LLM-Generated Natural Language Meets Scaling Laws: New Explorations and Data Augmentation Methods

0
🌿
Sign in to get full access
Overview
- Explores challenges in natural language processing with large language models (LLMs)
- Proposes a method to assess the alignment between LLM-generated natural language (LLMNL) and human natural language (HNL)
- Introduces a novel data augmentation technique for few-shot text classification
Plain English Explanation
As large language models (LLMs) have become more advanced, natural language processing has seen significant improvements, including the use of LLM-based data augmentation. However, previous research has raised two main concerns:
-
It's unclear whether the natural language generated by LLMs (LLMNL) truly aligns with human natural language (HNL), which is a critical foundational question.
-
Augmented data generated by LLMs is often random, meaning that not all of the data may be equally useful for training classifiers, which could impede their performance.
To address these challenges, the researchers introduce a way to calculate and compare the intrinsic properties of LLMNL and HNL using scaling laws. Through extensive experiments, they find that LLMNL deviates slightly (around 0.2 Mandelbrot exponent) from Mandelbrot's law, and that HNL has a higher level of complexity. This provides a solid foundation for understanding LLMs' capabilities and limitations.
Furthermore, the researchers propose a novel data augmentation method for few-shot text classification, called ZGPTDA. ZGPTDA uses fuzzy computing mechanisms based on the scaling laws to make decisions about which GPT-4-generated data to include in the training process. Extensive testing in real-world scenarios confirms that ZGPTDA is effective, improving the F1 score of BERT and RoBERTa by 7-10%, and outperforming recent methods like AugGPT and GENCO by about 2% accuracy on DeBERTa.
The researchers also uncover some interesting insights, such as how Hilberg's law and Taylor's law can provide further benefits for text classification.
Technical Explanation
The researchers introduce a framework to intrinsically calculate and compare the properties of LLMNL and HNL using scaling laws. Through extensive experiments, they find that LLMNL deviates slightly (around 0.2 Mandelbrot exponent) from Mandelbrot's law, which describes the fractal nature of natural language. In contrast, HNL exhibits a higher level of complexity, suggesting a more sophisticated structure.
Building on these insights, the researchers propose a novel data augmentation method for few-shot text classification, called ZGPTDA. ZGPTDA leverages fuzzy computing mechanisms driven by the conformity to scaling laws to make decisions about which GPT-4-generated data to include in the training process. This approach aims to ensure that the augmented data is more closely aligned with the natural language patterns observed in the original training data.
Extensive experiments conducted in real-world scenarios confirm the effectiveness of ZGPTDA, with improvements of 7-10% in F1 score for BERT and RoBERTa, and a 2% accuracy advantage over recent methods like AugGPT and GENCO on DeBERTa. The researchers also uncover additional insights, such as the potential benefits of incorporating Hilberg's law and Taylor's law into text classification tasks.
Critical Analysis
The researchers have made a significant contribution by addressing the foundational question of whether LLMNL truly aligns with HNL, and by proposing a novel data augmentation method that leverages scaling laws to improve the effectiveness of text classification models.
However, the paper does not delve into the potential limitations of the scaling laws approach or the ZGPTDA method. It would be helpful to understand the specific scenarios or types of datasets where the proposed techniques may not perform as well, as well as any potential biases or issues that could arise from the use of GPT-4-generated data.
Additionally, the researchers mention insights related to Hilberg's law and Taylor's law, but do not provide a detailed explanation or exploration of how these laws can be leveraged for text classification tasks. Further research in this direction could expand the practical applications of the proposed methods.
Overall, the paper presents a solid foundation for understanding the relationship between LLMNL and HNL, and offers a promising approach for enhancing the performance of text classification models through data augmentation and the use of scaling laws.
Conclusion
This research tackles two critical challenges in natural language processing with large language models: the lack of understanding about the alignment between LLMNL and HNL, and the limitations of randomly generated augmented data for training classifiers.
By introducing a framework to intrinsically calculate and compare the properties of LLMNL and HNL using scaling laws, the researchers have established a solid foundation for understanding the capabilities and limitations of LLMs. Furthermore, the ZGPTDA data augmentation method they propose leverages this understanding to improve the effectiveness of few-shot text classification, outperforming recent approaches.
The insights gained from this research have the potential to drive further advancements in natural language processing, language model evaluation, and the development of more robust and reliable text classification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
LLM-Generated Natural Language Meets Scaling Laws: New Explorations and Data Augmentation Methods
Zhenhua Wang, Guang Xu, Ming Ren
With the ascent of large language models (LLM), natural language processing has witnessed enhancements, such as LLM-based data augmentation. Nonetheless, prior research harbors two primary concerns: firstly, a lack of contemplation regarding whether the natural language generated by LLM (LLMNL) truly aligns with human natural language (HNL), a critical foundational question; secondly, an oversight that augmented data is randomly generated by LLM, implying that not all data may possess equal training value, that could impede the performance of classifiers. To address these challenges, we introduce the scaling laws to intrinsically calculate LLMNL and HNL. Through extensive experiments, we reveal slight deviations (approximately 0.2 Mandelbrot exponent) from Mandelbrot's law in LLMNL, underscore a complexity advantage in HNL, and supplement an interpretive discussion on language style. This establishes a solid foundation for LLM's expansion. Further, we introduce a novel data augmentation method for few-shot text classification, termed ZGPTDA, which leverages fuzzy computing mechanisms driven by the conformity to scaling laws to make decisions about GPT-4 augmented data. Extensive experiments, conducted in real-world scenarios, confirms the effectiveness (improving F1 of Bert and RoBerta by 7-10%) and competitiveness (surpassing recent AugGPT and GENCO methods by about 2% accuracy on DeBerta) of ZGPTDA. In addition, we reveal some interesting insights, e.g., Hilberg's law and Taylor's law can impart more benefits to text classification, etc.
Read more7/2/2024
0
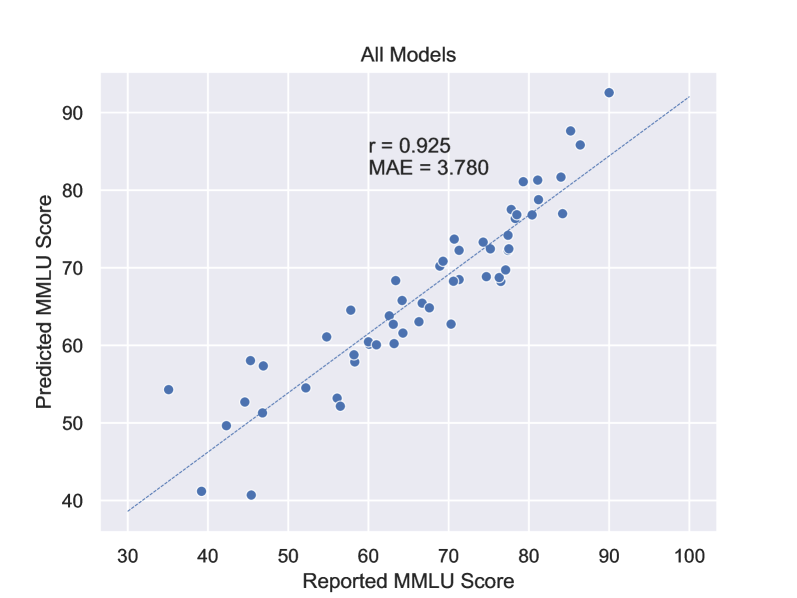
Performance Law of Large Language Models
Chuhan Wu, Ruiming Tang
Guided by the belief of the scaling law, large language models (LLMs) have achieved impressive performance in recent years. However, scaling law only gives a qualitative estimation of loss, which is influenced by various factors such as model architectures, data distributions, tokenizers, and computation precision. Thus, estimating the real performance of LLMs with different training settings rather than loss may be quite useful in practical development. In this article, we present an empirical equation named Performance Law to directly predict the MMLU score of an LLM, which is a widely used metric to indicate the general capability of LLMs in real-world conversations and applications. Based on only a few key hyperparameters of the LLM architecture and the size of training data, we obtain a quite accurate MMLU prediction of various LLMs with diverse sizes and architectures developed by different organizations in different years. Performance law can be used to guide the choice of LLM architecture and the effective allocation of computational resources without extensive experiments.
Read more9/16/2024
0
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Read more4/30/2024

0
LLMs learn governing principles of dynamical systems, revealing an in-context neural scaling law
Toni J. B. Liu, Nicolas Boull'e, Raphael Sarfati, Christopher J. Earls
Pretrained large language models (LLMs) are surprisingly effective at performing zero-shot tasks, including time-series forecasting. However, understanding the mechanisms behind such capabilities remains highly challenging due to the complexity of the models. We study LLMs' ability to extrapolate the behavior of dynamical systems whose evolution is governed by principles of physical interest. Our results show that LLaMA 2, a language model trained primarily on texts, achieves accurate predictions of dynamical system time series without fine-tuning or prompt engineering. Moreover, the accuracy of the learned physical rules increases with the length of the input context window, revealing an in-context version of neural scaling law. Along the way, we present a flexible and efficient algorithm for extracting probability density functions of multi-digit numbers directly from LLMs.
Read more6/24/2024