Performance Law of Large Language Models

0
Sign in to get full access
Overview
- The paper proposes a performance law that describes the relationship between the size of large language models and their performance on various tasks.
- The researchers found that model performance scales predictably with the size of the model, allowing for accurate performance forecasting.
- The law has important implications for the development and deployment of large language models in real-world applications.
Plain English Explanation
The performance law of large language models explains how the size of these powerful AI systems, which are trained on vast amounts of text data, is directly linked to their capabilities. The researchers discovered that as you make the models bigger and more complex, their performance on different tasks improves in a predictable way.
This means that if you know the size of a language model, you can fairly accurately predict how well it will perform on things like answering questions, summarizing text, or generating human-like writing. The larger the model, the better its performance tends to be.
This scaling relationship allows researchers and companies to plan the development of these models more effectively. They can forecast how much better a model will perform if they invest in making it larger and more powerful. This helps guide decisions about how to allocate resources and how to set realistic expectations for what these models can achieve.
Technical Explanation
The paper presents a performance law that describes the scaling of large language model capabilities with model size. The researchers analyzed performance data from a wide range of language models of varying sizes and found that performance scales as a power law with model size.
Specifically, they show that model performance P on a given task scales as P ∝ Nβ, where N is the model size (e.g., number of parameters) and β is an exponent that depends on the task. This allows accurate forecasting of how performance will improve as models grow larger.
The scaling exponents were found to be consistent across a diverse set of language understanding and generation tasks, suggesting fundamental underlying principles governing the scaling of these models.
Critical Analysis
The paper provides a rigorous empirical analysis and a compelling theoretical framework for understanding the performance scaling of large language models. However, the scaling law may have limitations:
- The analysis is based on current large language models, and the scaling relationship may break down as models grow orders of magnitude larger in the future.
- The scaling exponents could vary depending on the specific model architecture, training dataset, and other factors not fully explored in this work.
- The scaling law does not account for diminishing returns or other complexities that may emerge as models become extremely large and powerful.
Nonetheless, the performance law presented in this paper is a significant step forward in our understanding of large language models and can help guide their continued development and application.
Conclusion
This paper makes an important contribution by revealing a fundamental performance law that governs the scaling of large language models. The predictable relationship between model size and capability allows for more strategic planning and realistic expectations around the development of these powerful AI systems.
As language models continue to grow in scale and complexity, this scaling law will be crucial for researchers, engineers, and policymakers to understand the capabilities and limitations of these technologies. The insights from this work can help unlock the full potential of large language models while also informing responsible deployment and oversight.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Performance Law of Large Language Models
Chuhan Wu, Ruiming Tang
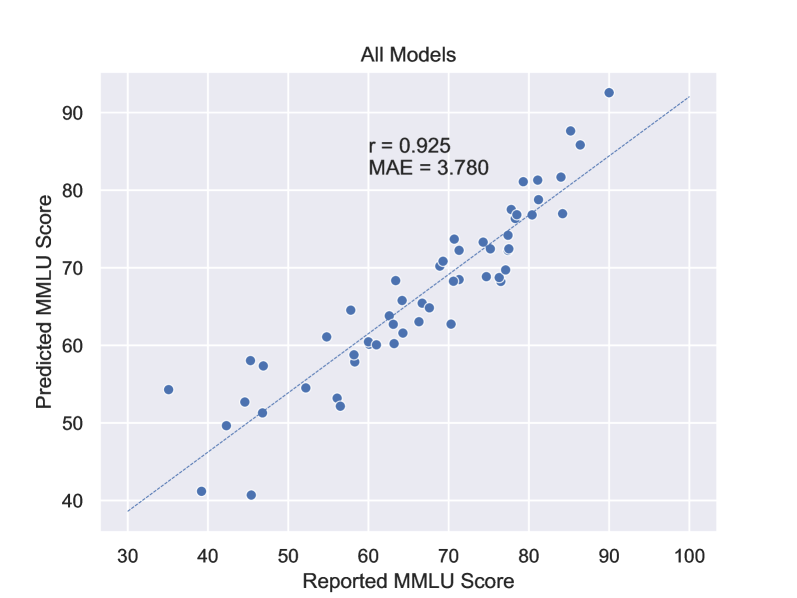
Guided by the belief of the scaling law, large language models (LLMs) have achieved impressive performance in recent years. However, scaling law only gives a qualitative estimation of loss, which is influenced by various factors such as model architectures, data distributions, tokenizers, and computation precision. Thus, estimating the real performance of LLMs with different training settings rather than loss may be quite useful in practical development. In this article, we present an empirical equation named Performance Law to directly predict the MMLU score of an LLM, which is a widely used metric to indicate the general capability of LLMs in real-world conversations and applications. Based on only a few key hyperparameters of the LLM architecture and the size of training data, we obtain a quite accurate MMLU prediction of various LLMs with diverse sizes and architectures developed by different organizations in different years. Performance law can be used to guide the choice of LLM architecture and the effective allocation of computational resources without extensive experiments.
Read more9/16/2024
0
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
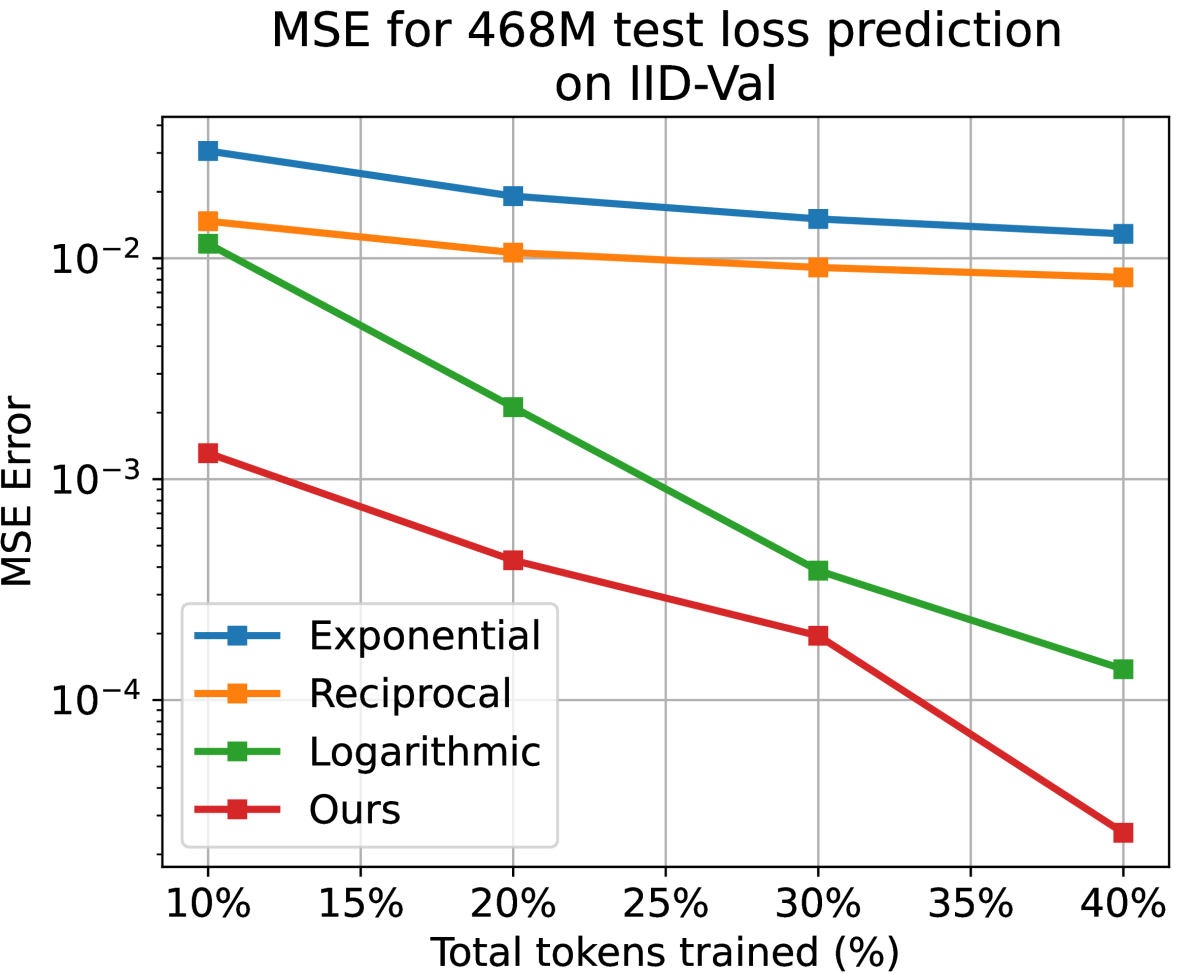
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
Read more6/18/2024

0
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt
Scaling laws are useful guides for derisking expensive training runs, as they predict performance of large models using cheaper, small-scale experiments. However, there remain gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., Chinchilla optimal regime). In contrast, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but models are usually compared on downstream task performance. To address both shortcomings, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we fit scaling laws that extrapolate in both the amount of over-training and the number of model parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$times$ over-trained) and a 6.9B parameter, 138B token run (i.e., a compute-optimal run)$unicode{x2014}$each from experiments that take 300$times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance by proposing a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models, using experiments that take 20$times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Read more6/18/2024
🌿
0
LLM-Generated Natural Language Meets Scaling Laws: New Explorations and Data Augmentation Methods
Zhenhua Wang, Guang Xu, Ming Ren
With the ascent of large language models (LLM), natural language processing has witnessed enhancements, such as LLM-based data augmentation. Nonetheless, prior research harbors two primary concerns: firstly, a lack of contemplation regarding whether the natural language generated by LLM (LLMNL) truly aligns with human natural language (HNL), a critical foundational question; secondly, an oversight that augmented data is randomly generated by LLM, implying that not all data may possess equal training value, that could impede the performance of classifiers. To address these challenges, we introduce the scaling laws to intrinsically calculate LLMNL and HNL. Through extensive experiments, we reveal slight deviations (approximately 0.2 Mandelbrot exponent) from Mandelbrot's law in LLMNL, underscore a complexity advantage in HNL, and supplement an interpretive discussion on language style. This establishes a solid foundation for LLM's expansion. Further, we introduce a novel data augmentation method for few-shot text classification, termed ZGPTDA, which leverages fuzzy computing mechanisms driven by the conformity to scaling laws to make decisions about GPT-4 augmented data. Extensive experiments, conducted in real-world scenarios, confirms the effectiveness (improving F1 of Bert and RoBerta by 7-10%) and competitiveness (surpassing recent AugGPT and GENCO methods by about 2% accuracy on DeBerta) of ZGPTDA. In addition, we reveal some interesting insights, e.g., Hilberg's law and Taylor's law can impart more benefits to text classification, etc.
Read more7/2/2024