MERBench: A Unified Evaluation Benchmark for Multimodal Emotion Recognition
2401.03429
0
0

Abstract
Multimodal emotion recognition plays a crucial role in enhancing user experience in human-computer interaction. Over the past few decades, researchers have proposed a series of algorithms and achieved impressive progress. Although each method shows its superior performance, different methods lack a fair comparison due to inconsistencies in feature extractors, evaluation manners, and experimental settings. These inconsistencies severely hinder the development of this field. Therefore, we build MERBench, a unified evaluation benchmark for multimodal emotion recognition. We aim to reveal the contribution of some important techniques employed in previous works, such as feature selection, multimodal fusion, robustness analysis, fine-tuning, pre-training, etc. We hope this benchmark can provide clear and comprehensive guidance for follow-up researchers. Based on the evaluation results of MERBench, we further point out some promising research directions. Additionally, we introduce a new emotion dataset MER2023, focusing on the Chinese language environment. This dataset can serve as a benchmark dataset for research on multi-label learning, noise robustness, and semi-supervised learning. We encourage the follow-up researchers to evaluate their algorithms under the same experimental setup as MERBench for fair comparisons. Our code is available at: https://github.com/zeroQiaoba/MERTools.
Create account to get full access
Overview
- Introduces MERBench, a unified evaluation benchmark for multimodal emotion recognition
- Examines feature selection, multimodal fusion, cross-corpus performance, and robustness analysis
- Aims to provide a comprehensive framework for evaluating multimodal emotion recognition systems
Plain English Explanation
MERBench is a new evaluation benchmark for multimodal emotion recognition systems. Emotion recognition is the process of identifying and understanding the emotional state of a person based on various signals, such as facial expressions, tone of voice, and body language. Multimodal emotion recognition refers to the use of multiple of these signals, rather than just one, to improve the accuracy and robustness of the emotion recognition.
The MERBench framework is designed to provide a comprehensive set of tools and datasets for evaluating the performance of multimodal emotion recognition systems. This includes examining how well the systems can select the most relevant features from the different modalities, how effectively they can combine and fuse the information from those modalities, and how well they perform when tested on data from different sources or "corpora".
The goal of MERBench is to help researchers and developers create more accurate, reliable, and practical multimodal emotion recognition systems. By providing a standardized benchmark, it allows for better comparison and evaluation of different approaches, which can ultimately lead to more advanced and impactful emotion recognition technologies.
Technical Explanation
MERBench is a unified evaluation benchmark for multimodal emotion recognition systems, designed to assess their performance across several key areas:
-
Feature Selection: The benchmark examines how effectively the systems can select the most relevant features from the available modalities (e.g., facial expressions, speech, body language) to maximize emotion recognition accuracy.
-
Multimodal Fusion: MERBench evaluates the systems' ability to effectively combine and fuse the information from multiple modalities to improve overall recognition performance.
-
Cross-Corpus Performance: The benchmark tests how well the systems generalize and perform when applied to data from different sources or "corpora", beyond the data they were trained on.
-
Robustness Analysis: MERBench assesses the systems' robustness to various real-world challenges, such as noisy or incomplete data, variations in the input, and other factors that can affect emotion recognition in practical applications.
By providing a standardized set of datasets, evaluation protocols, and performance metrics, MERBench aims to enable more comprehensive and comparable assessments of multimodal emotion recognition systems. This can help drive the development of more accurate, reliable, and practical emotion recognition technologies, with potential applications in areas such as human-computer interaction, mental health monitoring, and affective computing.
Critical Analysis
The MERBench framework addresses important challenges in the field of multimodal emotion recognition, such as the need for standardized evaluation protocols and the ability to assess the cross-corpus performance and robustness of emotion recognition systems. By providing a comprehensive set of tools and datasets, MERBench can help researchers and developers better understand the strengths and limitations of their approaches, and identify areas for further improvement.
However, the paper also acknowledges some limitations of the current MERBench implementation. For example, the benchmark primarily focuses on acted emotional expressions, which may not fully capture the complexity and nuances of real-world, spontaneous emotional behaviors. Additionally, the paper suggests that further work is needed to incorporate more diverse datasets and modalities, as well as to address issues related to data privacy and ethical considerations in emotion recognition research.
As the field of multimodal emotion recognition continues to evolve, it will be important for benchmarks like MERBench to adapt and expand to keep pace with emerging techniques and use cases. Ongoing collaboration between researchers, developers, and end-users will be crucial to ensure that benchmarks remain relevant and impactful in driving the development of more advanced multimodal emotion recognition systems that can be deployed in real-world applications.
Conclusion
The MERBench framework represents an important step forward in the evaluation of multimodal emotion recognition systems. By providing a comprehensive and standardized benchmark, it can help drive the development of more accurate, robust, and practical emotion recognition technologies, with the potential to have a significant impact in a wide range of applications, from human-computer interaction to mental health monitoring and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
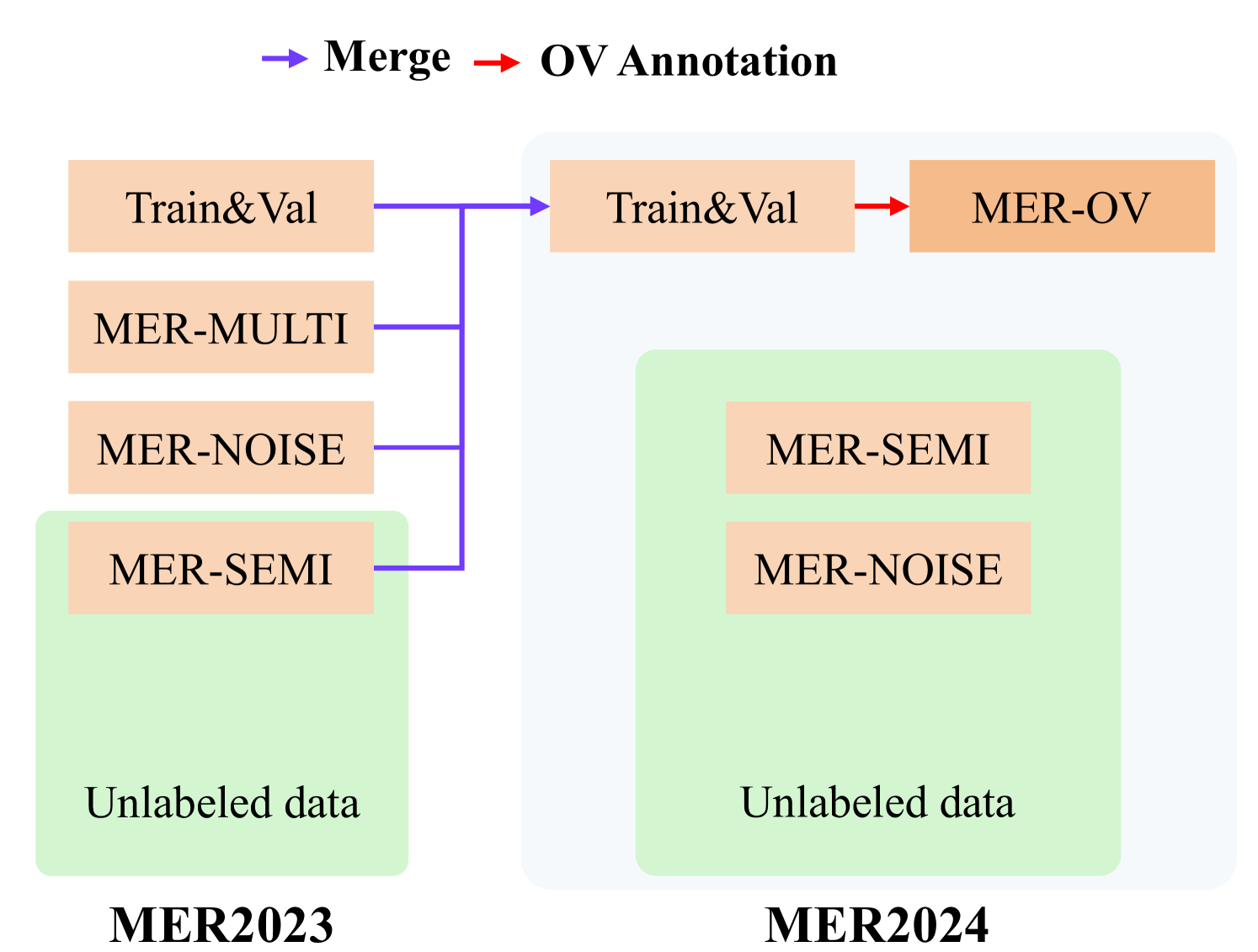
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Zheng Lian, Haiyang Sun, Licai Sun, Zhuofan Wen, Siyuan Zhang, Shun Chen, Hao Gu, Jinming Zhao, Ziyang Ma, Xie Chen, Jiangyan Yi, Rui Liu, Kele Xu, Bin Liu, Erik Cambria, Guoying Zhao, Bjorn W. Schuller, Jianhua Tao
0
0
Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate annotations), current systems are hard to meet the demands of practical applications. Therefore, we organize a series of challenges around emotion recognition to further promote the development of this area. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
5/24/2024

MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Fei Wang, Xingyu Fu, James Y. Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, Muhao Chen
0
0
We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
6/14/2024
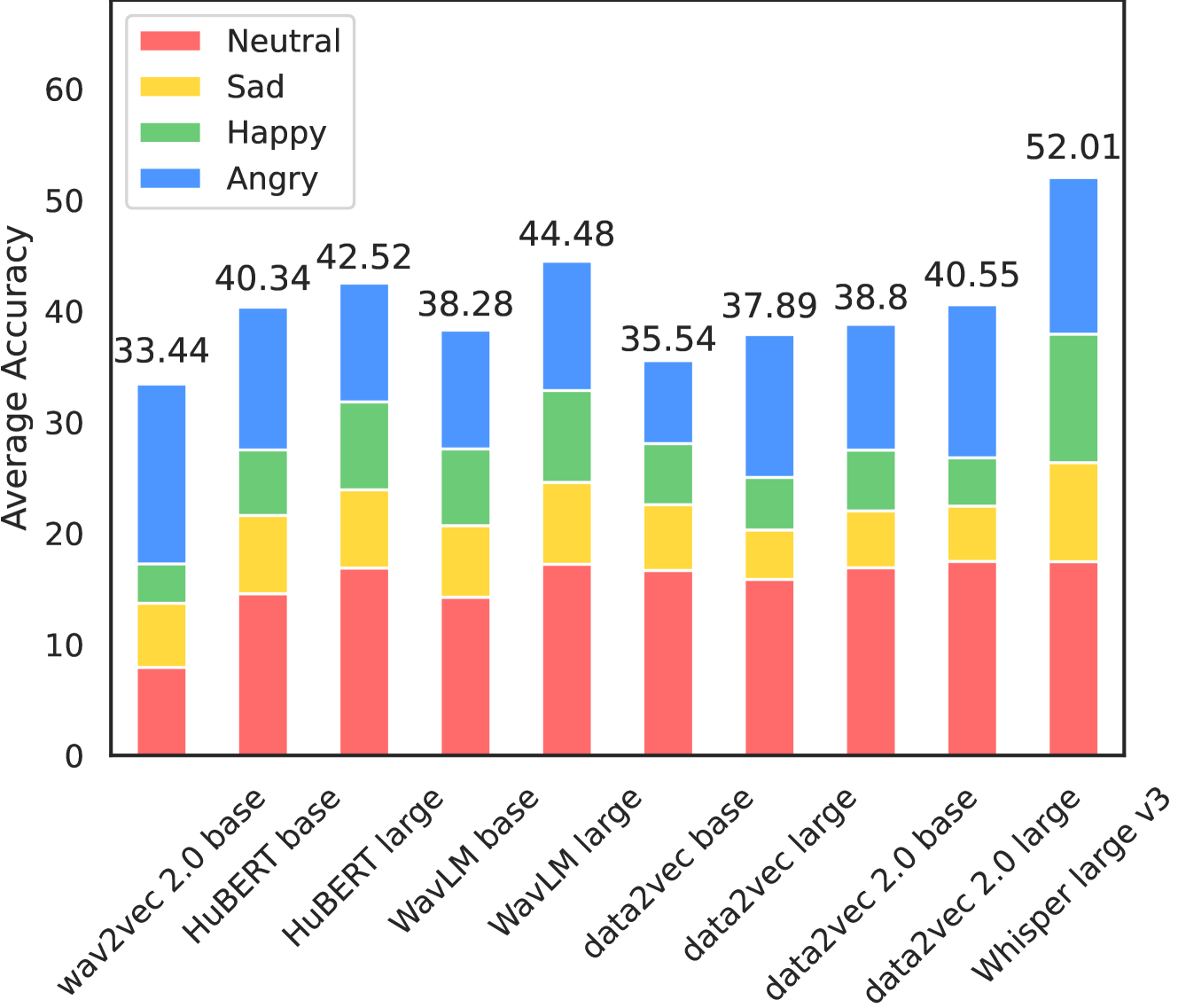
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Ziyang Ma, Mingjie Chen, Hezhao Zhang, Zhisheng Zheng, Wenxi Chen, Xiquan Li, Jiaxin Ye, Xie Chen, Thomas Hain
0
0
Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
6/12/2024
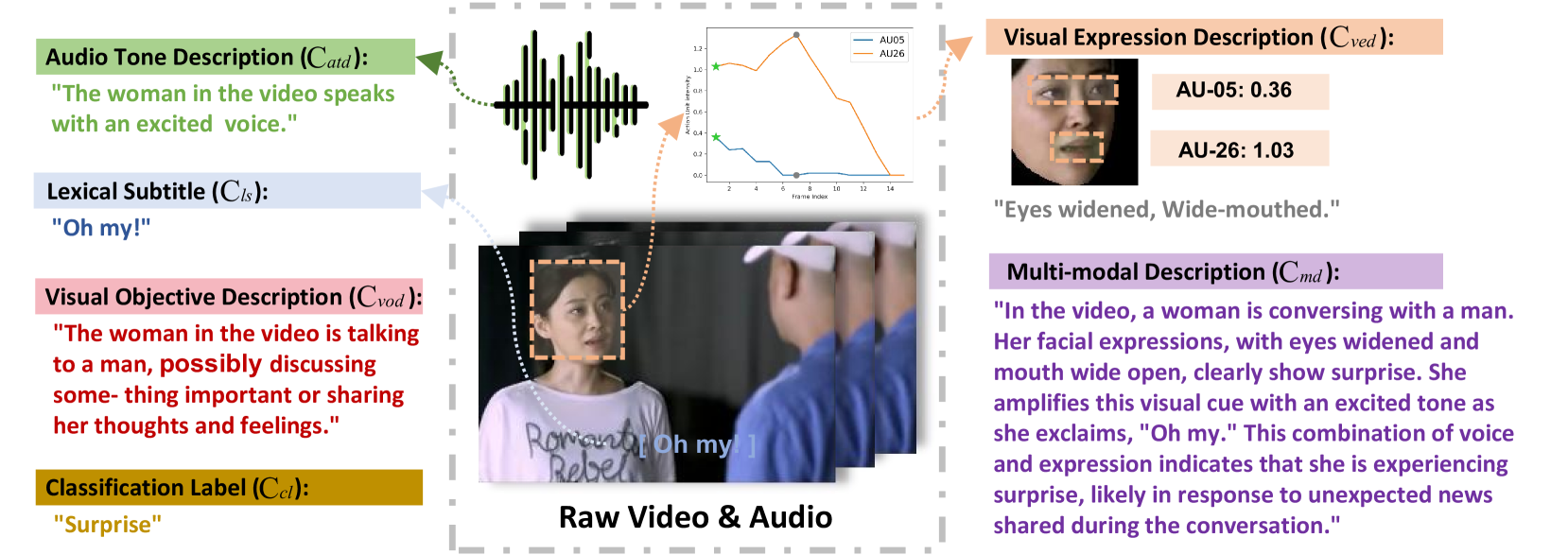
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024