ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models

0
🏅
Sign in to get full access
Overview
- This paper presents ReMax, a new Reinforcement Learning from Human Feedback (RLHF) algorithm that is more efficient and effective than the commonly used Proximal Policy Optimization (PPO) algorithm for aligning Large Language Models (LLMs).
- The key insights are that RLHF has certain properties, such as fast simulation, deterministic transitions, and trajectory-level rewards, that are not well-exploited by PPO, making it suboptimal for this task.
- ReMax builds on the REINFORCE algorithm and introduces a new variance reduction technique to address the limitations of PPO.
Plain English Explanation
ReMax: A More Efficient RLHF Algorithm for Aligning Large Language Models
Training large language models (LLMs) to behave in alignment with human values and preferences is a critical challenge. One common approach is Reinforcement Learning from Human Feedback (RLHF), which uses human-provided rewards to fine-tune the model.
The Proximal Policy Optimization (PPO) algorithm is often used for RLHF, but it has some downsides. PPO is a powerful general-purpose reinforcement learning algorithm, but it's overly sophisticated for the specific requirements of RLHF. This leads to challenges like laborious hyperparameter tuning and high computational costs.
To address these limitations, the researchers developed a new algorithm called ReMax. ReMax takes advantage of three key properties of RLHF: fast simulation, deterministic transitions, and trajectory-level rewards. These properties are not well-exploited by PPO, making ReMax a more suitable choice.
ReMax builds on the REINFORCE algorithm and introduces a new variance reduction technique. This makes ReMax simpler to implement, reduces the number of hyperparameters, and reduces GPU memory usage and training time compared to PPO.
When applied to a 7-billion parameter LLM, ReMax achieved state-of-the-art performance on benchmark tasks, demonstrating its effectiveness in aligning LLMs through RLHF.
Technical Explanation
The paper presents ReMax, a new Reinforcement Learning from Human Feedback (RLHF) algorithm that is designed to be more efficient and effective than the commonly used Proximal Policy Optimization (PPO) algorithm for aligning Large Language Models (LLMs).
The key insights are that RLHF has several properties that are not well-exploited by PPO, including:
- Fast Simulation: RLHF can simulate the language model's behavior quickly, as it does not require complex environment dynamics.
- Deterministic Transitions: The transitions in RLHF are deterministic, as they are based on the language model's token-level predictions.
- Trajectory-Level Rewards: The rewards in RLHF are often given at the trajectory level, rather than at each step.
These properties make PPO, which is designed for general reinforcement learning tasks, suboptimal for RLHF. To address this, the researchers developed ReMax, which builds on the REINFORCE algorithm and introduces a new variance reduction technique.
ReMax eliminates the need for an additional value model, as required by PPO, and reduces the number of hyperparameters. This results in simpler implementation, lower GPU memory usage, and shorter training times compared to PPO.
The researchers evaluated ReMax on a 7-billion parameter LLM and found that it achieved state-of-the-art performance on benchmark tasks, setting a new SOTA for open-source 7B models. These results demonstrate the effectiveness of ReMax in addressing the limitations of PPO for RLHF in LLMs.
Critical Analysis
The paper presents a well-designed and thorough investigation of the limitations of PPO for RLHF in LLMs and the benefits of the proposed ReMax algorithm. The researchers have clearly identified the key properties of RLHF that are not well-exploited by PPO and have designed ReMax to address these shortcomings.
One potential area for further research could be exploring the generalization of ReMax to other types of reinforcement learning tasks beyond RLHF. While the paper focuses on the specific use case of aligning LLMs, the underlying insights and techniques may be applicable to a wider range of reinforcement learning problems.
Additionally, the paper could have provided more details on the specific hyperparameter tuning and computational costs associated with PPO and ReMax, as well as a more comprehensive comparison of the training and evaluation times for the two algorithms. This information would help readers better understand the practical benefits of using ReMax over PPO.
Overall, the paper presents a compelling and well-executed study that advances the state-of-the-art in RLHF for LLMs. The ReMax algorithm offers a promising alternative to PPO and is likely to be of significant interest to researchers and practitioners working in this field.
Conclusion
The ReMax algorithm presented in this paper offers a more efficient and effective approach to Reinforcement Learning from Human Feedback (RLHF) for aligning Large Language Models (LLMs). By leveraging the unique properties of RLHF, such as fast simulation, deterministic transitions, and trajectory-level rewards, ReMax outperforms the commonly used Proximal Policy Optimization (PPO) algorithm in terms of simplicity, hyperparameter reduction, GPU memory usage, and training time.
The researchers have demonstrated the effectiveness of ReMax by applying it to a 7-billion parameter LLM and achieving state-of-the-art performance on benchmark tasks. These results highlight the potential of ReMax to advance the field of RLHF and contribute to the development of more aligned and capable LLMs.
The insights and techniques presented in this paper may also have broader applications beyond the specific domain of RLHF, and could be valuable for researchers and practitioners working on a wide range of reinforcement learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
Reinforcement Learning from Human Feedback (RLHF) is key to aligning Large Language Models (LLMs), typically paired with the Proximal Policy Optimization (PPO) algorithm. While PPO is a powerful method designed for general reinforcement learning tasks, it is overly sophisticated for LLMs, leading to laborious hyper-parameter tuning and significant computation burdens. To make RLHF efficient, we present ReMax, which leverages 3 properties of RLHF: fast simulation, deterministic transitions, and trajectory-level rewards. These properties are not exploited in PPO, making it less suitable for RLHF. Building on the renowned REINFORCE algorithm, ReMax does not require training an additional value model as in PPO and is further enhanced with a new variance reduction technique. ReMax offers several benefits over PPO: it is simpler to implement, eliminates more than 4 hyper-parameters in PPO, reduces GPU memory usage, and shortens training time. ReMax can save about 46% GPU memory than PPO when training a 7B model and enables training on A800-80GB GPUs without the memory-saving offloading technique needed by PPO. Applying ReMax to a Mistral-7B model resulted in a 94.78% win rate on the AlpacaEval leaderboard and a 7.739 score on MT-bench, setting a new SOTA for open-source 7B models. These results show the effectiveness of ReMax while addressing the limitations of PPO in LLMs.
Read more5/17/2024

0
An Extremely Data-efficient and Generative LLM-based Reinforcement Learning Agent for Recommenders
Shuang Feng, Grace Feng
Recent advancements in large language models (LLMs) have enabled understanding webpage contexts, product details, and human instructions. Utilizing LLMs as the foundational architecture for either reward models or policies in reinforcement learning has gained popularity -- a notable achievement is the success of InstructGPT. RL algorithms have been instrumental in maximizing long-term customer satisfaction and avoiding short-term, myopic goals in industrial recommender systems, which often rely on deep learning models to predict immediate clicks or purchases. In this project, several RL methods are implemented and evaluated using the WebShop benchmark environment, data, simulator, and pre-trained model checkpoints. The goal is to train an RL agent to maximize the purchase reward given a detailed human instruction describing a desired product. The RL agents are developed by fine-tuning a pre-trained BERT model with various objectives, learning from preferences without a reward model, and employing contemporary training techniques such as Proximal Policy Optimization (PPO) as used in InstructGPT, and Direct Preference Optimization (DPO). This report also evaluates the RL agents trained using generative trajectories. Evaluations were conducted using Thompson sampling in the WebShop simulator environment. The simulated online experiments demonstrate that agents trained on generated trajectories exhibited comparable task performance to those trained using human trajectories. This has demonstrated an example of an extremely low-cost data-efficient way of training reinforcement learning agents. Also, with limited training time (<2hours), without utilizing any images, a DPO agent achieved a 19% success rate after approximately 3000 steps or 30 minutes of training on T4 GPUs, compared to a PPO agent, which reached a 15% success rate.
Read more8/30/2024
🏅
0
Reinforcement Learning without Human Feedback for Last Mile Fine-Tuning of Large Language Models
Alec Solway
Reinforcement learning is used to align language models with human preference signals after first pre-training the model to predict the next token of text within a large corpus using likelihood maximization. Before being deployed in a specific domain, models are often further fine-tuned on task specific data. Since human preferences are often unavailable for the last step, it is performed using likelihood maximization as that is the typical default method. However, reinforcement learning has other advantages besides facilitating alignment to a human derived reward function. For one, whereas likelihood maximization is a form of imitation learning in which the model is trained on what to do under ideal conditions, reinforcement learning is not limited to demonstrating actions just for optimally reached states and trains a model what to do under a range of scenarios as it explores the policy space. In addition, it also trains a model what not to do, suppressing competitive but poor actions. This work develops a framework for last-mile fine-tuning using reinforcement learning and tests whether it garners performance gains. The experiments center on abstractive summarization, but the framework is general and broadly applicable. Use of the procedure produced significantly better results than likelihood maximization when comparing raw predictions. For the specific data tested, the gap could be bridged by employing post-processing of the maximum likelihood outputs. Nonetheless, the framework offers a new avenue for model optimization in situations where post-processing may be less straightforward or effective, and it can be extended to include more complex classes of undesirable outputs to penalize and train against, such as hallucinations.
Read more8/30/2024
0
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
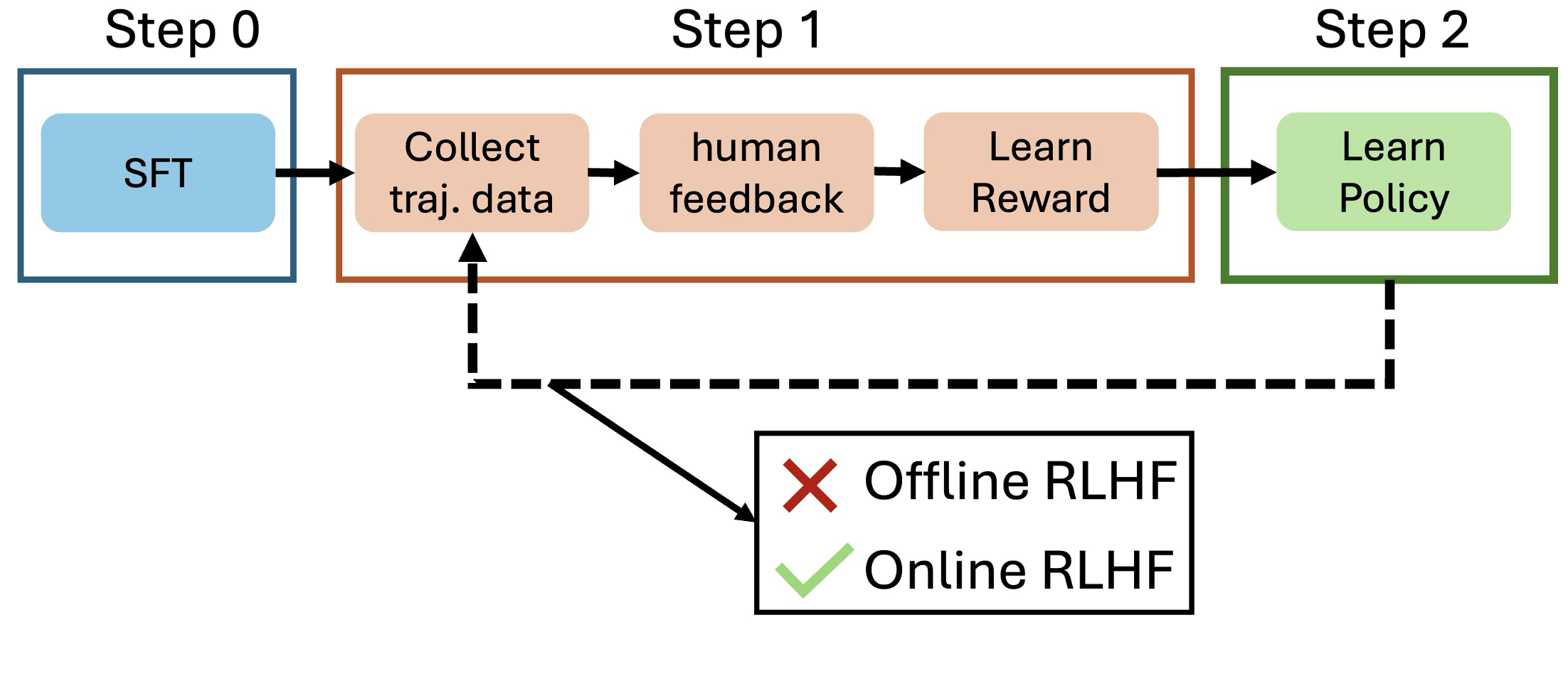
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
Read more6/26/2024