Long-Tail Learning with Rebalanced Contrastive Loss

0

Sign in to get full access
Overview
- This paper proposes a new approach for "long-tail learning" - the challenge of effectively training machine learning models on datasets with highly imbalanced class distributions.
- The key idea is to use a "rebalanced contrastive loss" that encourages the model to learn better representations for the rare/minority classes without neglecting the more common classes.
- The authors compare their approach to several baselines and demonstrate improved performance on long-tailed classification benchmarks.
Plain English Explanation
In machine learning, datasets often have some classes (categories) that are much more common than others. For example, a dataset of images might have many pictures of dogs but only a few pictures of rare animals like platypuses.
The paper "Exploring Contrastive Learning for Long-Tailed Multi-Label Classification" showed that standard training methods tend to focus on learning the common classes well, while neglecting the rare classes. This is a problem known as "long-tail learning."
The authors of this new paper propose a solution to this problem. Their key insight is to use a "rebalanced contrastive loss" during training. This loss function encourages the model to learn more distinct representations for the rare classes, without forgetting about the common classes.
The paper "Simple Sampling, Hard Mixup, and Prototypes to Rebalance Long-Tailed Classification" also looked at techniques for addressing long-tail learning, but used different methods like mixup and prototype-based classification.
The authors show that their rebalanced contrastive loss outperforms these earlier approaches on standard long-tailed classification benchmarks. This suggests their method is an effective way to train models that can handle real-world datasets with highly skewed class distributions.
Technical Explanation
The authors propose a new loss function called "Rebalanced Contrastive Loss" (RCL) to address the challenge of long-tail learning. RCL builds upon the contrastive learning framework, which aims to learn visual representations by pulling together examples from the same class and pushing apart examples from different classes.
The paper "Bayesian Learning Driven Prototypical Contrastive Loss for Long-Tailed Classification" also explored using contrastive learning for long-tailed classification, but used a different loss formulation.
The key innovation in RCL is that it reweights the contrastive loss to give more emphasis to the rare/minority classes. Specifically, RCL computes the contrastive loss for each class, and then scales each class loss by the inverse of its frequency in the training set. This encourages the model to learn more distinctive representations for the rare classes.
The authors also propose a variant called "Saliency-Masked Contrastive Learning" (SMCL) that further boosts performance by masking out less informative regions of the input image during training.
The paper "SMCL: Saliency-Masked Contrastive Learning for Long-Tailed Recognition" explored a similar saliency-masking technique for long-tailed learning.
The authors evaluate their approaches on several long-tailed image classification benchmarks, including iNaturalist and Places365-LT. They show that RCL and SMCL outperform a variety of baseline methods, including previous work on data-aware and parameter-aware robustness in continual learning.
Critical Analysis
The authors provide a thorough empirical evaluation of their proposed methods, carefully comparing against relevant baselines. They also offer insightful discussions of the strengths and limitations of their approach.
One potential limitation is that the reweighting in RCL may be sensitive to the precise class frequencies in the training set. In real-world applications, the class distribution may shift over time, which could require re-tuning the reweighting scheme.
Additionally, the saliency-masking technique used in SMCL assumes that the important visual features for classification are spatially localized. This may not hold true for all types of long-tailed datasets or classification tasks.
Overall, this paper makes a valuable contribution to the important problem of long-tail learning. The rebalanced contrastive loss is a promising technique that could be further explored and refined in future work.
Conclusion
This paper introduces a new approach called Rebalanced Contrastive Loss (RCL) to address the challenge of long-tail learning in machine learning models. RCL builds upon contrastive learning, but reweights the loss function to give more emphasis to the rare/minority classes.
The authors show that RCL, as well as a variant called Saliency-Masked Contrastive Learning (SMCL), outperform a variety of baseline methods on standard long-tailed classification benchmarks. This suggests their techniques are an effective way to train models that can handle real-world datasets with highly skewed class distributions.
While the paper identifies some potential limitations, the rebalanced contrastive loss concept is a valuable contribution to the field of long-tail learning, with promising implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Long-Tail Learning with Rebalanced Contrastive Loss
Charika De Alvis, Dishanika Denipitiyage, Suranga Seneviratne
Integrating supervised contrastive loss to cross entropy-based communication has recently been proposed as a solution to address the long-tail learning problem. However, when the class imbalance ratio is high, it requires adjusting the supervised contrastive loss to support the tail classes, as the conventional contrastive learning is biased towards head classes by default. To this end, we present Rebalanced Contrastive Learning (RCL), an efficient means to increase the long tail classification accuracy by addressing three main aspects: 1. Feature space balancedness - Equal division of the feature space among all the classes, 2. Intra-Class compactness - Reducing the distance between same-class embeddings, 3. Regularization - Enforcing larger margins for tail classes to reduce overfitting. RCL adopts class frequency-based SoftMax loss balancing to supervised contrastive learning loss and exploits scalar multiplied features fed to the contrastive learning loss to enforce compactness. We implement RCL on the Balanced Contrastive Learning (BCL) Framework, which has the SOTA performance. Our experiments on three benchmark datasets demonstrate the richness of the learnt embeddings and increased top-1 balanced accuracy RCL provides to the BCL framework. We further demonstrate that the performance of RCL as a standalone loss also achieves state-of-the-art level accuracy.
Read more7/10/2024
0
Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
Alexandre Audibert, Aur'elien Gauffre, Massih-Reza Amini
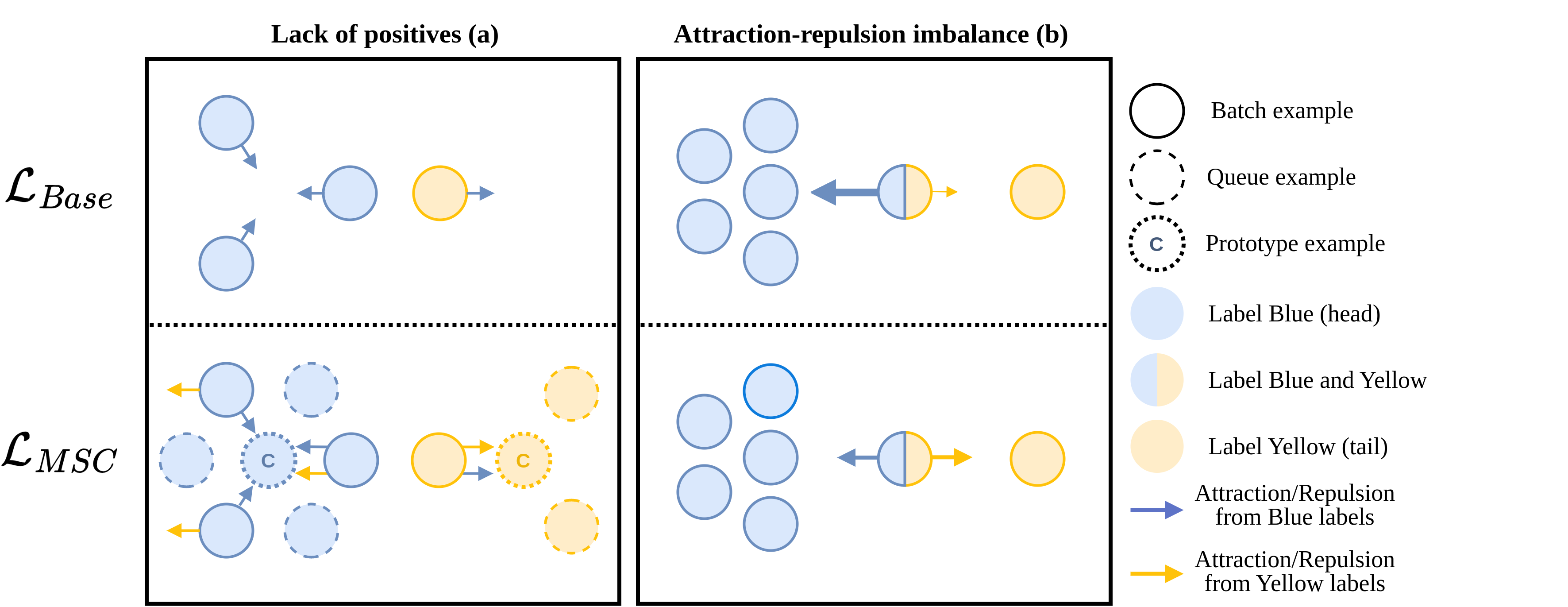
Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the lack of positives and the attraction-repulsion imbalance. Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
Read more4/16/2024

0
Simple-Sampling and Hard-Mixup with Prototypes to Rebalance Contrastive Learning for Text Classification
Mengyu Li, Yonghao Liu, Fausto Giunchiglia, Xiaoyue Feng, Renchu Guan
Text classification is a crucial and fundamental task in natural language processing. Compared with the previous learning paradigm of pre-training and fine-tuning by cross entropy loss, the recently proposed supervised contrastive learning approach has received tremendous attention due to its powerful feature learning capability and robustness. Although several studies have incorporated this technique for text classification, some limitations remain. First, many text datasets are imbalanced, and the learning mechanism of supervised contrastive learning is sensitive to data imbalance, which may harm the model performance. Moreover, these models leverage separate classification branch with cross entropy and supervised contrastive learning branch without explicit mutual guidance. To this end, we propose a novel model named SharpReCL for imbalanced text classification tasks. First, we obtain the prototype vector of each class in the balanced classification branch to act as a representation of each class. Then, by further explicitly leveraging the prototype vectors, we construct a proper and sufficient target sample set with the same size for each class to perform the supervised contrastive learning procedure. The empirical results show the effectiveness of our model, which even outperforms popular large language models across several datasets.
Read more5/21/2024
0
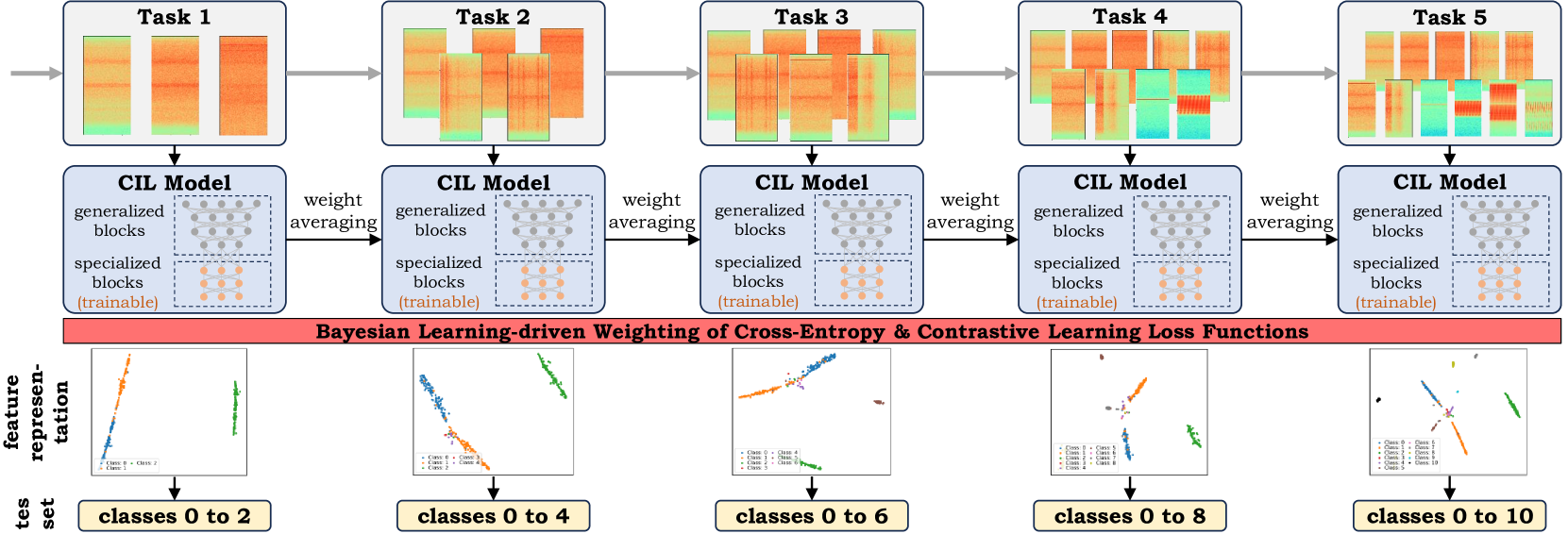
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 and CIFAR-100 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Read more7/15/2024