MedDr: Diagnosis-Guided Bootstrapping for Large-Scale Medical Vision-Language Learning

0
🏅
Sign in to get full access
Overview
- This paper discusses the development of a generalist foundation model for healthcare, called MedDr, that can handle diverse medical data modalities.
- The researchers used a diagnosis-guided bootstrapping strategy to construct a high-quality image-text dataset for training the model.
- MedDr demonstrates superior performance on tasks like visual question answering, medical report generation, and medical image diagnosis.
Plain English Explanation
The rapid growth of large-scale vision-language models has shown impressive capabilities across many areas. However, the lack of extensive and high-quality medical image-text data has severely hindered the development of similar models for healthcare applications.
To address this, the researchers developed a bootstrapping strategy that uses both image and label information to build a robust medical vision-language dataset. They then used this dataset to train MedDr, a generalist foundation model that can handle diverse medical data, including radiology, pathology, dermatology, retinography, and endoscopy.
During the model's inference process, the researchers also proposed a simple but effective retrieval-augmented medical diagnosis strategy. This approach enhances MedDr's ability to generalize and perform well on a variety of medical tasks.
The researchers thoroughly evaluated MedDr's performance on tasks like visual question answering, medical report generation, and medical image diagnosis. Their experiments demonstrated the superiority of their approach compared to other methods.
Technical Explanation
The researchers developed a diagnosis-guided bootstrapping strategy to construct a high-quality image-text dataset for training a generalist foundation model, MedDr, for healthcare applications. This strategy exploited both image and label information to build a robust dataset.
Using the constructed dataset, the researchers trained MedDr, a model capable of handling diverse medical data modalities, including radiology, pathology, dermatology, retinography, and endoscopy. Moreover, during the inference process, the researchers proposed a simple but effective retrieval-augmented medical diagnosis strategy to enhance MedDr's generalization ability.
The researchers conducted extensive experiments to evaluate MedDr's performance on tasks such as visual question answering, medical report generation, and medical image diagnosis. The results demonstrated the superiority of their approach compared to other methods.
Critical Analysis
The paper provides a comprehensive approach to developing a generalist foundation model for healthcare, MedDr, addressing the challenge of limited high-quality medical image-text data. The researchers' diagnosis-guided bootstrapping strategy for dataset construction and their retrieval-augmented medical diagnosis approach during inference are notable contributions.
However, the paper does not discuss potential limitations or caveats of their research. For instance, the generalizability of the model across different healthcare systems or cultural contexts could be an area for further investigation. Additionally, the ethical implications of deploying such a powerful medical model, particularly around issues of bias and privacy, could be explored more deeply.
Readers are encouraged to think critically about the research and consider the broader implications of developing large-scale medical vision-language models. As these models become more prevalent, it will be crucial to address concerns related to their robustness, transparency, and alignment with ethical principles in healthcare.
Conclusion
This paper presents a significant step forward in the development of generalist foundation models for healthcare. By leveraging a diagnosis-guided bootstrapping strategy to construct a high-quality medical image-text dataset and incorporating a retrieval-augmented medical diagnosis approach, the researchers have demonstrated the capabilities of their MedDr model across diverse medical tasks.
The success of this work highlights the potential for large-scale vision-language models to revolutionize healthcare, from enhancing medical diagnosis and report generation to empowering novel applications. As the field continues to evolve, it will be crucial to address the ethical and societal implications of these powerful technologies to ensure they are deployed responsibly and equitably.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
MedDr: Diagnosis-Guided Bootstrapping for Large-Scale Medical Vision-Language Learning
Sunan He, Yuxiang Nie, Zhixuan Chen, Zhiyuan Cai, Hongmei Wang, Shu Yang, Hao Chen
The rapid advancement of large-scale vision-language models has showcased remarkable capabilities across various tasks. However, the lack of extensive and high-quality image-text data in medicine has greatly hindered the development of large-scale medical vision-language models. In this work, we present a diagnosis-guided bootstrapping strategy that exploits both image and label information to construct vision-language datasets. Based on the constructed dataset, we developed MedDr, a generalist foundation model for healthcare capable of handling diverse medical data modalities, including radiology, pathology, dermatology, retinography, and endoscopy. Moreover, during inference, we propose a simple but effective retrieval-augmented medical diagnosis strategy, which enhances the model's generalization ability. Extensive experiments on visual question answering, medical report generation, and medical image diagnosis demonstrate the superiority of our method.
Read more4/24/2024

0
STLLaVA-Med: Self-Training Large Language and Vision Assistant for Medical
Guohao Sun, Can Qin, Huazhu Fu, Linwei Wang, Zhiqiang Tao
Large Vision-Language Models (LVLMs) have shown significant potential in assisting medical diagnosis by leveraging extensive biomedical datasets. However, the advancement of medical image understanding and reasoning critically depends on building high-quality visual instruction data, which is costly and labor-intensive to obtain, particularly in the medical domain. To mitigate this data-starving issue, we introduce Self-Training Large Language and Vision Assistant for Medical (STLLaVA-Med). The proposed method is designed to train a policy model (an LVLM) capable of auto-generating medical visual instruction data to improve data efficiency, guided through Direct Preference Optimization (DPO). Specifically, a more powerful and larger LVLM (e.g., GPT-4o) is involved as a biomedical expert to oversee the DPO fine-tuning process on the auto-generated data, encouraging the policy model to align efficiently with human preferences. We validate the efficacy and data efficiency of STLLaVA-Med across three major medical Visual Question Answering (VQA) benchmarks, demonstrating competitive zero-shot performance with the utilization of only 9% of the medical data.
Read more7/1/2024

0
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, Guangjun Yu, Xiang Wan, Benyou Wang
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
Read more9/26/2024
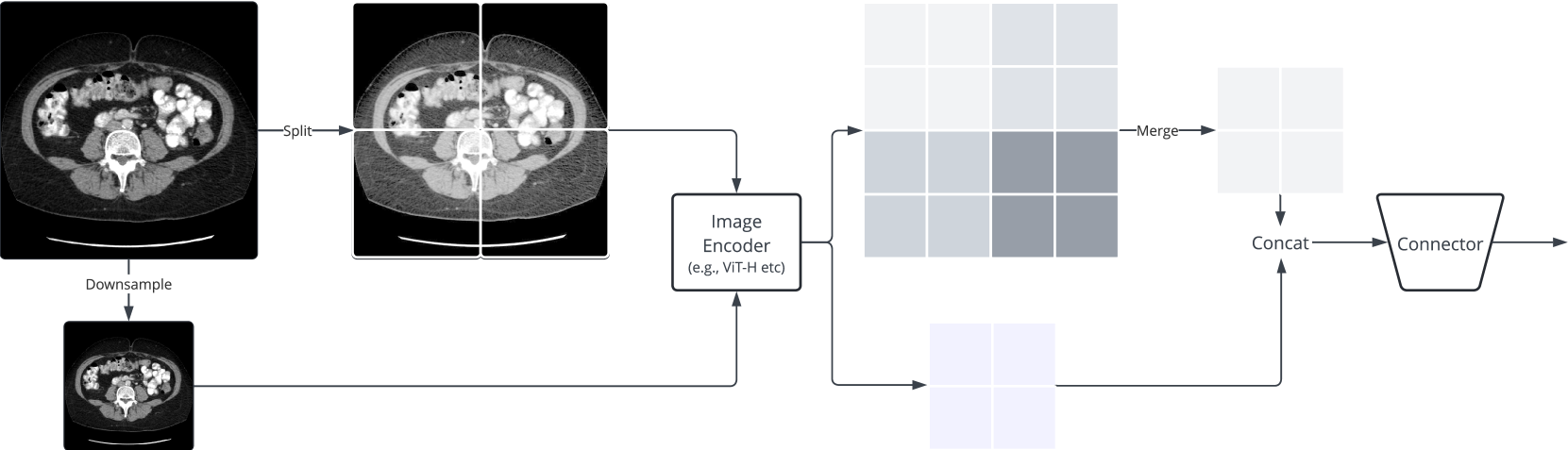
0
Advancing High Resolution Vision-Language Models in Biomedicine
Zekai Chen, Arda Pekis, Kevin Brown
Multi-modal learning has significantly advanced generative AI, especially in vision-language modeling. Innovations like GPT-4V and open-source projects such as LLaVA have enabled robust conversational agents capable of zero-shot task completions. However, applying these technologies in the biomedical field presents unique challenges. Recent initiatives like LLaVA-Med have started to adapt instruction-tuning for biomedical contexts using large datasets such as PMC-15M. Our research offers three key contributions: (i) we present a new instruct dataset enriched with medical image-text pairs from Claude3-Opus and LLaMA3 70B, (ii) we propose a novel image encoding strategy using hierarchical representations to improve fine-grained biomedical visual comprehension, and (iii) we develop the Llama3-Med model, which achieves state-of-the-art zero-shot performance on biomedical visual question answering benchmarks, with an average performance improvement of over 10% compared to previous methods. These advancements provide more accurate and reliable tools for medical professionals, bridging gaps in current multi-modal conversational assistants and promoting further innovations in medical AI.
Read more6/17/2024