Leveraging LLMs for Unsupervised Dense Retriever Ranking

0
🤷
Sign in to get full access
Overview
- Presents a new method called LARMOR (Large Language Model Assisted Retrieval Model Ranking) for selecting effective pre-trained dense retrieval models
- LARMOR leverages large language models (LLMs) to generate pseudo-relevant queries, labels, and reference lists from a target corpus
- Allows selecting the most effective pre-trained dense retriever for the target corpus, even in zero-shot scenarios with domain shift
Plain English Explanation
Information retrieval (IR) systems often rely on "dense retrievers" - machine learning models trained to encode documents in a way that similar documents are close together. These dense retrievers are usually trained on large, public datasets. However, when using these dense retrievers on a new, private target corpus, their performance can drop significantly if the target corpus is in a different domain or covers different topics than the training data (a phenomenon known as "domain shift").
LARMOR aims to solve this problem by using large language models (LLMs) to generate pseudo-relevant signals (queries, labels, and reference lists) based on a sample of documents from the target corpus. These signals are then used to evaluate and rank a pool of pre-trained dense retrievers, allowing the selection of the most effective one for the target corpus, even in zero-shot scenarios where no labeled data is available.
The key innovation is that LARMOR requires no labeled data from the target corpus or training corpora - it relies solely on the target corpus itself to choose the best dense retriever. This makes it a powerful tool for deploying IR systems in new domains where labeled data may be scarce or unavailable.
Technical Explanation
The LARMOR approach works as follows:
- A set of documents is sampled from the target corpus.
- The LLM is used to generate pseudo-relevant queries, labels, and reference lists based on the sampled documents.
- A pool of state-of-the-art pre-trained dense retrievers is then evaluated and ranked based on their performance on the generated pseudo-relevant signals.
- The highest-ranked dense retriever is selected to be used on the full target corpus.
The authors construct a large pool of dense retrievers, including models from leading techniques like DocT5Query, Passage Retrieval with LLMs, and Personalization of LLMs. They show that LARMOR outperforms existing baselines for dense retriever selection and ranking, without requiring any labeled data from the target corpus or training corpora.
Critical Analysis
The LARMOR approach addresses an important challenge in information retrieval - how to effectively use dense retrievers on new, unlabeled target corpora that may differ from the data the retrievers were trained on. The authors' use of LLMs to generate pseudo-relevant signals is a clever solution to this problem.
However, the paper does not discuss potential limitations or caveats of the approach. For example, the quality and relevance of the pseudo-signals generated by the LLM could impact the accuracy of the dense retriever rankings. Additionally, the approach assumes that a sample of the target corpus is available, which may not always be the case in real-world scenarios.
Further research could explore ways to address these potential issues, such as techniques for improving the pseudo-signal generation or methods for dense retriever selection without any access to the target corpus. Additionally, it would be valuable to see the LARMOR approach evaluated on a wider range of target corpora and IR tasks to understand its broader applicability and limitations.
Conclusion
The LARMOR method presented in this paper offers a novel and effective solution for selecting the most appropriate pre-trained dense retrieval model when working with a new, unlabeled target corpus. By leveraging large language models to generate pseudo-relevant signals, LARMOR can effectively rank dense retrievers without requiring any labeled data from the target corpus or training corpora.
This capability could be transformative for many information retrieval applications, enabling the deployment of high-performing IR systems in new domains where labeled data is scarce or unavailable. As research in LLM-augmented retrieval and structured database retrieval continues to advance, LARMOR represents an important step forward in bridging the gap between pre-trained models and domain-specific IR needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Leveraging LLMs for Unsupervised Dense Retriever Ranking
Ekaterina Khramtsova, Shengyao Zhuang, Mahsa Baktashmotlagh, Guido Zuccon
In this paper we present Large Language Model Assisted Retrieval Model Ranking (LARMOR), an effective unsupervised approach that leverages LLMs for selecting which dense retriever to use on a test corpus (target). Dense retriever selection is crucial for many IR applications that rely on using dense retrievers trained on public corpora to encode or search a new, private target corpus. This is because when confronted with domain shift, where the downstream corpora, domains, or tasks of the target corpus differ from the domain/task the dense retriever was trained on, its performance often drops. Furthermore, when the target corpus is unlabeled, e.g., in a zero-shot scenario, the direct evaluation of the model on the target corpus becomes unfeasible. Unsupervised selection of the most effective pre-trained dense retriever becomes then a crucial challenge. Current methods for dense retriever selection are insufficient in handling scenarios with domain shift. Our proposed solution leverages LLMs to generate pseudo-relevant queries, labels and reference lists based on a set of documents sampled from the target corpus. Dense retrievers are then ranked based on their effectiveness on these generated pseudo-relevant signals. Notably, our method is the first approach that relies solely on the target corpus, eliminating the need for both training corpora and test labels. To evaluate the effectiveness of our method, we construct a large pool of state-of-the-art dense retrievers. The proposed approach outperforms existing baselines with respect to both dense retriever selection and ranking. We make our code and results publicly available at https://github.com/ielab/larmor/.
Read more5/24/2024
0
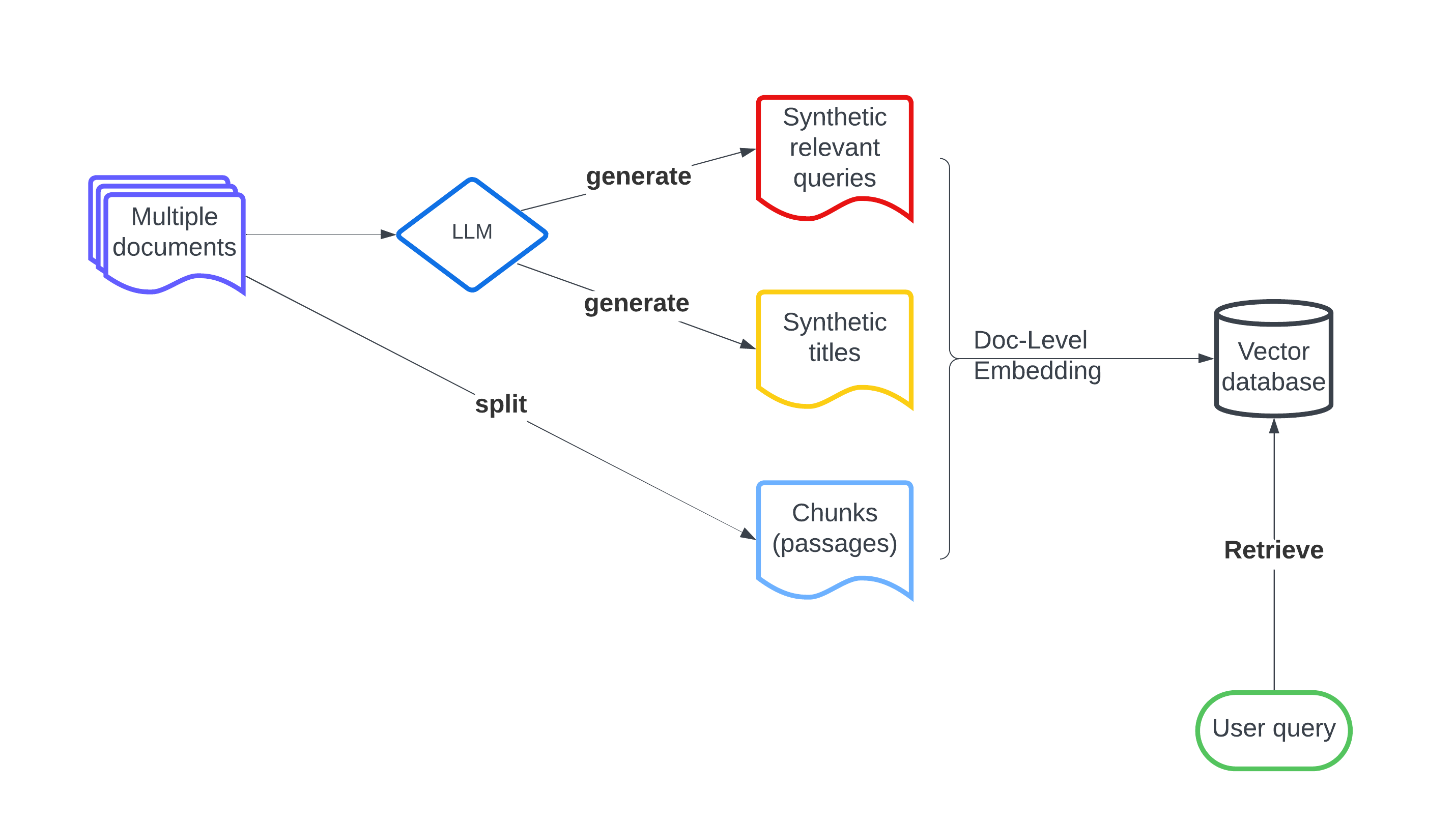
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Read more4/10/2024

0
ARL2: Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
Lingxi Zhang, Yue Yu, Kuan Wang, Chao Zhang
Retrieval-augmented generation enhances large language models (LLMs) by incorporating relevant information from external knowledge sources. This enables LLMs to adapt to specific domains and mitigate hallucinations in knowledge-intensive tasks. However, existing retrievers are often misaligned with LLMs due to their separate training processes and the black-box nature of LLMs. To address this challenge, we propose ARL2, a retriever learning technique that harnesses LLMs as labelers. ARL2 leverages LLMs to annotate and score relevant evidence, enabling learning the retriever from robust LLM supervision. Furthermore, ARL2 uses an adaptive self-training strategy for curating high-quality and diverse relevance data, which can effectively reduce the annotation cost. Extensive experiments demonstrate the effectiveness of ARL2, achieving accuracy improvements of 5.4% on NQ and 4.6% on MMLU compared to the state-of-the-art methods. Additionally, ARL2 exhibits robust transfer learning capabilities and strong zero-shot generalization abilities. Our code will be published at url{https://github.com/zhanglingxi-cs/ARL2}.
Read more6/5/2024

0
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
Kun Luo, Minghao Qin, Zheng Liu, Shitao Xiao, Jun Zhao, Kang Liu
Pretrained language models like BERT and T5 serve as crucial backbone encoders for dense retrieval. However, these models often exhibit limited generalization capabilities and face challenges in improving in domain accuracy. Recent research has explored using large language models (LLMs) as retrievers, achieving SOTA performance across various tasks. Despite these advancements, the specific benefits of LLMs over traditional retrievers and the impact of different LLM configurations, such as parameter sizes, pretraining duration, and alignment processes on retrieval tasks remain unclear. In this work, we conduct a comprehensive empirical study on a wide range of retrieval tasks, including in domain accuracy, data efficiency, zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. We evaluate over 15 different backbone LLMs and non LLMs. Our findings reveal that larger models and extensive pretraining consistently enhance in domain accuracy and data efficiency. Additionally, larger models demonstrate significant potential in zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. These results underscore the advantages of LLMs as versatile and effective backbone encoders in dense retrieval, providing valuable insights for future research and development in this field.
Read more8/26/2024