Data Augmentation with In-Context Learning and Comparative Evaluation in Math Word Problem Solving
2404.03938
0
0

Abstract
Math Word Problem (MWP) solving presents a challenging task in Natural Language Processing (NLP). This study aims to provide MWP solvers with a more diverse training set, ultimately improving their ability to solve various math problems. We propose several methods for data augmentation by modifying the problem texts and equations, such as synonym replacement, rule-based: question replacement, and rule based: reversing question methodologies over two English MWP datasets. This study extends by introducing a new in-context learning augmentation method, employing the Llama-7b language model. This approach involves instruction-based prompting for rephrasing the math problem texts. Performance evaluations are conducted on 9 baseline models, revealing that augmentation methods outperform baseline models. Moreover, concatenating examples generated by various augmentation methods further improves performance.
Create account to get full access
Overview
- The paper explores using data augmentation techniques and in-context learning to improve the performance of language models on math word problem solving tasks.
- The researchers compare different data augmentation methods, including Exploring LLMs as Source-Targeted Synthetic Textual Data Augmentation, ChatGLM: Improving Math Problem Solving with Large Language Models, and Large Language Models for Mathematical Reasoning: Progress and Challenges.
- The paper also evaluates the models' performance using the SAAS: Solving Ability Amplification Strategy Enhanced Mathematical Problem Solving and Language Models Implement Simple Word2Vec-Style Vectors techniques.
Plain English Explanation
The researchers wanted to see if they could improve the ability of language models to solve math word problems. They tried different ways of adding more training data to the models, a process called "data augmentation." Some of the techniques they used included generating new math problems based on existing ones and using large language models to produce synthetic text.
The researchers also tested the models' performance using different evaluation methods, such as measuring their ability to solve math problems step-by-step and how well they could understand the relationships between words in the problems.
Overall, the goal was to find the best ways to help language models become better at solving complex math word problems, which can be a challenging task for AI systems.
Technical Explanation
The paper investigates the use of data augmentation and in-context learning to enhance the performance of language models on math word problem solving tasks. The researchers compare several data augmentation methods, including Exploring LLMs as Source-Targeted Synthetic Textual Data Augmentation, ChatGLM: Improving Math Problem Solving with Large Language Models, and Large Language Models for Mathematical Reasoning: Progress and Challenges.
The models' performance is evaluated using the SAAS: Solving Ability Amplification Strategy Enhanced Mathematical Problem Solving and Language Models Implement Simple Word2Vec-Style Vectors techniques. These methods assess the models' ability to solve math problems step-by-step and their understanding of the relationships between words in the problems.
Critical Analysis
The paper provides a thorough evaluation of various data augmentation techniques and their impact on language models' performance in math word problem solving. However, the researchers acknowledge that there are still limitations and areas for further research.
One potential concern is the extent to which the synthetic data generated by the language models accurately reflects the characteristics and complexity of real-world math word problems. Additionally, the researchers note that the performance of the models may be influenced by factors such as the quality of the initial training data and the specific evaluation metrics used.
It would be interesting to see further research exploring the generalization of these techniques to a broader range of mathematical reasoning tasks, as well as investigating the interpretability and transparency of the models' decision-making processes.
Conclusion
The paper presents a comprehensive study on the use of data augmentation and in-context learning to enhance the performance of language models on math word problem solving tasks. The researchers demonstrate the effectiveness of various data augmentation methods and evaluation techniques, providing valuable insights for improving the mathematical reasoning capabilities of AI systems.
The findings have the potential to contribute to the advancement of language models in tackling complex mathematical problems, with applications in educational technology, scientific research, and decision-making in fields that rely heavily on quantitative reasoning. However, further research is needed to address the limitations and explore the broader implications of these techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Investigating the Robustness of LLMs on Math Word Problems
Ujjwala Anantheswaran, Himanshu Gupta, Kevin Scaria, Shreyas Verma, Chitta Baral, Swaroop Mishra
0
0
Large Language Models (LLMs) excel at various tasks, including solving math word problems (MWPs), but struggle with real-world problems containing irrelevant information. To address this, we propose a prompting framework that generates adversarial variants of MWPs by adding irrelevant variables. We introduce a dataset, ProbleMATHIC, containing both adversarial and non-adversarial MWPs. Our experiments reveal that LLMs are susceptible to distraction by numerical noise, resulting in an average relative performance drop of ~26% on adversarial MWPs. To mitigate this, we fine-tune LLMs (Llama-2, Mistral) on the adversarial samples from our dataset. Fine-tuning on adversarial training instances improves performance on adversarial MWPs by ~8%, indicating increased robustness to noise and better ability to identify relevant data for reasoning. Finally, to assess the generalizability of our prompting framework, we introduce GSM-8K-Adv, an adversarial variant of the GSM-8K benchmark. LLMs continue to struggle when faced with adversarial information, reducing performance by up to ~6%.
6/26/2024
🧠
Can LLMs Solve longer Math Word Problems Better?
Xin Xu, Tong Xiao, Zitong Chao, Zhenya Huang, Can Yang, Yang Wang
0
0
Math Word Problems (MWPs) are crucial for evaluating the capability of Large Language Models (LLMs), with current research primarily focusing on questions with concise contexts. However, as real-world math problems often involve complex circumstances, LLMs' ability to solve long MWPs is vital for their applications in these scenarios, yet remains under-explored. This study pioneers the exploration of Context Length Generalizability (CoLeG), the ability of LLMs to solve long MWPs. We introduce Extended Grade-School Math (E-GSM), a collection of MWPs with lengthy narratives. Two novel metrics are proposed to assess the efficacy and resilience of LLMs in solving these problems. Our examination of existing zero-shot prompting techniques and both proprietary and open-source LLMs reveals a general deficiency in CoLeG. To alleviate these challenges, we propose distinct approaches for different categories of LLMs. For proprietary LLMs, a new instructional prompt is proposed to mitigate the influence of long context. For open-source LLMs, a new data augmentation task is developed to improve CoLeG. Our comprehensive results demonstrate the effectiveness of our proposed methods, showing not only improved performance on E-GSM but also generalizability across several other MWP benchmarks. Our findings pave the way for future research in employing LLMs for complex, real-world applications, offering practical solutions to current limitations and opening avenues for further exploration of model generalizability and training methodologies.
5/24/2024
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
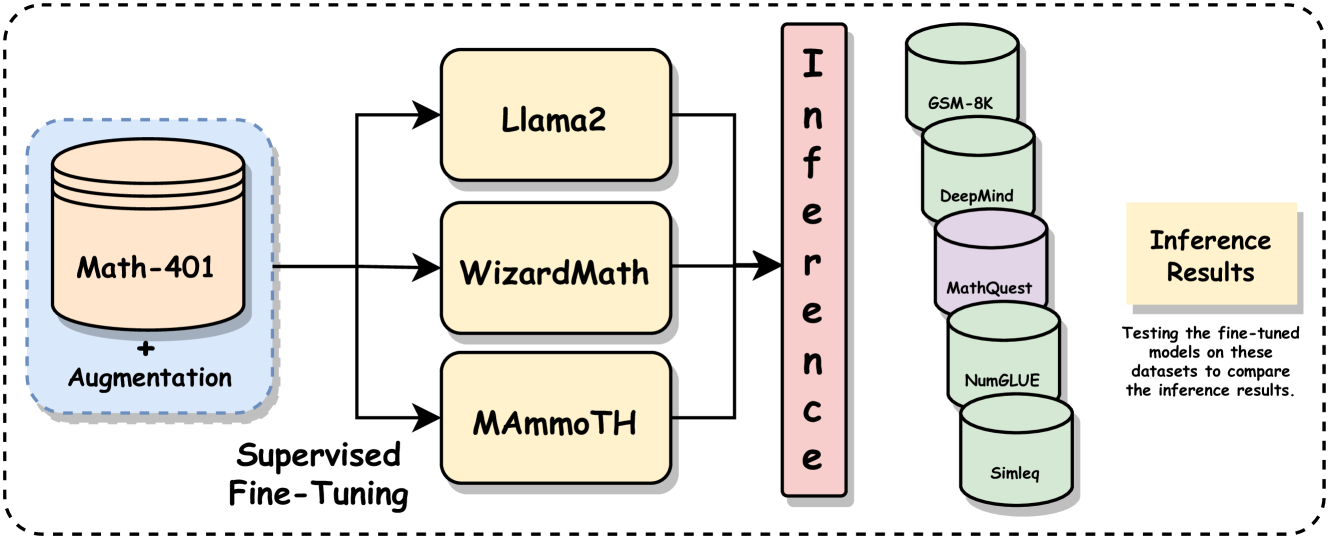
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
0
0
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
4/30/2024