Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models

0

Sign in to get full access
Overview
- This paper introduces Meteor, a novel approach for navigating the rationale behind large language and vision models.
- Meteor leverages a Mamba-based framework to better understand the inner workings of these complex models.
- The authors demonstrate the application of Meteor on several prominent models, including LLMs are Clinical Reasoners, VisionGraph, and Explain Multi-Modal LLMs.
Plain English Explanation
Meteor is a new technique that helps us better understand how large language and vision models, like the ones used in LLMs are Clinical Reasoners and VisionGraph, work under the hood. These models are incredibly powerful, but it's often hard to know exactly how they arrive at their outputs. Meteor uses a framework called Mamba to map out the reasoning process of the models, step-by-step. This can help researchers and developers better understand the models' strengths, weaknesses, and potential biases, which is important for Explain Multi-Modal LLMs and applications like Describe then Reason where transparency is crucial. By shedding light on the inner workings of these models, Meteor could lead to more reliable and trustworthy AI systems in the future.
Technical Explanation
The Meteor framework uses a Mamba-based approach to trace the reasoning process of large language and vision models. Mamba is a probabilistic programming language that allows for the construction of complex statistical models. In the context of Meteor, Mamba is used to create a Bayesian network that mirrors the structure and decision-making of the target model.
By constructing this Mamba-based model, researchers can then analyze the flow of information and the relative importance of different inputs as the model arrives at its final output. This provides valuable insights into the model's internal logic and can help identify potential biases or shortcomings.
The authors demonstrate the application of Meteor on several prominent models, including LLMs are Clinical Reasoners, VisionGraph, and Explain Multi-Modal LLMs. Through these case studies, they showcase Meteor's ability to uncover the reasoning behind the models' outputs and highlight opportunities for improving model transparency and interpretability.
Critical Analysis
The Meteor framework represents a promising approach for gaining a deeper understanding of complex AI models, but it is not without its limitations. The authors acknowledge that the Mamba-based approach can be computationally intensive, particularly when applied to large and highly complex models. This may limit the scalability of Meteor and its practical applicability in certain real-world scenarios.
Additionally, the authors note that the Mamba-based model constructed by Meteor may not perfectly capture the entire decision-making process of the target model, as there may be inherent differences in the underlying architectures and training procedures. This could lead to discrepancies between the Meteor model's predictions and the actual behavior of the target model.
Further research is needed to explore ways of improving the efficiency and accuracy of the Meteor framework, as well as its applicability to a wider range of AI models and domains. Nonetheless, the insights provided by Meteor represent an important step forward in Improving Language Model Reasoning and the pursuit of more transparent and trustworthy AI systems.
Conclusion
The Meteor framework introduces a novel approach for navigating the rationale behind large language and vision models. By leveraging a Mamba-based framework, Meteor can provide valuable insights into the inner workings of these complex models, shedding light on their strengths, weaknesses, and potential biases. The authors demonstrate the applicability of Meteor across several prominent models, showcasing its potential to enhance model transparency and interpretability.
While Meteor faces some computational challenges, the insights it provides represent an important step forward in the field of AI explainability and responsible model development. As the demand for transparent and trustworthy AI systems continues to grow, Meteor and similar techniques could play a crucial role in Improving Language Model Reasoning and ensuring the safe and ethical deployment of large language and vision models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models
Byung-Kwan Lee, Chae Won Kim, Beomchan Park, Yong Man Ro
The rapid development of large language and vision models (LLVMs) has been driven by advances in visual instruction tuning. Recently, open-source LLVMs have curated high-quality visual instruction tuning datasets and utilized additional vision encoders or multiple computer vision models in order to narrow the performance gap with powerful closed-source LLVMs. These advancements are attributed to multifaceted information required for diverse capabilities, including fundamental image understanding, real-world knowledge about common-sense and non-object concepts (e.g., charts, diagrams, symbols, signs, and math problems), and step-by-step procedures for solving complex questions. Drawing from the multifaceted information, we present a new efficient LLVM, Mamba-based traversal of rationales (Meteor), which leverages multifaceted rationale to enhance understanding and answering capabilities. To embed lengthy rationales containing abundant information, we employ the Mamba architecture, capable of processing sequential data with linear time complexity. We introduce a new concept of traversal of rationale that facilitates efficient embedding of rationale. Subsequently, the backbone multimodal language model (MLM) is trained to generate answers with the aid of rationale. Through these steps, Meteor achieves significant improvements in vision language performances across multiple evaluation benchmarks requiring diverse capabilities, without scaling up the model size or employing additional vision encoders and computer vision models.
Read more5/28/2024
0
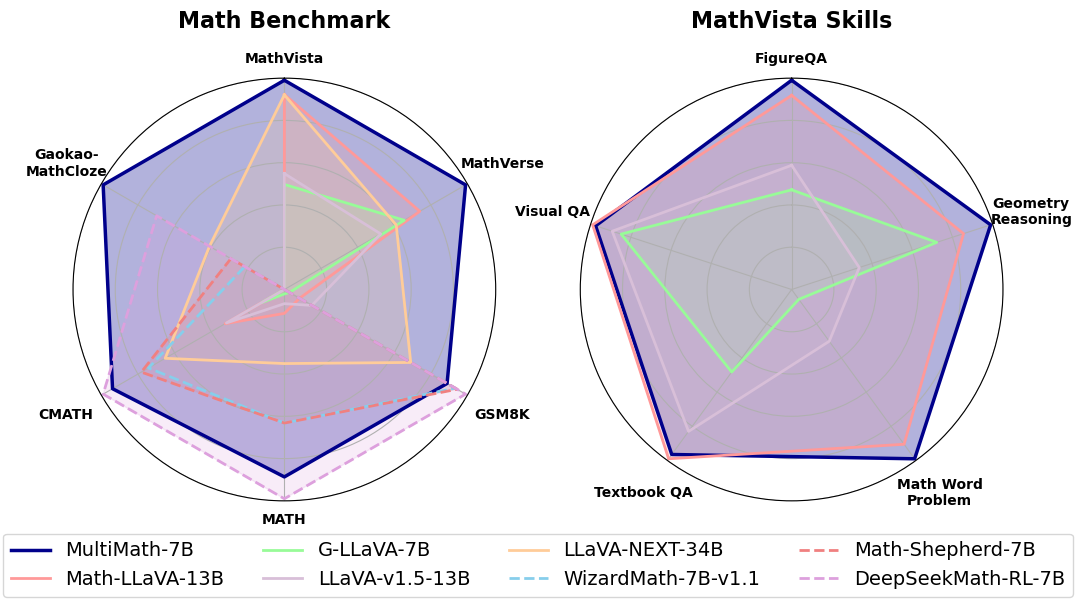
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {textcolor{blue}{url{https://github.com/pengshuai-rin/MultiMath}}}.
Read more9/4/2024

0
ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2
Wenjun Huang, Jiakai Pan, Jiahao Tang, Yanyu Ding, Yifei Xing, Yuhe Wang, Zhengzhuo Wang, Jianguo Hu
Multimodal Large Language Models (MLLMs) have attracted much attention for their multifunctionality. However, traditional Transformer architectures incur significant overhead due to their secondary computational complexity. To address this issue, we introduce ML-Mamba, a multimodal language model, which utilizes the latest and efficient Mamba-2 model for inference. Mamba-2 is known for its linear scalability and fast processing of long sequences. We replace the Transformer-based backbone with a pre-trained Mamba-2 model and explore methods for integrating 2D visual selective scanning mechanisms into multimodal learning while also trying various visual encoders and Mamba-2 model variants. Our extensive experiments in various multimodal benchmark tests demonstrate the competitive performance of ML-Mamba and highlight the potential of state space models in multimodal tasks. The experimental results show that: (1) we empirically explore how to effectively apply the 2D vision selective scan mechanism for multimodal learning. We propose a novel multimodal connector called the Mamba-2 Scan Connector (MSC), which enhances representational capabilities. (2) ML-Mamba achieves performance comparable to state-of-the-art methods such as TinyLaVA and MobileVLM v2 through its linear sequential modeling while faster inference speed; (3) Compared to multimodal models utilizing Mamba-1, the Mamba-2-based ML-Mamba exhibits superior inference performance and effectiveness.
Read more8/22/2024

0
New!Mamba Fusion: Learning Actions Through Questioning
Zhikang Dong, Apoorva Beedu, Jason Sheinkopf, Irfan Essa
Video Language Models (VLMs) are crucial for generalizing across diverse tasks and using language cues to enhance learning. While transformer-based architectures have been the de facto in vision-language training, they face challenges like quadratic computational complexity, high GPU memory usage, and difficulty with long-term dependencies. To address these limitations, we introduce MambaVL, a novel model that leverages recent advancements in selective state space modality fusion to efficiently capture long-range dependencies and learn joint representations for vision and language data. MambaVL utilizes a shared state transition matrix across both modalities, allowing the model to capture information about actions from multiple perspectives within the scene. Furthermore, we propose a question-answering task that helps guide the model toward relevant cues. These questions provide critical information about actions, objects, and environmental context, leading to enhanced performance. As a result, MambaVL achieves state-of-the-art performance in action recognition on the Epic-Kitchens-100 dataset and outperforms baseline methods in action anticipation.
Read more9/19/2024