MM-SAP: A Comprehensive Benchmark for Assessing Self-Awareness of Multimodal Large Language Models in Perception

0

Sign in to get full access
Overview
- This paper introduces a new benchmark called MM-SAP (Multimodal Self-Awareness Perception) for assessing the self-awareness capabilities of multimodal large language models (MLLMs) in perception tasks.
- The authors argue that as MLLMs become more capable, it is crucial to understand their self-awareness, which can impact their reliability and safety.
- MM-SAP is designed to evaluate an MLLM's ability to perceive its own limitations, uncertainties, and potential biases when processing multimodal inputs.
Plain English Explanation
The researchers have created a new way to test multimodal large language models - advanced AI systems that can understand and generate human-like language as well as process images, video, and other media. Specifically, this new "benchmark" called MM-SAP is meant to assess how self-aware these models are when perceiving and interpreting different types of information.
Self-awareness is an important quality for these powerful AI systems to have. As they become more capable, it's crucial to understand if they can recognize their own limitations, uncertainties, and potential biases. This affects how reliable and safe the models are when used in real-world applications.
The MM-SAP benchmark puts the models through a series of tasks that test their self-awareness in multimodal (text + image, etc.) scenarios. For example, the models might be shown an image and asked to describe what they see, but also indicate how confident they are in their interpretation and whether they think they might be missing or misinterpreting anything. This allows the researchers to gauge the model's self-awareness and transparency, rather than just its raw performance.
Technical Explanation
The paper introduces the MM-SAP benchmark for assessing the self-awareness capabilities of multimodal large language models (MLLMs). The authors argue that as MLLMs become more advanced and are deployed in high-stakes applications, it is critical to understand their self-awareness, as this can impact their reliability and safety.
MM-SAP is designed to evaluate an MLLM's ability to perceive its own limitations, uncertainties, and potential biases when processing multimodal inputs (e.g., text and images). The benchmark consists of a suite of tasks that probe different aspects of self-awareness, such as the model's confidence in its outputs, its ability to identify its mistakes, and its awareness of potential biases in its training data.
The paper provides detailed descriptions of the different task types in MM-SAP, which include:
- Multimodal Perception: Tasks that require the model to interpret and describe multimodal inputs, while also assessing its confidence and self-awareness.
- Multimodal Anomaly Detection: Tasks that test the model's ability to detect anomalies or out-of-distribution inputs in multimodal data.
- Multimodal Bias Identification: Tasks that evaluate the model's awareness of potential biases in its training data and outputs.
The authors also present an initial evaluation of several state-of-the-art MLLM models on the MM-SAP benchmark, providing insights into their self-awareness capabilities and areas for improvement.
Critical Analysis
The MM-SAP benchmark proposed in this paper is a valuable contribution to the field of multimodal large language models. Assessing self-awareness is an important but often overlooked aspect of these powerful AI systems, and the authors rightly identify the need to better understand this capability as MLLMs become more advanced and widely deployed.
One potential limitation of the current MM-SAP benchmark is the scope of the tasks and evaluation. While the authors cover a range of self-awareness aspects, there may be other facets, such as the model's ability to explain its reasoning or to learn from feedback, that are not directly addressed. Additionally, the evaluation in the paper is limited to a few state-of-the-art MLLM models, and more comprehensive testing across a wider range of systems would be beneficial.
Another area for potential improvement is the incorporation of more real-world or domain-specific tasks into the benchmark. While the current tasks are well-designed, adding scenarios that more closely mimic actual deployment conditions could provide additional insights into the self-awareness capabilities of MLLMs.
Conclusion
The MM-SAP benchmark proposed in this paper represents an important step forward in understanding the self-awareness capabilities of multimodal large language models. As these AI systems become more advanced and widespread, it is crucial to have rigorous evaluation frameworks that can assess not just their raw performance, but also their ability to perceive their own limitations and potential biases.
The MM-SAP benchmark provides a comprehensive set of tasks that probe different aspects of self-awareness, and the authors' initial evaluation of state-of-the-art models offers valuable insights. While there are opportunities for further development and expansion of the benchmark, this work lays the groundwork for more transparent and accountable deployment of MLLMs in high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MM-SAP: A Comprehensive Benchmark for Assessing Self-Awareness of Multimodal Large Language Models in Perception
Yuhao Wang, Yusheng Liao, Heyang Liu, Hongcheng Liu, Yu Wang, Yanfeng Wang
Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in visual perception and understanding. However, these models also suffer from hallucinations, which limit their reliability as AI systems. We believe that these hallucinations are partially due to the models' struggle with understanding what they can and cannot perceive from images, a capability we refer to as self-awareness in perception. Despite its importance, this aspect of MLLMs has been overlooked in prior studies. In this paper, we aim to define and evaluate the self-awareness of MLLMs in perception. To do this, we first introduce the knowledge quadrant in perception, which helps define what MLLMs know and do not know about images. Using this framework, we propose a novel benchmark, the Self-Awareness in Perception for MLLMs (MM-SAP), specifically designed to assess this capability. We apply MM-SAP to a variety of popular MLLMs, offering a comprehensive analysis of their self-awareness and providing detailed insights. The experiment results reveal that current MLLMs possess limited self-awareness capabilities, pointing to a crucial area for future advancement in the development of trustworthy MLLMs. Code and data are available at https://github.com/YHWmz/MM-SAP.
Read more6/4/2024
0
Explore the Hallucination on Low-level Perception for MLLMs
Yinan Sun, Zicheng Zhang, Haoning Wu, Xiaohong Liu, Weisi Lin, Guangtao Zhai, Xiongkuo Min
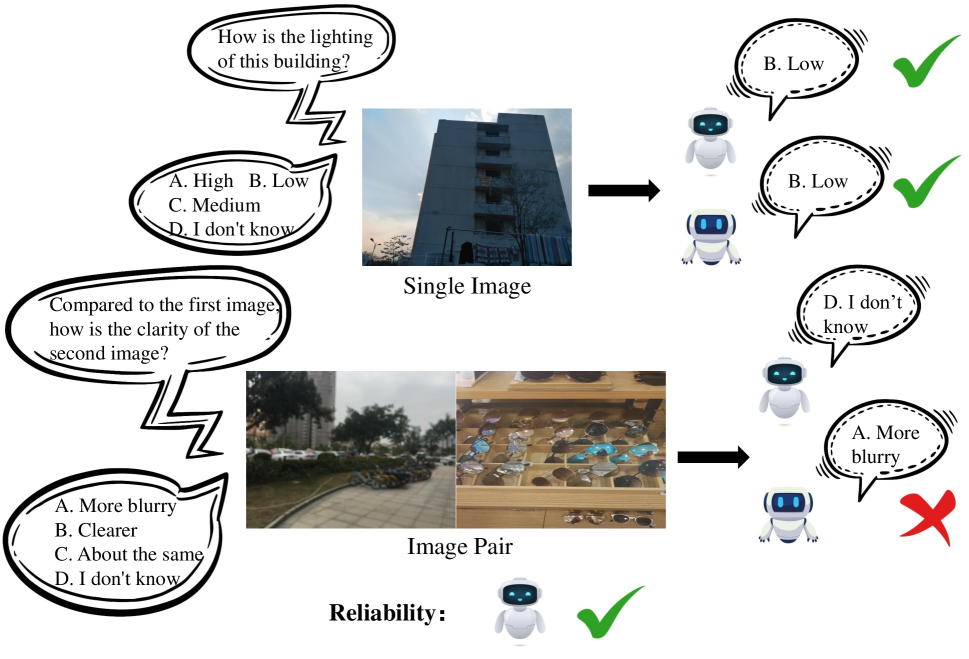
The rapid development of Multi-modality Large Language Models (MLLMs) has significantly influenced various aspects of industry and daily life, showcasing impressive capabilities in visual perception and understanding. However, these models also exhibit hallucinations, which limit their reliability as AI systems, especially in tasks involving low-level visual perception and understanding. We believe that hallucinations stem from a lack of explicit self-awareness in these models, which directly impacts their overall performance. In this paper, we aim to define and evaluate the self-awareness of MLLMs in low-level visual perception and understanding tasks. To this end, we present QL-Bench, a benchmark settings to simulate human responses to low-level vision, investigating self-awareness in low-level visual perception through visual question answering related to low-level attributes such as clarity and lighting. Specifically, we construct the LLSAVisionQA dataset, comprising 2,990 single images and 1,999 image pairs, each accompanied by an open-ended question about its low-level features. Through the evaluation of 15 MLLMs, we demonstrate that while some models exhibit robust low-level visual capabilities, their self-awareness remains relatively underdeveloped. Notably, for the same model, simpler questions are often answered more accurately than complex ones. However, self-awareness appears to improve when addressing more challenging questions. We hope that our benchmark will motivate further research, particularly focused on enhancing the self-awareness of MLLMs in tasks involving low-level visual perception and understanding.
Read more9/17/2024
0
LLM-SAP: Large Language Models Situational Awareness Based Planning
Liman Wang, Hanyang Zhong
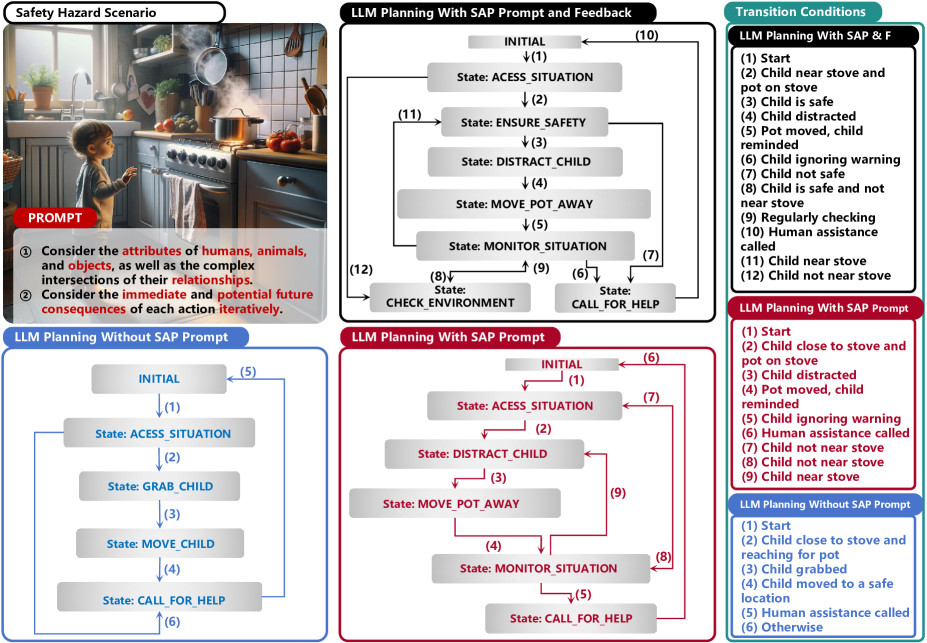
This study explores integrating large language models (LLMs) with situational awareness-based planning (SAP) to enhance the decision-making capabilities of AI agents in dynamic and uncertain environments. We employ a multi-agent reasoning framework to develop a methodology that anticipates and actively mitigates potential risks through iterative feedback and evaluation processes. Our approach diverges from traditional automata theory by incorporating the complexity of human-centric interactions into the planning process, thereby expanding the planning scope of LLMs beyond structured and predictable scenarios. The results demonstrate significant improvements in the model's ability to provide comparative safe actions within hazard interactions, offering a perspective on proactive and reactive planning strategies. This research highlights the potential of LLMs to perform human-like action planning, thereby paving the way for more sophisticated, reliable, and safe AI systems in unpredictable real-world applications.
Read more6/18/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024