into the potential caveats or limitations of the A-LoL method. For example, it's unclear how well A-LoL would scale to extremely large language models or how sensitive it is to the choice of reward function. Additionally, the paper does not discuss potential biases or unintended behaviors that could arise from optimizing language models for specific scoring functions.
Further research would be needed to better understand the long-term implications and robustness of A-LoL. Exploring edge cases, investigating potential failure modes, and comparing A-LoL to other emerging approaches for language model alignment would help strengthen the critical analysis of this work.
Conclusion
The paper introduces Advantage-Leftover Lunch RL (A-LoL), a new class of offline policy gradient algorithms that enable efficient and stable reinforcement learning training of language models on pre-existing data. By treating the entire LM output sequence as a single action and only learning from positive advantage data points, A-LoL addresses some of the key limitations of the current Reinforcement Learning with Human Feedback (RLHF) approach.
The researchers demonstrate the effectiveness of A-LoL on several language generation tasks, including outperforming recent offline RL baselines on the Helpful and Harmless Assistant (HHA) benchmark. This work represents a promising step towards more sample-efficient and robust methods for aligning large language models with desired behaviors and traits.
However, further research is needed to fully understand the potential limitations and long-term implications of the A-LoL approach. Exploring edge cases, investigating potential biases, and comparing A-LoL to other emerging alignment techniques will be important to strengthen the critical analysis of this work and its real-world applicability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
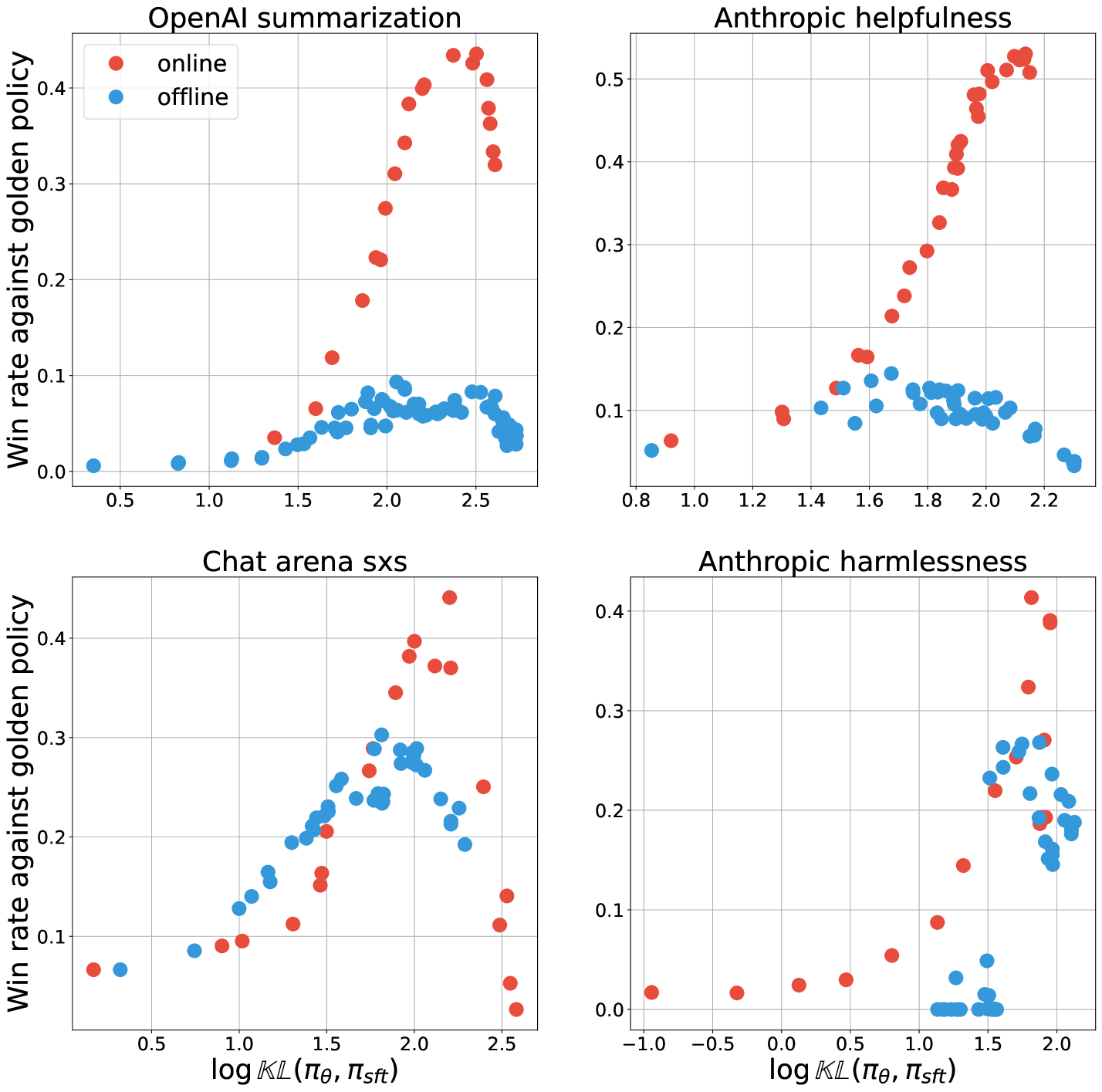
Understanding the performance gap between online and offline alignment algorithms
Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, R'emi Munos, Bernardo 'Avila Pires, Michal Valko, Yong Cheng, Will Dabney
0
0
Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.
5/15/2024
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024
🏅
New!ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
0
0
Reinforcement Learning from Human Feedback (RLHF) is key to aligning Large Language Models (LLMs), typically paired with the Proximal Policy Optimization (PPO) algorithm. While PPO is a powerful method designed for general reinforcement learning tasks, it is overly sophisticated for LLMs, leading to laborious hyper-parameter tuning and significant computation burdens. To make RLHF efficient, we present ReMax, which leverages 3 properties of RLHF: fast simulation, deterministic transitions, and trajectory-level rewards. These properties are not exploited in PPO, making it less suitable for RLHF. Building on the renowned REINFORCE algorithm, ReMax does not require training an additional value model as in PPO and is further enhanced with a new variance reduction technique. ReMax offers several benefits over PPO: it is simpler to implement, eliminates more than 4 hyper-parameters in PPO, reduces GPU memory usage, and shortens training time. ReMax can save about 46% GPU memory than PPO when training a 7B model and enables training on A800-80GB GPUs without the memory-saving offloading technique needed by PPO. Applying ReMax to a Mistral-7B model resulted in a 94.78% win rate on the AlpacaEval leaderboard and a 7.739 score on MT-bench, setting a new SOTA for open-source 7B models. These results show the effectiveness of ReMax while addressing the limitations of PPO in LLMs.
5/17/2024
🧠
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
0
0
We present the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF) in this technical report, which is widely reported to outperform its offline counterpart by a large margin in the recent large language model (LLM) literature. However, existing open-source RLHF projects are still largely confined to the offline learning setting. In this technical report, we aim to fill in this gap and provide a detailed recipe that is easy to reproduce for online iterative RLHF. In particular, since online human feedback is usually infeasible for open-source communities with limited resources, we start by constructing preference models using a diverse set of open-source datasets and use the constructed proxy preference model to approximate human feedback. Then, we discuss the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation. Our trained LLM, SFR-Iterative-DPO-LLaMA-3-8B-R, achieves impressive performance on LLM chatbot benchmarks, including AlpacaEval-2, Arena-Hard, and MT-Bench, as well as other academic benchmarks such as HumanEval and TruthfulQA. We have shown that supervised fine-tuning (SFT) and iterative RLHF can obtain state-of-the-art performance with fully open-source datasets. Further, we have made our models, curated datasets, and comprehensive step-by-step code guidebooks publicly available. Please refer to https://github.com/RLHFlow/RLHF-Reward-Modeling and https://github.com/RLHFlow/Online-RLHF for more detailed information.
5/14/2024