MedReadMe: A Systematic Study for Fine-grained Sentence Readability in Medical Domain

0

Sign in to get full access
Overview
- This paper presents the creation of the MedReadMe corpus, a dataset designed to study fine-grained sentence readability in the medical domain.
- The researchers developed methods to automatically classify sentences in medical texts based on their readability for different audiences, including medical professionals and the general public.
- The paper describes the construction of the MedReadMe corpus, the annotation process, and the development of sentence-level readability prediction models.
Plain English Explanation
The MedReadMe: A Systematic Study for Fine-grained Sentence Readability in Medical Domain paper focuses on making medical information more accessible to the general public. The researchers created a dataset called MedReadMe that contains medical sentences labeled with their readability level for different audiences, such as doctors and patients.
By developing models to automatically analyze the readability of medical sentences, the researchers aim to help bridge the gap between the technical language used in the medical field and the understanding of the general public. This could improve the communication of medical information and make it easier for patients to understand important health-related details.
The researchers used various techniques to classify the sentences in the MedReadMe corpus, drawing inspiration from previous work on computational sentence-level metrics and approaches for fine-grained scoring from aggregate text. This allowed them to develop models that can automatically assess the readability of medical sentences, which could be useful for automated text mining and experimental methodologies in the biomedical field.
Technical Explanation
The researchers constructed the MedReadMe corpus by collecting medical text from various sources, including scientific articles, patient education materials, and clinical notes. They then had medical professionals and lay people annotate the sentences in the corpus based on their readability for different audiences, such as medical experts and the general public.
Using the annotated MedReadMe corpus, the researchers developed machine learning models to predict the readability of medical sentences. They explored various features, including linguistic metrics, medical terminology, and fractal-based scoring approaches, to train their models. The resulting models demonstrated the ability to accurately classify the readability of medical sentences, which could be useful for automating the analysis of medical text and improving the communication of medical information to patients.
Critical Analysis
The researchers acknowledge several limitations of their work, including the relatively small size of the MedReadMe corpus and the potential bias in the annotation process. They also note that the models may not generalize well to all types of medical texts, and further research is needed to explore the application of the MedReadMe corpus and readability prediction models in real-world settings.
Additionally, the paper does not address potential ethical concerns, such as the impact of automated readability assessment on patient-provider communication or the potential for misuse of such technology. It would be valuable for future research to consider these aspects more thoroughly.
Conclusion
The MedReadMe: A Systematic Study for Fine-grained Sentence Readability in Medical Domain paper presents a novel approach to improve the accessibility of medical information for the general public. By developing the MedReadMe corpus and associated readability prediction models, the researchers have taken an important step towards bridging the gap between medical jargon and lay understanding, which could have significant implications for patient education and healthcare communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MedReadMe: A Systematic Study for Fine-grained Sentence Readability in Medical Domain
Chao Jiang, Wei Xu
Medical texts are notoriously challenging to read. Properly measuring their readability is the first step towards making them more accessible. In this paper, we present a systematic study on fine-grained readability measurements in the medical domain at both sentence-level and span-level. We introduce a new dataset MedReadMe, which consists of manually annotated readability ratings and fine-grained complex span annotation for 4,520 sentences, featuring two novel Google-Easy and Google-Hard categories. It supports our quantitative analysis, which covers 650 linguistic features and automatic complex word and jargon identification. Enabled by our high-quality annotation, we benchmark and improve several state-of-the-art sentence-level readability metrics for the medical domain specifically, which include unsupervised, supervised, and prompting-based methods using recently developed large language models (LLMs). Informed by our fine-grained complex span annotation, we find that adding a single feature, capturing the number of jargon spans, into existing readability formulas can significantly improve their correlation with human judgments. We will publicly release the dataset and code.
Read more5/6/2024
💬
0
ReadMe++: Benchmarking Multilingual Language Models for Multi-Domain Readability Assessment
Tarek Naous, Michael J. Ryan, Anton Lavrouk, Mohit Chandra, Wei Xu
We present a comprehensive evaluation of large language models for multilingual readability assessment. Existing evaluation resources lack domain and language diversity, limiting the ability for cross-domain and cross-lingual analyses. This paper introduces ReadMe++, a multilingual multi-domain dataset with human annotations of 9757 sentences in Arabic, English, French, Hindi, and Russian, collected from 112 different data sources. This benchmark will encourage research on developing robust multilingual readability assessment methods. Using ReadMe++, we benchmark multilingual and monolingual language models in the supervised, unsupervised, and few-shot prompting settings. The domain and language diversity in ReadMe++ enable us to test more effective few-shot prompting, and identify shortcomings in state-of-the-art unsupervised methods. Our experiments also reveal exciting results of superior domain generalization and enhanced cross-lingual transfer capabilities by models trained on ReadMe++. We will make our data publicly available and release a python package tool for multilingual sentence readability prediction using our trained models at: https://github.com/tareknaous/readme
Read more6/11/2024
0
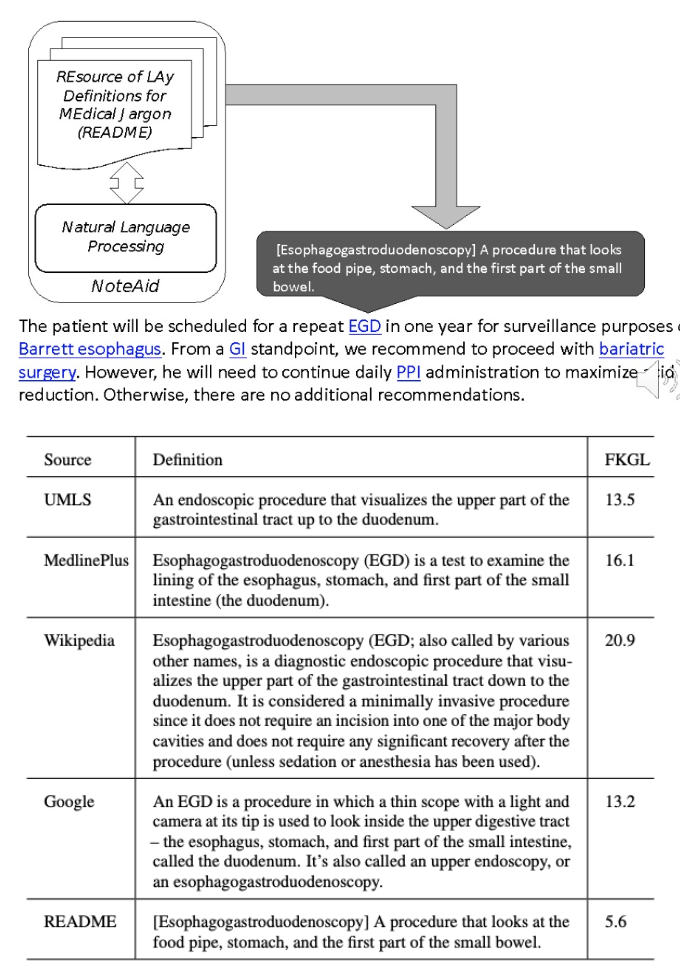
README: Bridging Medical Jargon and Lay Understanding for Patient Education through Data-Centric NLP
Zonghai Yao, Nandyala Siddharth Kantu, Guanghao Wei, Hieu Tran, Zhangqi Duan, Sunjae Kwon, Zhichao Yang, README annotation team, Hong Yu
The advancement in healthcare has shifted focus toward patient-centric approaches, particularly in self-care and patient education, facilitated by access to Electronic Health Records (EHR). However, medical jargon in EHRs poses significant challenges in patient comprehension. To address this, we introduce a new task of automatically generating lay definitions, aiming to simplify complex medical terms into patient-friendly lay language. We first created the README dataset, an extensive collection of over 50,000 unique (medical term, lay definition) pairs and 300,000 mentions, each offering context-aware lay definitions manually annotated by domain experts. We have also engineered a data-centric Human-AI pipeline that synergizes data filtering, augmentation, and selection to improve data quality. We then used README as the training data for models and leveraged a Retrieval-Augmented Generation method to reduce hallucinations and improve the quality of model outputs. Our extensive automatic and human evaluations demonstrate that open-source mobile-friendly models, when fine-tuned with high-quality data, are capable of matching or even surpassing the performance of state-of-the-art closed-source large language models like ChatGPT. This research represents a significant stride in closing the knowledge gap in patient education and advancing patient-centric healthcare solutions.
Read more6/18/2024

0
Computational Sentence-level Metrics Predicting Human Sentence Comprehension
Kun Sun, Rong Wang
The majority of research in computational psycholinguistics has concentrated on the processing of words. This study introduces innovative methods for computing sentence-level metrics using multilingual large language models. The metrics developed sentence surprisal and sentence relevance and then are tested and compared to validate whether they can predict how humans comprehend sentences as a whole across languages. These metrics offer significant interpretability and achieve high accuracy in predicting human sentence reading speeds. Our results indicate that these computational sentence-level metrics are exceptionally effective at predicting and elucidating the processing difficulties encountered by readers in comprehending sentences as a whole across a variety of languages. Their impressive performance and generalization capabilities provide a promising avenue for future research in integrating LLMs and cognitive science.
Read more4/17/2024