Mitigating Data Imbalance for Software Vulnerability Assessment: Does Data Augmentation Help?

0

Sign in to get full access
Overview
• This paper examines the effectiveness of data augmentation techniques in mitigating data imbalance for software vulnerability assessment. • Data imbalance is a common challenge in this domain, where the number of vulnerable software samples is often much lower than the number of non-vulnerable samples. • The researchers explore whether data augmentation, a technique that generates synthetic data, can help improve the performance of machine learning models in predicting software vulnerabilities.
Plain English Explanation
Software systems are increasingly complex, making them vulnerable to security threats. Identifying and addressing these vulnerabilities is crucial for ensuring the safety and reliability of software. Machine learning models have shown promise in automating the vulnerability assessment process, but they often suffer from the problem of data imbalance. This means that the number of vulnerable software samples in the training data is much lower than the number of non-vulnerable samples.
Data augmentation is a technique that can help address this issue by generating synthetic data to balance the dataset. The idea is to create new, realistic-looking samples of vulnerable software that can be used to train the machine learning model, thereby improving its ability to identify vulnerabilities accurately.
In this paper, the researchers investigate whether data augmentation can indeed help mitigate the data imbalance problem in software vulnerability assessment. They explore different data augmentation techniques and evaluate their impact on the performance of machine learning models in predicting software vulnerabilities.
Technical Explanation
The researchers conducted experiments using several publicly available datasets of software vulnerabilities. They employed various data augmentation techniques, such as SMOTE and SynAug, to generate synthetic vulnerable samples and balance the datasets.
The performance of the machine learning models, including logistic regression and random forest, was evaluated using metrics such as precision, recall, and F1-score. The researchers compared the results of the models trained on the original imbalanced datasets and the augmented datasets to assess the impact of data augmentation.
The findings suggest that data augmentation can indeed improve the performance of machine learning models in software vulnerability assessment. The synthetic data generated by the augmentation techniques helped the models better recognize the characteristics of vulnerable software, leading to higher accuracy in predicting vulnerabilities.
Critical Analysis
The paper provides a comprehensive survey of data augmentation techniques and their application to the software vulnerability assessment problem. However, the researchers acknowledge that the effectiveness of data augmentation may depend on the specific characteristics of the dataset and the machine learning model used.
Additionally, the paper does not explore the potential limitations of data augmentation, such as the risk of introducing unrealistic or biased synthetic data that could negatively impact the model's performance. Further research is needed to understand the conditions under which data augmentation is most effective and to address any potential drawbacks.
Conclusion
This paper demonstrates the potential of data augmentation to mitigate the data imbalance problem in software vulnerability assessment. By generating synthetic vulnerable samples, the machine learning models were able to better capture the characteristics of vulnerable software and improve their predictive accuracy.
The findings of this research have important implications for the development of more robust and reliable software security systems. By leveraging data augmentation techniques, security researchers and practitioners can enhance the capabilities of machine learning-based vulnerability assessment tools, ultimately contributing to the overall security and resilience of software systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mitigating Data Imbalance for Software Vulnerability Assessment: Does Data Augmentation Help?
Triet H. M. Le, M. Ali Babar
Background: Software Vulnerability (SV) assessment is increasingly adopted to address the ever-increasing volume and complexity of SVs. Data-driven approaches have been widely used to automate SV assessment tasks, particularly the prediction of the Common Vulnerability Scoring System (CVSS) metrics such as exploitability, impact, and severity. SV assessment suffers from the imbalanced distributions of the CVSS classes, but such data imbalance has been hardly understood and addressed in the literature. Aims: We conduct a large-scale study to quantify the impacts of data imbalance and mitigate the issue for SV assessment through the use of data augmentation. Method: We leverage nine data augmentation techniques to balance the class distributions of the CVSS metrics. We then compare the performance of SV assessment models with and without leveraging the augmented data. Results: Through extensive experiments on 180k+ real-world SVs, we show that mitigating data imbalance can significantly improve the predictive performance of models for all the CVSS tasks, by up to 31.8% in Matthews Correlation Coefficient. We also discover that simple text augmentation like combining random text insertion, deletion, and replacement can outperform the baseline across the board. Conclusions: Our study provides the motivation and the first promising step toward tackling data imbalance for effective SV assessment.
Read more7/16/2024

0
Systematic Evaluation of Synthetic Data Augmentation for Multi-class NetFlow Traffic
Maximilian Wolf, Dieter Landes, Andreas Hotho, Daniel Schlor
The detection of cyber-attacks in computer networks is a crucial and ongoing research challenge. Machine learning-based attack classification offers a promising solution, as these models can be continuously updated with new data, enhancing the effectiveness of network intrusion detection systems (NIDS). Unlike binary classification models that simply indicate the presence of an attack, multi-class models can identify specific types of attacks, allowing for more targeted and effective incident responses. However, a significant drawback of these classification models is their sensitivity to imbalanced training data. Recent advances suggest that generative models can assist in data augmentation, claiming to offer superior solutions for imbalanced datasets. Classical balancing methods, although less novel, also provide potential remedies for this issue. Despite these claims, a comprehensive comparison of these methods within the NIDS domain is lacking. Most existing studies focus narrowly on individual methods, making it difficult to compare results due to varying experimental setups. To close this gap, we designed a systematic framework to compare classical and generative resampling methods for class balancing across multiple popular classification models in the NIDS domain, evaluated on several NIDS benchmark datasets. Our experiments indicate that resampling methods for balancing training data do not reliably improve classification performance. Although some instances show performance improvements, the majority of results indicate decreased performance, with no consistent trend in favor of a specific resampling technique enhancing a particular classifier.
Read more8/30/2024
0
New!Enhancing Image Classification in Small and Unbalanced Datasets through Synthetic Data Augmentation
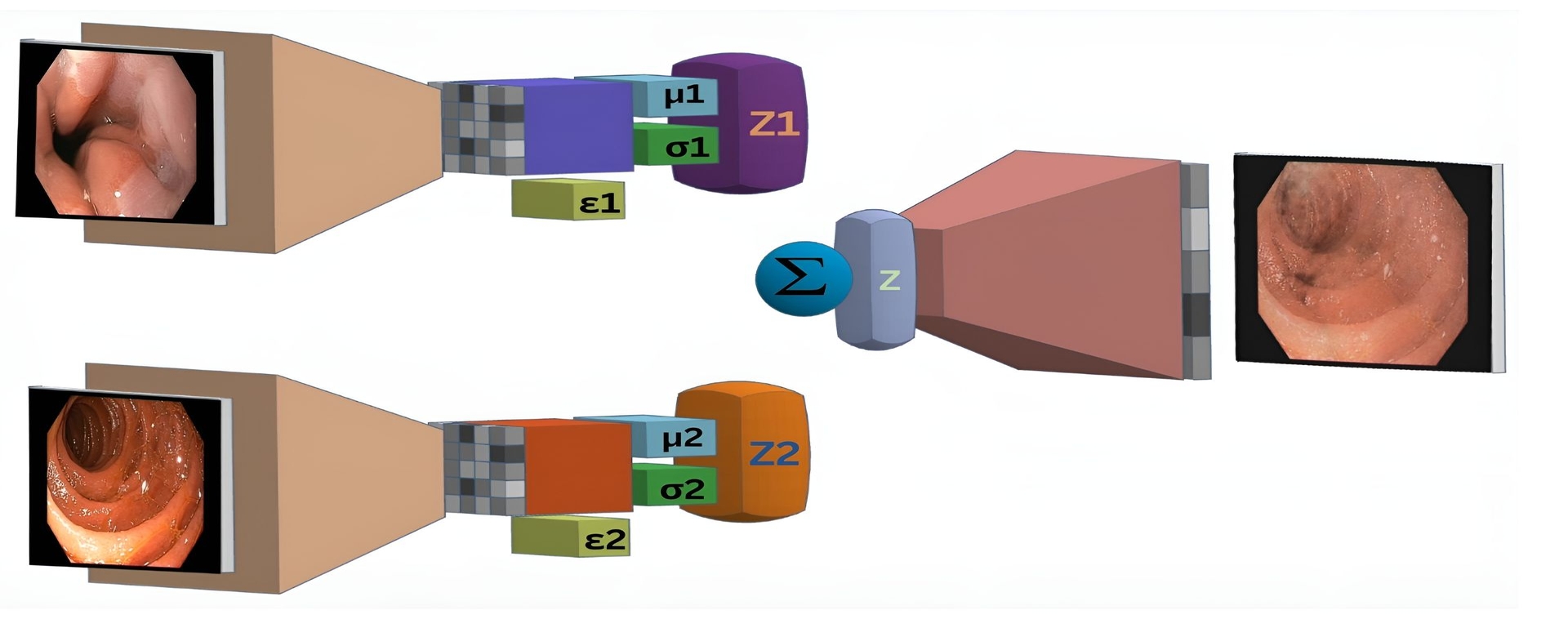
Neil De La Fuente, Mireia Maj'o, Irina Luzko, Henry C'ordova, Gloria Fern'andez-Esparrach, Jorge Bernal
Accurate and robust medical image classification is a challenging task, especially in application domains where available annotated datasets are small and present high imbalance between target classes. Considering that data acquisition is not always feasible, especially for underrepresented classes, our approach introduces a novel synthetic augmentation strategy using class-specific Variational Autoencoders (VAEs) and latent space interpolation to improve discrimination capabilities. By generating realistic, varied synthetic data that fills feature space gaps, we address issues of data scarcity and class imbalance. The method presented in this paper relies on the interpolation of latent representations within each class, thus enriching the training set and improving the model's generalizability and diagnostic accuracy. The proposed strategy was tested in a small dataset of 321 images created to train and validate an automatic method for assessing the quality of cleanliness of esophagogastroduodenoscopy images. By combining real and synthetic data, an increase of over 18% in the accuracy of the most challenging underrepresented class was observed. The proposed strategy not only benefited the underrepresented class but also led to a general improvement in other metrics, including a 6% increase in global accuracy and precision.
Read more9/17/2024
0
Time Series Data Augmentation as an Imbalanced Learning Problem
Vitor Cerqueira, Nuno Moniz, Ricardo In'acio, Carlos Soares
Recent state-of-the-art forecasting methods are trained on collections of time series. These methods, often referred to as global models, can capture common patterns in different time series to improve their generalization performance. However, they require large amounts of data that might not be readily available. Besides this, global models sometimes fail to capture relevant patterns unique to a particular time series. In these cases, data augmentation can be useful to increase the sample size of time series datasets. The main contribution of this work is a novel method for generating univariate time series synthetic samples. Our approach stems from the insight that the observations concerning a particular time series of interest represent only a small fraction of all observations. In this context, we frame the problem of training a forecasting model as an imbalanced learning task. Oversampling strategies are popular approaches used to deal with the imbalance problem in machine learning. We use these techniques to create synthetic time series observations and improve the accuracy of forecasting models. We carried out experiments using 7 different databases that contain a total of 5502 univariate time series. We found that the proposed solution outperforms both a global and a local model, thus providing a better trade-off between these two approaches.
Read more4/30/2024