MoEUT: Mixture-of-Experts Universal Transformers
2405.16039
1
0
Abstract
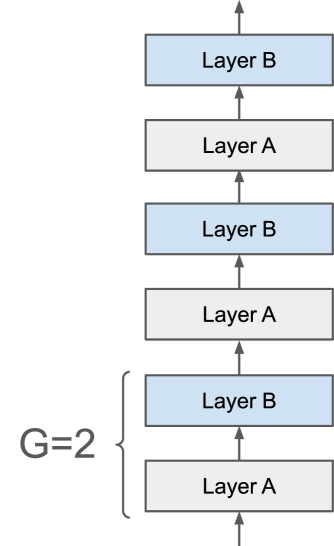
Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in learning compositional generalizations, but layer-sharing comes with a practical limitation of parameter-compute ratio: it drastically reduces the parameter count compared to the non-shared model with the same dimensionality. Naively scaling up the layer size to compensate for the loss of parameters makes its computational resource requirements prohibitive. In practice, no previous work has succeeded in proposing a shared-layer Transformer design that is competitive in parameter count-dominated tasks such as language modeling. Here we propose MoEUT (pronounced moot), an effective mixture-of-experts (MoE)-based shared-layer Transformer architecture, which combines several recent advances in MoEs for both feedforward and attention layers of standard Transformers together with novel layer-normalization and grouping schemes that are specific and crucial to UTs. The resulting UT model, for the first time, slightly outperforms standard Transformers on language modeling tasks such as BLiMP and PIQA, while using significantly less compute and memory.
Create account to get full access
Overview
- Introduces a novel architecture called Mixture-of-Experts Universal Transformers (MoEUT) for efficiently scaling up large language models
- Outlines how MoEUT can achieve significant parameter scaling with minimal impact on performance across diverse tasks
- Highlights MoEUT's potential for enabling more powerful and versatile universal language models
Plain English Explanation
The paper presents a new AI model architecture called Mixture-of-Experts Universal Transformers (MoEUT) that can dramatically increase the size and capabilities of large language models while maintaining their performance. Traditional language models have been limited in how much they can be scaled up, as increasing the number of parameters often leads to diminishing returns or even reduced performance.
MoEUT addresses this challenge by using a "mixture-of-experts" approach, where the model has multiple specialized sub-networks (called "experts") that each focus on different parts of the input data. This allows the overall model to have many more parameters and learn more complex patterns, without as much risk of overfitting or performance degradation.
The researchers show that MoEUT can scale up to [object Object] compared to previous state-of-the-art models, with only minimal impact on performance across a wide range of natural language tasks. This suggests MoEUT could enable the development of even more powerful and versatile [object Object] in the future.
Technical Explanation
The core innovation of the MoEUT architecture is its use of a mixture-of-experts (MoE) approach. Rather than having a single monolithic transformer network, MoEUT consists of multiple "expert" sub-networks that each specialize in different aspects of the input data.
An [object Object] dynamically routes the input through the appropriate experts based on the current context. This allows the model to leverage the combined capacity of all the experts, while still maintaining the ability to focus on relevant aspects of the input.
The researchers demonstrate that MoEUT can effectively [object Object] by 47x compared to previous state-of-the-art models, with only a minimal impact on performance. This is a significant advance, as large language models have traditionally struggled to maintain their capabilities as they grow in size.
Critical Analysis
The paper provides a thorough technical evaluation of the MoEUT architecture, including extensive comparisons to baseline models across a wide range of natural language tasks. The results demonstrate the effectiveness of the mixture-of-experts approach for enabling parameter scaling with minimal performance degradation.
However, the paper does not delve deeply into the potential limitations or drawbacks of the MoEUT approach. For example, it is not clear how the computational and memory overhead of the gating network and multiple expert sub-networks might impact real-world deployment, especially on resource-constrained devices.
Additionally, the paper does not explore potential biases or lack of robustness that could arise from the specialized nature of the expert sub-networks. Further research would be needed to understand how these factors might affect the practical application of MoEUT in diverse real-world scenarios.
Conclusion
The MoEUT architecture represents an important advance in the field of large language models, demonstrating a novel approach to [object Object] with minimal impact on performance.
If the promising results in this paper hold true in further research and real-world deployments, MoEUT could pave the way for the development of even more powerful and versatile universal language models capable of tackling an increasingly broad range of tasks and applications. However, potential limitations and tradeoffs would need to be carefully evaluated to ensure the safe and responsible use of such highly capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
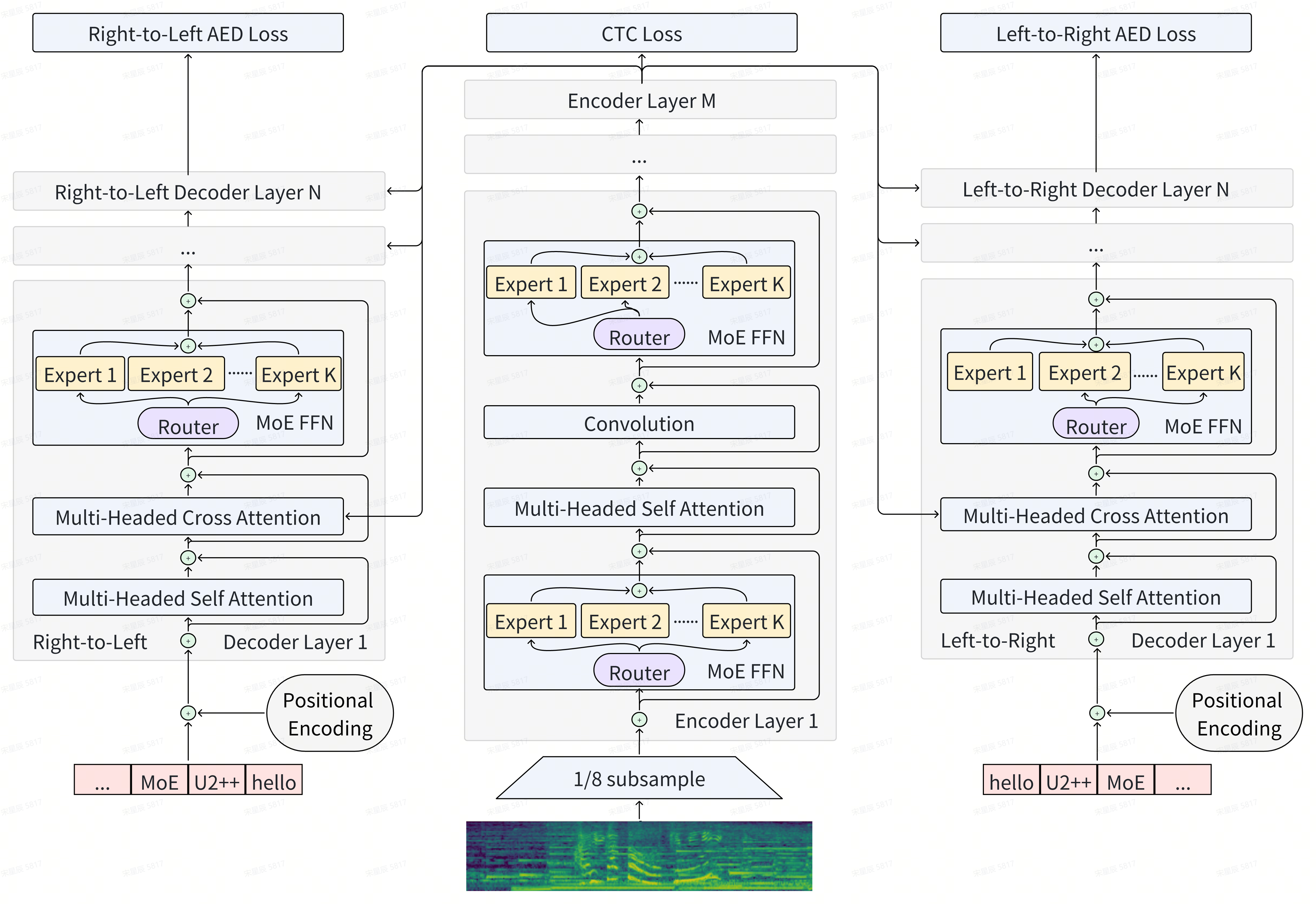
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
Xingchen Song, Di Wu, Binbin Zhang, Dinghao Zhou, Zhendong Peng, Bo Dang, Fuping Pan, Chao Yang
0
0
Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
4/26/2024
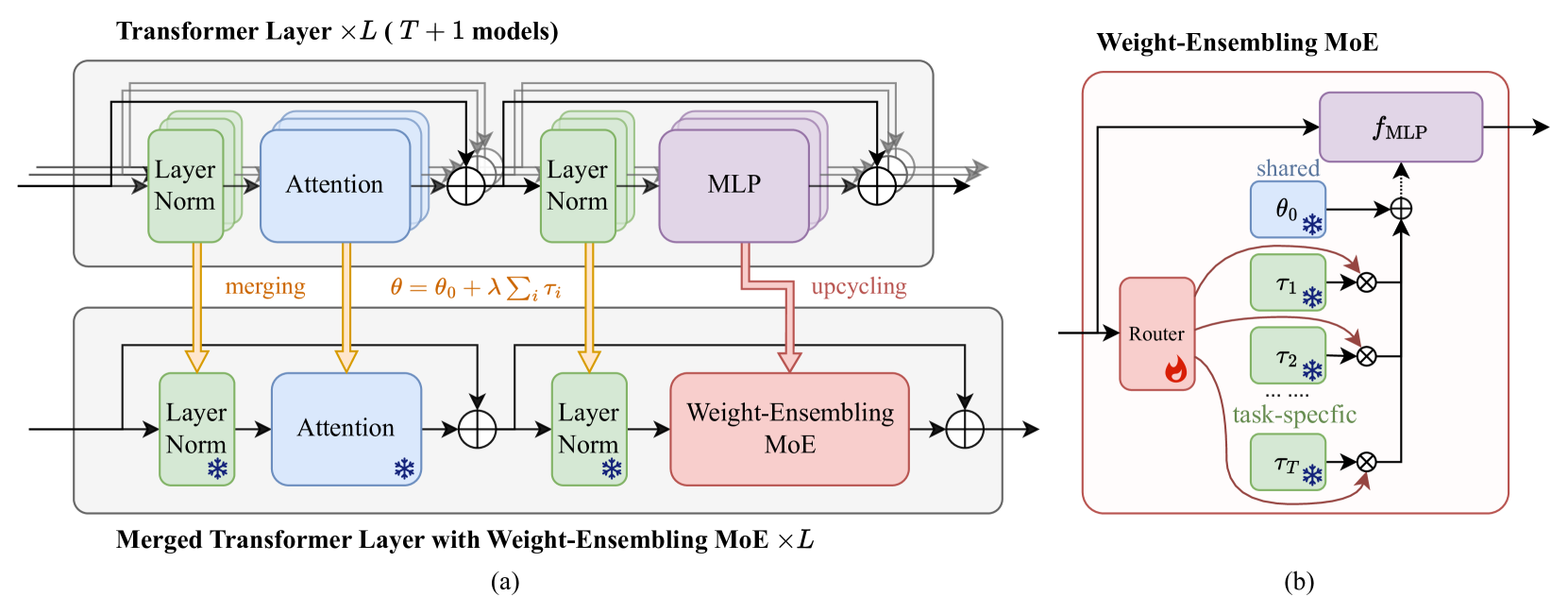
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
0
0
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
6/10/2024
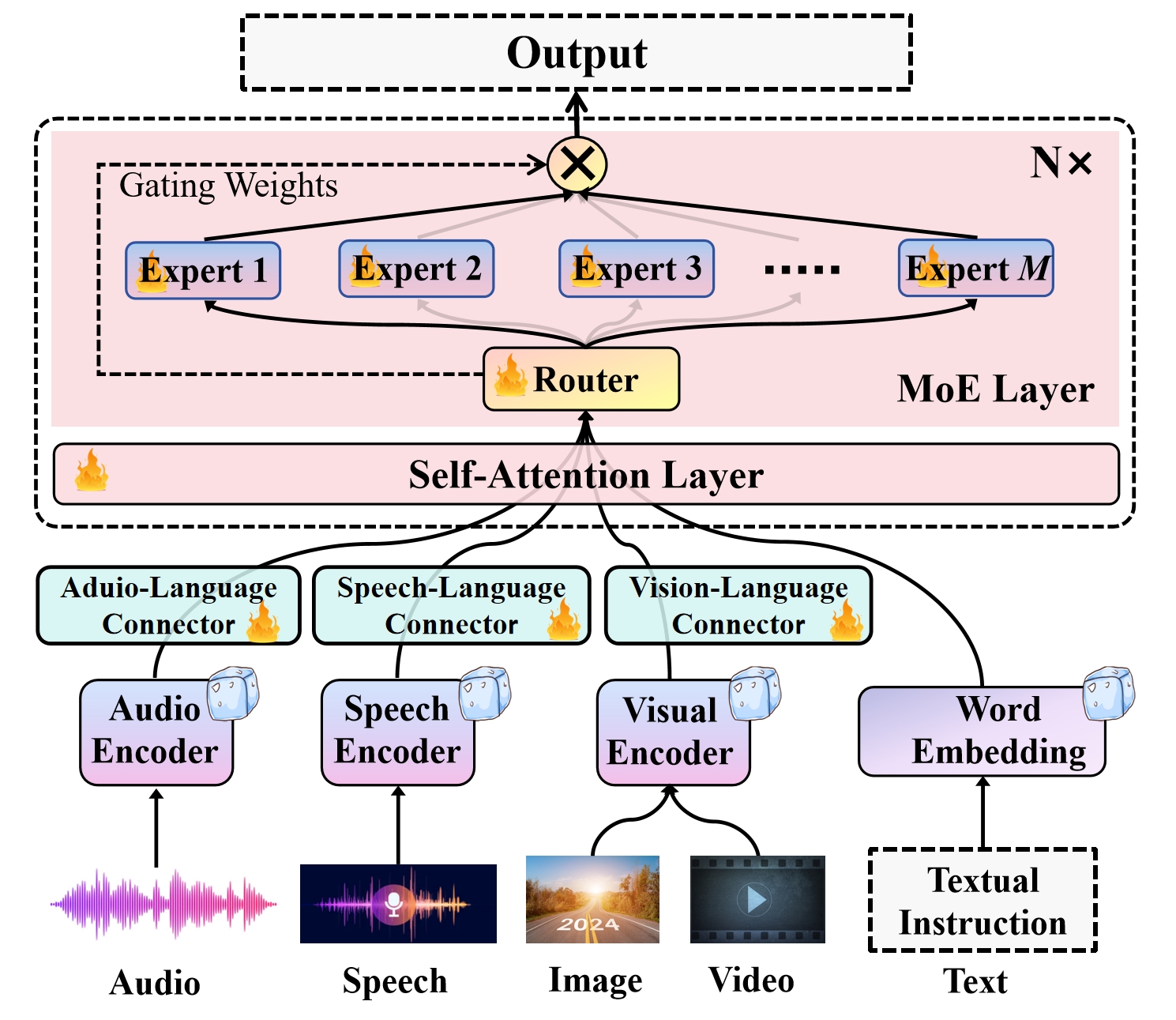
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
0
0
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
5/21/2024
🏋️
Unified Training of Universal Time Series Forecasting Transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, Doyen Sahoo
0
0
Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, data, and model weights can be found at https://github.com/SalesforceAIResearch/uni2ts.
5/24/2024