MATHWELL: Generating Age-Appropriate Educational Math Word Problems

0

Sign in to get full access
Overview
• This paper introduces MATHWELL, a system that can generate high-quality, diverse educational math word problems at scale. • The authors developed novel techniques to generate relevant, contextual, and solvable math word problems that can be used for educational purposes. • MATHWELL outperforms previous approaches in both human evaluation and automated metrics, demonstrating its potential to support math education.
Plain English Explanation
The MATHWELL system is designed to automatically create math word problems that can be used for educational purposes. Math word problems are important learning tools, as they require students to apply their math skills to real-world scenarios. However, creating a large and diverse set of high-quality math word problems is a time-consuming task for teachers.
To address this, the researchers developed MATHWELL, which uses advanced language models and other techniques to generate relevant, contextual, and solvable math word problems. These problems cover a range of math concepts and difficulty levels, and they are designed to engage students and help them develop their problem-solving skills.
The researchers evaluated MATHWELL using both human assessments and automated metrics, and found that it outperforms previous approaches. This suggests that MATHWELL could be a valuable tool for educators, helping them to more easily create engaging and effective math learning materials.
Technical Explanation
The MATHWELL system uses a combination of large language models, knowledge graphs, and other techniques to generate high-quality math word problems. The authors first trained a base language model on a large corpus of math-related text, which gave the model a strong understanding of mathematical concepts and language.
They then developed a series of techniques to refine and contextualize the generated problems. This included using knowledge graphs to ensure the problems were relevant and grounded in real-world scenarios, as well as incorporating data augmentation and other methods to improve the diversity and solvability of the problems.
The researchers evaluated MATHWELL using both human assessments and automated metrics, and found that it outperformed previous approaches in terms of problem quality, relevance, and other key factors. This suggests that the techniques used in MATHWELL could be valuable for supporting math education at scale.
Critical Analysis
The MATHWELL paper presents a promising approach to generating high-quality math word problems, but there are a few potential limitations and areas for further research:
-
The authors note that the system currently focuses on generating problems for specific grade levels or math concepts, but it may be challenging to scale this approach to cover a truly comprehensive range of math topics and difficulties. Exploring ways to make the system more flexible and adaptable could be an area for future work.
-
While the paper demonstrates the system's ability to generate contextual and relevant problems, it does not extensively explore the cognitive and pedagogical impact of these problems on student learning. Further research on how students engage with and learn from MATHWELL-generated problems would help validate its educational effectiveness.
-
The authors mention that the system currently focuses on generating word problems, but it may be valuable to explore ways to generate other types of math learning content, such as explanations, interactive visualizations, or practice problems.
Overall, the MATHWELL system represents an important step forward in using advanced language models and other techniques to support math education at scale. With further research and refinement, it could become a valuable tool for teachers and students alike.
Conclusion
The MATHWELL system demonstrates the potential of using large language models and other AI techniques to generate high-quality, contextual, and diverse math word problems at scale. By leveraging advanced language understanding and knowledge-based approaches, the researchers were able to create math problems that are both engaging and pedagogically sound.
The strong performance of MATHWELL in both human and automated evaluations suggests that it could be a valuable tool for supporting math education, helping teachers to more easily create a wide range of effective learning materials. While there are some potential limitations and areas for further research, the core ideas and techniques presented in this paper represent an important contribution to the field of educational technology and AI-assisted learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MATHWELL: Generating Age-Appropriate Educational Math Word Problems
Bryan R Christ, Jonathan Kropko, Thomas Hartvigsen
Math word problems are critical K-8 educational tools, but writing them is time-consuming and requires domain expertise. We suggest that language models can support K-8 math education by automatically generating problems. To be educational, generated problems must be 1) solvable, 2) accurate, and 3) appropriate. Existing datasets are unlabeled for these criteria, making them ill-suited for training problem generators. To address this gap, we use domain expert annotation to curate a high-quality synthetic training dataset for this task. We show the value of this data by using it to iteratively finetune Llama-2 (70B) to create MATHWELL, a K-8 word problem generator. Domain experts find MATHWELL has a 40% higher share of problems that have executable solutions and meet all criteria than existing open-source models, with 74% of its problems with executable solutions being solvable, accurate, and appropriate. MATHWELL achieves 94.9% of GPT-4 Turbo's performance on this task while outputting problems written at a more appropriate reading level for K-8 students. MATHWELL's performance despite being trained by finetuning only highlights the quality of our synthetic data for training age-appropriate word problem generators. We release our model, data, and annotations.
Read more4/17/2024

0
Adversarial Math Word Problem Generation
Roy Xie, Chengxuan Huang, Junlin Wang, Bhuwan Dhingra
Large language models (LLMs) have significantly transformed the educational landscape. As current plagiarism detection tools struggle to keep pace with LLMs' rapid advancements, the educational community faces the challenge of assessing students' true problem-solving abilities in the presence of LLMs. In this work, we explore a new paradigm for ensuring fair evaluation -- generating adversarial examples which preserve the structure and difficulty of the original questions aimed for assessment, but are unsolvable by LLMs. Focusing on the domain of math word problems, we leverage abstract syntax trees to structurally generate adversarial examples that cause LLMs to produce incorrect answers by simply editing the numeric values in the problems. We conduct experiments on various open- and closed-source LLMs, quantitatively and qualitatively demonstrating that our method significantly degrades their math problem-solving ability. We identify shared vulnerabilities among LLMs and propose a cost-effective approach to attack high-cost models. Additionally, we conduct automatic analysis to investigate the cause of failure, providing further insights into the limitations of LLMs.
Read more6/18/2024
0
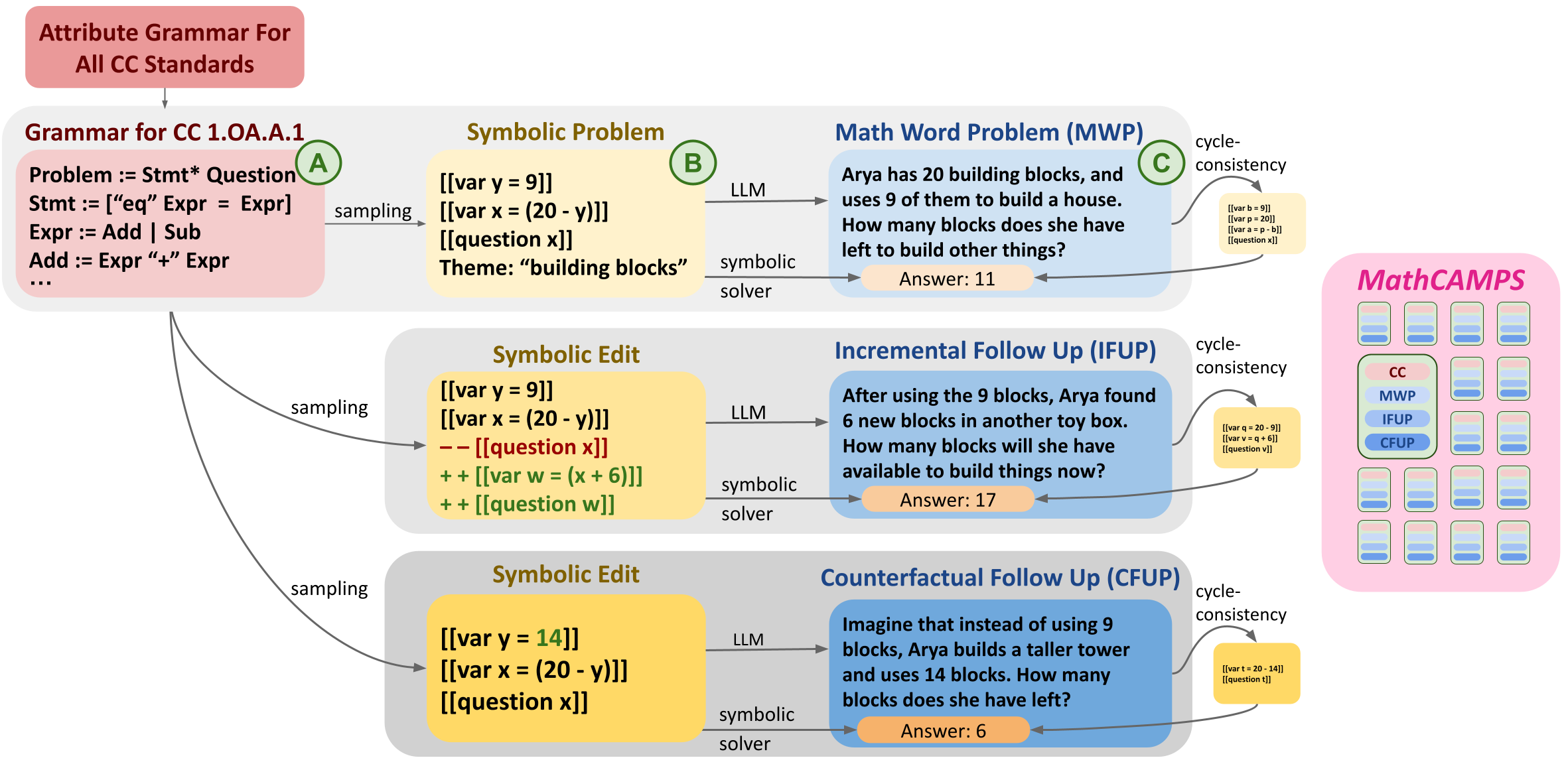
MathCAMPS: Fine-grained Synthesis of Mathematical Problems From Human Curricula
Shubhra Mishra, Gabriel Poesia, Belinda Mo, Noah D. Goodman
Mathematical problem solving is an important skill for Large Language Models (LLMs), both as an important capability and a proxy for a range of reasoning abilities. Existing benchmarks probe a diverse set of skills, but they yield aggregate accuracy metrics, obscuring specific abilities or weaknesses. Furthermore, they are difficult to extend with new problems, risking data contamination over time. To address these challenges, we propose MathCAMPS: a method to synthesize high-quality mathematical problems at scale, grounded on 44 fine-grained standards from the Mathematics Common Core (CC) Standard for K-8 grades. We encode each standard in a formal grammar, allowing us to sample diverse symbolic problems and their answers. We then use LLMs to realize the symbolic problems into word problems. We propose a cycle-consistency method for validating problem faithfulness. Finally, we derive follow-up questions from symbolic structures and convert them into follow-up word problems - a novel task of mathematical dialogue that probes for robustness in understanding. Experiments on 23 LLMs show surprising failures even in the strongest models (in particular when asked simple follow-up questions). Moreover, we evaluate training checkpoints of Pythia 12B on MathCAMPS, allowing us to analyze when particular mathematical skills develop during its training. Our framework enables the community to reproduce and extend our pipeline for a fraction of the typical cost of building new high-quality datasets.
Read more7/2/2024

0
MathGenie: Generating Synthetic Data with Question Back-translation for Enhancing Mathematical Reasoning of LLMs
Zimu Lu, Aojun Zhou, Houxing Ren, Ke Wang, Weikang Shi, Junting Pan, Mingjie Zhan, Hongsheng Li
Large language models (LLMs) have exhibited great potential in mathematical reasoning. However, there remains a performance gap in this area between existing open-source models and closed-source models such as GPT-4. In this paper, we introduce MathGenie, a novel method for generating diverse and reliable math problems from a small-scale problem-solution dataset (denoted as seed data). We augment the ground-truth solutions of our seed data and train a back-translation model to translate the augmented solutions back into new questions. Subsequently, we generate code-integrated solutions for the new questions. To ensure the correctness of the code-integrated solutions, we employ rationale-based strategy for solution verification. Various pretrained models, ranging from 7B to 70B, are trained on the newly curated data to test the effectiveness of the proposed augmentation technique, resulting in a family of models known as MathGenieLM. These models consistently outperform previous open-source models across five representative mathematical reasoning datasets, achieving state-of-the-art performance. In particular, MathGenieLM-InternLM2 achieves an accuracy of 87.7% on GSM8K and 55.7% on MATH, securing the best overall score among open-source language models.
Read more9/12/2024