A Multimodal Automated Interpretability Agent

0

Sign in to get full access
Overview
- This paper introduces a Multimodal Automated Interpretability Agent (MAIA), a system that aims to provide interpretability for deep learning models across different modalities.
- MAIA combines visual and textual explanations to help users understand how a model arrives at its predictions.
- The system was evaluated on a variety of tasks, including image classification, visual question answering, and multimodal sentiment analysis.
Plain English Explanation
MAIA is a tool that helps explain how deep learning models work, especially models that can handle different types of data like images and text. Sometimes it can be hard to understand why a model makes a certain prediction, but MAIA tries to make this clearer by providing both visual and written explanations. For example, if you showed the model an image and asked it to identify what's in the image, MAIA would not only give you the model's prediction, but also highlight the important parts of the image that the model focused on and provide a text description of its reasoning. This can be really helpful for developers, researchers, and even regular users who want to better understand how these powerful AI models make decisions. The key idea behind MAIA is to combine visual and textual explanations to make the inner workings of deep learning models more transparent and accessible to a wide range of users.
Technical Explanation
The core of MAIA is a multimodal explanation module that generates both visual and textual interpretations of a deep learning model's behavior. For the visual explanation, MAIA uses Interaction as Explanation to highlight the most important regions of an input image that contributed to the model's prediction. The textual explanation is generated using a language model fine-tuned on a dataset of human-written model explanations.
MAIA was evaluated on several tasks, including image classification, visual question answering, and multimodal sentiment analysis. The results showed that MAIA's explanations helped users better understand the model's reasoning and improved their trust in the model's outputs. Additionally, the authors found that the visual and textual explanations were complementary, with users benefiting most when both were provided.
Critical Analysis
The MAIA system represents an important step towards making deep learning models more interpretable and transparent. By combining visual and textual explanations, the authors have demonstrated a compelling approach to helping users understand how these complex models arrive at their predictions.
However, the paper does not address some key limitations of the system. For example, the textual explanations are generated by a language model, which may inherit biases or inconsistencies present in the training data. Additionally, the evaluation focused on user perceptions and trust, but did not assess whether the explanations actually improved the users' understanding of the model's inner workings.
Further research is needed to explore more advanced techniques for generating accurate and consistent explanations, as well as to investigate the long-term impacts of such interpretability tools on model development and deployment. Nonetheless, the MAIA system represents an important contribution to the field of Autonomous Artificial Intelligence Agents for Clinical Decision Making and the broader challenge of making AI systems more interpretable and transparent.
Conclusion
The MAIA system introduced in this paper is a promising approach to improving the interpretability of deep learning models by combining visual and textual explanations. By making the reasoning behind model predictions more accessible, MAIA has the potential to enhance user trust, model development, and the responsible deployment of AI systems. While further research is needed to address the system's limitations, the core ideas behind MAIA represent an important step towards LVLM: A Tool for Interpreting Large Vision-Language Models and more transparent and accountable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Multimodal Automated Interpretability Agent
Tamar Rott Shaham, Sarah Schwettmann, Franklin Wang, Achyuta Rajaram, Evan Hernandez, Jacob Andreas, Antonio Torralba
This paper describes MAIA, a Multimodal Automated Interpretability Agent. MAIA is a system that uses neural models to automate neural model understanding tasks like feature interpretation and failure mode discovery. It equips a pre-trained vision-language model with a set of tools that support iterative experimentation on subcomponents of other models to explain their behavior. These include tools commonly used by human interpretability researchers: for synthesizing and editing inputs, computing maximally activating exemplars from real-world datasets, and summarizing and describing experimental results. Interpretability experiments proposed by MAIA compose these tools to describe and explain system behavior. We evaluate applications of MAIA to computer vision models. We first characterize MAIA's ability to describe (neuron-level) features in learned representations of images. Across several trained models and a novel dataset of synthetic vision neurons with paired ground-truth descriptions, MAIA produces descriptions comparable to those generated by expert human experimenters. We then show that MAIA can aid in two additional interpretability tasks: reducing sensitivity to spurious features, and automatically identifying inputs likely to be mis-classified.
Read more4/23/2024
🧠
0
Multimodal Explainable Artificial Intelligence: A Comprehensive Review of Methodological Advances and Future Research Directions
Nikolaos Rodis, Christos Sardianos, Panagiotis Radoglou-Grammatikis, Panagiotis Sarigiannidis, Iraklis Varlamis, Georgios Th. Papadopoulos
Despite the fact that Artificial Intelligence (AI) has boosted the achievement of remarkable results across numerous data analysis tasks, however, this is typically accompanied by a significant shortcoming in the exhibited transparency and trustworthiness of the developed systems. In order to address the latter challenge, the so-called eXplainable AI (XAI) research field has emerged, which aims, among others, at estimating meaningful explanations regarding the employed model reasoning process. The current study focuses on systematically analyzing the recent advances in the area of Multimodal XAI (MXAI), which comprises methods that involve multiple modalities in the primary prediction and explanation tasks. In particular, the relevant AI-boosted prediction tasks and publicly available datasets used for learning/evaluating explanations in multimodal scenarios are initially described. Subsequently, a systematic and comprehensive analysis of the MXAI methods of the literature is provided, taking into account the following key criteria: a) The number of the involved modalities (in the employed AI module), b) The processing stage at which explanations are generated, and c) The type of the adopted methodology (i.e. the actual mechanism and mathematical formalization) for producing explanations. Then, a thorough analysis of the metrics used for MXAI methods evaluation is performed. Finally, an extensive discussion regarding the current challenges and future research directions is provided.
Read more7/2/2024
0
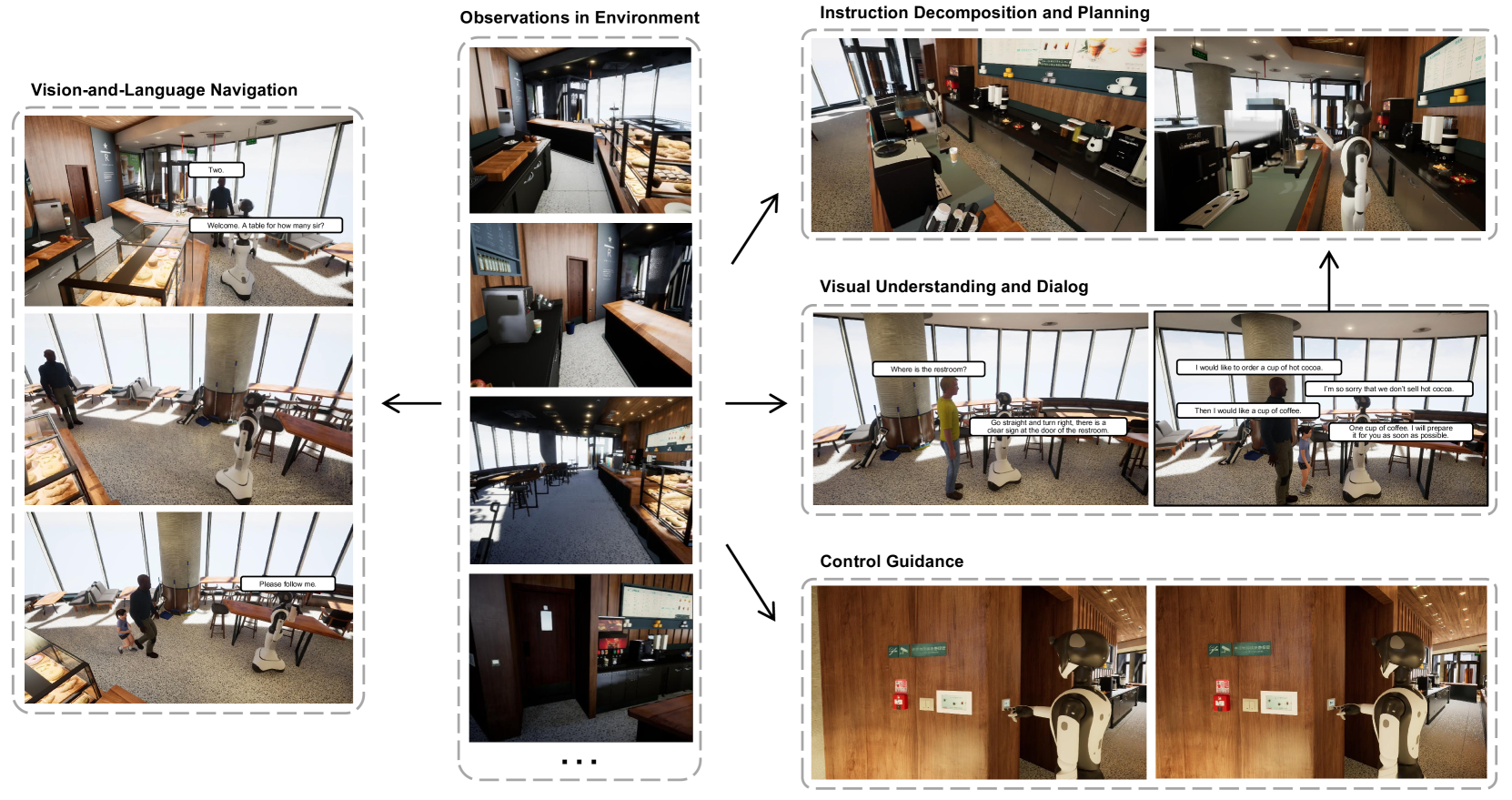
MEIA: Towards Realistic Multimodal Interaction and Manipulation for Embodied Robots
Yang Liu, Xinshuai Song, Kaixuan Jiang, Weixing Chen, Jingzhou Luo, Guanbin Li, Liang Lin
With the surge in the development of large language models, embodied intelligence has attracted increasing attention. Nevertheless, prior works on embodied intelligence typically encode scene or historical memory in an unimodal manner, either visual or linguistic, which complicates the alignment of the model's action planning with embodied control. To overcome this limitation, we introduce the Multimodal Embodied Interactive Agent (MEIA), capable of translating high-level tasks expressed in natural language into a sequence of executable actions. Specifically, we propose a novel Multimodal Environment Memory (MEM) module, facilitating the integration of embodied control with large models through the visual-language memory of scenes. This capability enables MEIA to generate executable action plans based on diverse requirements and the robot's capabilities. Furthermore, we construct an embodied question answering dataset based on a dynamic virtual cafe environment with the help of the large language model. In this virtual environment, we conduct several experiments, utilizing multiple large models through zero-shot learning, and carefully design scenarios for various situations. The experimental results showcase the promising performance of our MEIA in various embodied interactive tasks.
Read more7/30/2024

0
Interaction as Explanation: A User Interaction-based Method for Explaining Image Classification Models
Hyeonggeun Yun
In computer vision, explainable AI (xAI) methods seek to mitigate the 'black-box' problem by making the decision-making process of deep learning models more interpretable and transparent. Traditional xAI methods concentrate on visualizing input features that influence model predictions, providing insights primarily suited for experts. In this work, we present an interaction-based xAI method that enhances user comprehension of image classification models through their interaction. Thus, we developed a web-based prototype allowing users to modify images via painting and erasing, thereby observing changes in classification results. Our approach enables users to discern critical features influencing the model's decision-making process, aligning their mental models with the model's logic. Experiments conducted with five images demonstrate the potential of the method to reveal feature importance through user interaction. Our work contributes a novel perspective to xAI by centering on end-user engagement and understanding, paving the way for more intuitive and accessible explainability in AI systems.
Read more8/15/2024