Model Ensembling for Constrained Optimization

0

Sign in to get full access
Overview
- This paper presents a model ensembling approach for tackling constrained optimization problems.
- The authors propose a method that combines multiple models to improve the optimization performance under constraints.
- The paper explores the benefits of model ensembling in the context of constrained optimization tasks.
Plain English Explanation
Optimization problems often come with constraints, such as limited resources or specific requirements that need to be met. In these cases, finding the optimal solution can be challenging. The authors of this paper introduce a novel approach to address this challenge.
Their method involves using multiple machine learning models together, rather than relying on a single model. By combining the strengths of different models, the authors demonstrate that the optimization performance can be enhanced while still satisfying the given constraints.
This model ensembling technique can be particularly useful in scenarios where the optimization problem is complex or the constraints are not well-defined. By leveraging the diverse perspectives and capabilities of multiple models, the method can navigate the search space more effectively and find solutions that better meet the required criteria.
The authors' approach can be applied to a wide range of constrained optimization problems, from resource allocation to scheduling and beyond. By providing a more robust and reliable solution, this research has the potential to significantly impact various industries and applications.
Technical Explanation
The paper presents a framework for model ensembling in the context of constrained optimization. The authors propose a method that combines multiple machine learning models to tackle optimization problems with constraints.
The key idea is to leverage the strengths of different models to improve the overall optimization performance. The authors introduce a two-stage approach:
- Model Training: The researchers train multiple models, each with its own unique architecture and learning algorithms, to solve the constrained optimization problem.
- Ensemble Optimization: The authors then combine the predictions from the trained models using an ensemble technique, such as weighted averaging or majority voting. This ensemble approach allows the system to make more informed decisions while satisfying the given constraints.
The authors evaluate their method on a range of benchmark optimization problems and demonstrate its effectiveness in comparison to single-model approaches. The ensemble-based solution is shown to outperform individual models, particularly in scenarios with complex constraints or noisy data.
The paper provides valuable insights into the benefits of model ensembling for constrained optimization tasks. By combining the strengths of multiple models, the authors show that the optimization process can be made more robust, reliable, and effective in finding solutions that meet the required constraints.
Critical Analysis
The paper presents a well-designed and thorough investigation of the proposed model ensembling approach for constrained optimization. The authors have clearly articulated the motivation and the potential benefits of their method, and the experimental results provide strong evidence to support their claims.
One potential limitation discussed in the paper is the computational overhead associated with training and combining multiple models. The authors acknowledge that this tradeoff may need to be carefully considered, especially in time-sensitive or resource-constrained applications.
Additionally, the paper does not explore the interpretability of the ensemble model, which could be an important consideration in certain domains where the decision-making process needs to be transparent. Further research into explainable ensemble models for constrained optimization could be a valuable direction for future work.
Overall, the research presented in this paper makes a significant contribution to the field of constrained optimization and demonstrates the potential of leveraging model ensembling techniques to enhance optimization performance. The findings and insights from this study can be broadly applicable to a wide range of real-world optimization challenges.
Conclusion
The paper introduces a novel approach to tackling constrained optimization problems by leveraging the power of model ensembling. The authors have shown that combining multiple machine learning models can significantly improve the optimization performance while still satisfying the given constraints.
This research has important implications for a wide range of applications, from resource allocation and scheduling to design optimization and decision-making. By providing a more robust and reliable solution, the proposed method has the potential to drive advancements in various industries and create new opportunities for impactful optimization-based solutions.
The successful demonstration of the ensemble-based approach in this paper opens up avenues for further exploration and refinement of the technique. Investigating ways to enhance the interpretability of the ensemble models and exploring the application of this method to even more complex optimization problems could be fruitful directions for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Model Ensembling for Constrained Optimization
Ira Globus-Harris, Varun Gupta, Michael Kearns, Aaron Roth
There is a long history in machine learning of model ensembling, beginning with boosting and bagging and continuing to the present day. Much of this history has focused on combining models for classification and regression, but recently there is interest in more complex settings such as ensembling policies in reinforcement learning. Strong connections have also emerged between ensembling and multicalibration techniques. In this work, we further investigate these themes by considering a setting in which we wish to ensemble models for multidimensional output predictions that are in turn used for downstream optimization. More precisely, we imagine we are given a number of models mapping a state space to multidimensional real-valued predictions. These predictions form the coefficients of a linear objective that we would like to optimize under specified constraints. The fundamental question we address is how to improve and combine such models in a way that outperforms the best of them in the downstream optimization problem. We apply multicalibration techniques that lead to two provably efficient and convergent algorithms. The first of these (the white box approach) requires being given models that map states to output predictions, while the second (the emph{black box} approach) requires only policies (mappings from states to solutions to the optimization problem). For both, we provide convergence and utility guarantees. We conclude by investigating the performance and behavior of the two algorithms in a controlled experimental setting.
Read more5/28/2024

0
Scalable Ensembling For Mitigating Reward Overoptimisation
Ahmed M. Ahmed, Rafael Rafailov, Stepan Sharkov, Xuechen Li, Sanmi Koyejo
Reinforcement Learning from Human Feedback (RLHF) has enabled significant advancements within language modeling for powerful, instruction-following models. However, the alignment of these models remains a pressing challenge as the policy tends to overfit the learned ``proxy reward model past an inflection point of utility as measured by a ``gold reward model that is more performant -- a phenomenon known as overoptimisation. Prior work has mitigated this issue by computing a pessimistic statistic over an ensemble of reward models, which is common in Offline Reinforcement Learning but incredibly costly for language models with high memory requirements, making such approaches infeasible for sufficiently large models. To this end, we propose using a shared encoder but separate linear heads. We find this leads to similar performance as the full ensemble while allowing tremendous savings in memory and time required for training for models of similar size.
Read more6/21/2024

0
Achieving More with Less: A Tensor-Optimization-Powered Ensemble Method
Jinghui Yuan, Weijin Jiang, Zhe Cao, Fangyuan Xie, Rong Wang, Feiping Nie, Yuan Yuan
Ensemble learning is a method that leverages weak learners to produce a strong learner. However, obtaining a large number of base learners requires substantial time and computational resources. Therefore, it is meaningful to study how to achieve the performance typically obtained with many base learners using only a few. We argue that to achieve this, it is essential to enhance both classification performance and generalization ability during the ensemble process. To increase model accuracy, each weak base learner needs to be more efficiently integrated. It is observed that different base learners exhibit varying levels of accuracy in predicting different classes. To capitalize on this, we introduce confidence tensors $tilde{mathbf{Theta}}$ and $tilde{mathbf{Theta}}_{rst}$ signifies the degree of confidence that the $t$-th base classifier assigns the sample to class $r$ while it actually belongs to class $s$. To the best of our knowledge, this is the first time an evaluation of the performance of base classifiers across different classes has been proposed. The proposed confidence tensor compensates for the strengths and weaknesses of each base classifier in different classes, enabling the method to achieve superior results with a smaller number of base learners. To enhance generalization performance, we design a smooth and convex objective function that leverages the concept of margin, making the strong learner more discriminative. Furthermore, it is proved that in gradient matrix of the loss function, the sum of each column's elements is zero, allowing us to solve a constrained optimization problem using gradient-based methods. We then compare our algorithm with random forests of ten times the size and other classical methods across numerous datasets, demonstrating the superiority of our approach.
Read more8/13/2024
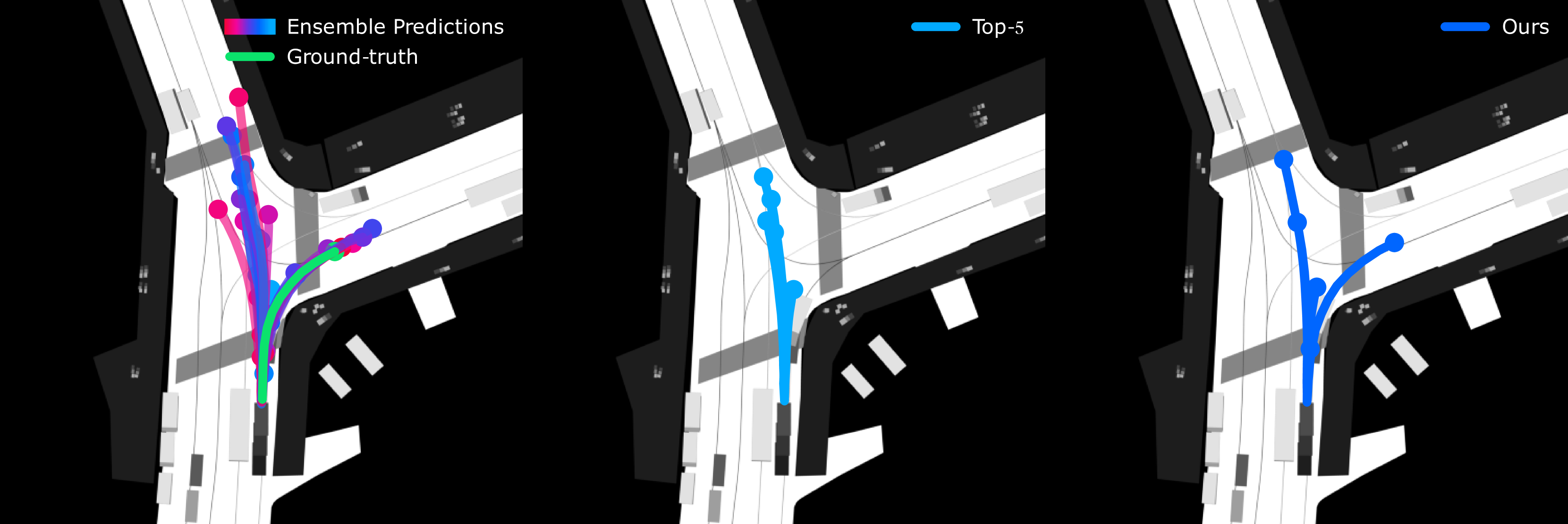
0
Motion Forecasting via Model-Based Risk Minimization
Aron Distelzweig, Eitan Kosman, Andreas Look, Faris Janjov{s}, Denesh K. Manivannan, Abhinav Valada
Forecasting the future trajectories of surrounding agents is crucial for autonomous vehicles to ensure safe, efficient, and comfortable route planning. While model ensembling has improved prediction accuracy in various fields, its application in trajectory prediction is limited due to the multi-modal nature of predictions. In this paper, we propose a novel sampling method applicable to trajectory prediction based on the predictions of multiple models. We first show that conventional sampling based on predicted probabilities can degrade performance due to missing alignment between models. To address this problem, we introduce a new method that generates optimal trajectories from a set of neural networks, framing it as a risk minimization problem with a variable loss function. By using state-of-the-art models as base learners, our approach constructs diverse and effective ensembles for optimal trajectory sampling. Extensive experiments on the nuScenes prediction dataset demonstrate that our method surpasses current state-of-the-art techniques, achieving top ranks on the leaderboard. We also provide a comprehensive empirical study on ensembling strategies, offering insights into their effectiveness. Our findings highlight the potential of advanced ensembling techniques in trajectory prediction, significantly improving predictive performance and paving the way for more reliable predicted trajectories.
Read more9/23/2024