MEIA: Towards Realistic Multimodal Interaction and Manipulation for Embodied Robots

0
Sign in to get full access
Overview
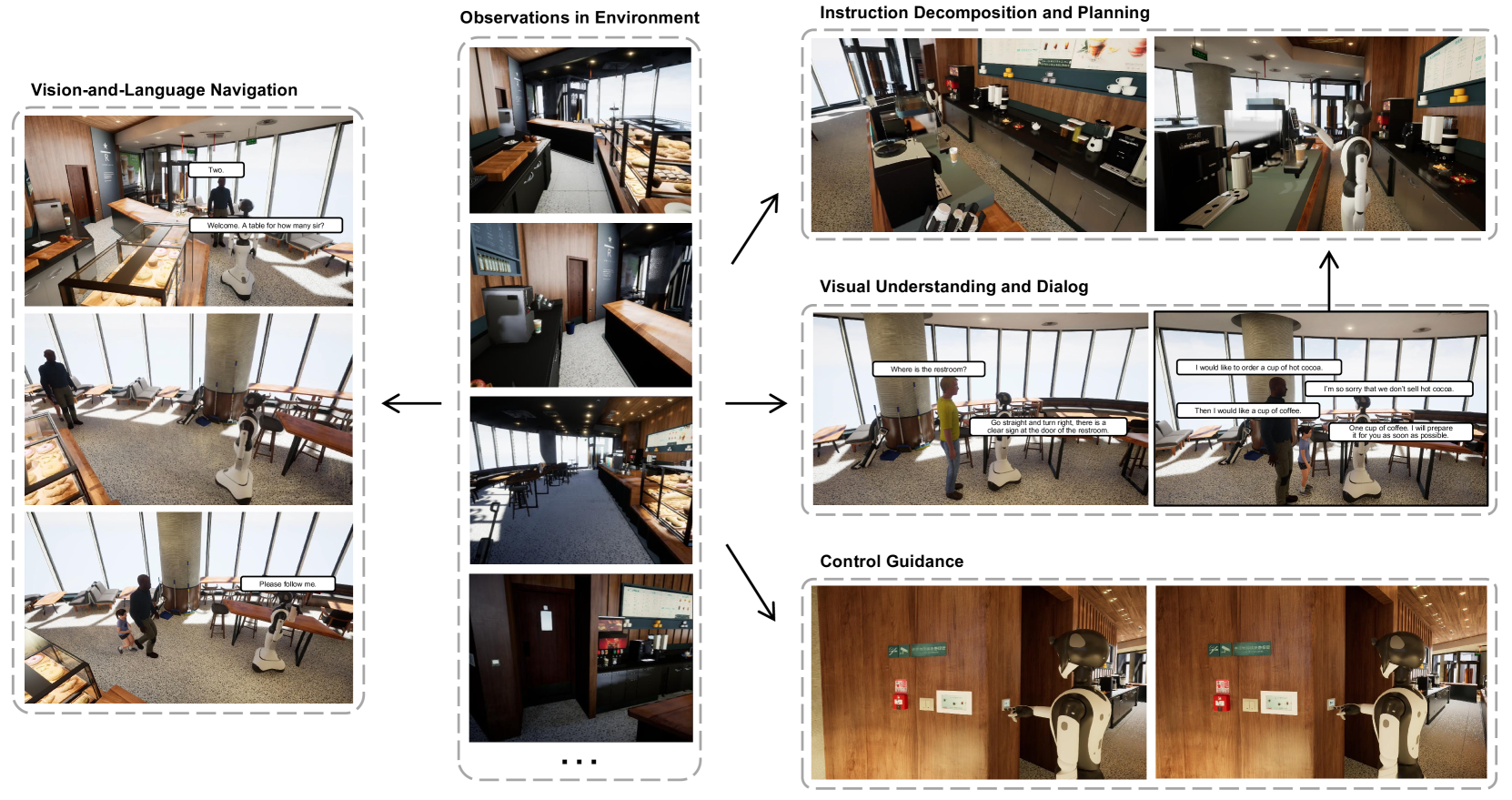
- This paper presents a multimodal embodied interactive agent for a cafe scene, which can engage in natural conversations and perform various tasks.
- The agent combines computer vision, natural language processing, and embodied interaction to create a more realistic and engaging user experience.
- The system is designed to be deployed in a physical cafe setting, where it can interact with customers and assist with order placement, recommendations, and other café-related activities.
Plain English Explanation
The researchers have developed a virtual assistant that can interact with people in a café environment. This assistant can see what's happening around it, understand what people are saying, and respond in a natural way. It's designed to help customers with things like ordering food, making recommendations, and answering questions about the café.
The key innovation is that this assistant isn't just a disembodied voice or text on a screen. It has a virtual body that can move around and gesture, making the interaction feel more natural and lifelike. This embodied interaction allows the assistant to convey information more effectively and engage with people in a more meaningful way.
The assistant uses computer vision to perceive its surroundings and natural language processing to understand what people are saying. It can then formulate appropriate responses and use its virtual body to communicate, just like a human would.
Overall, this system aims to create a more immersive and helpful experience for café customers, by providing a virtual assistant that can truly engage with them in a natural and lifelike way.
Technical Explanation
The researchers have developed a multimodal embodied interactive agent for a café setting. The agent combines computer vision, natural language processing, and embodied interaction to create a more realistic and engaging user experience.
The system is designed to be deployed in a physical café, where it can perceive its environment using computer vision and understand natural language interactions using natural language processing. This allows the agent to engage in natural conversations with customers and perform various café-related tasks, such as order placement, recommendations, and answering questions.
The key innovation of this system is the use of embodied interaction, where the agent has a virtual body that can move and gesture, making the interaction feel more natural and lifelike. This allows the agent to convey information more effectively and engage with people in a more meaningful way.
The system's architecture combines vision-language models and multimodal variational autoencoders to enable the agent's perceptual and conversational capabilities. The researchers have designed the system to be deployed in a real-world café setting, where it can interact with customers and assist with various café-related activities.
Critical Analysis
The researchers have presented a compelling concept for a multimodal embodied interactive agent in a café setting. The use of computer vision, natural language processing, and embodied interaction is an interesting approach to creating a more engaging and lifelike user experience.
However, the paper does not provide detailed information about the system's performance or user evaluations. It would be helpful to know how well the agent performs in real-world café scenarios, and how customers respond to the interaction. Additionally, the paper does not address potential challenges or limitations of the system, such as its scalability, robustness, or ability to handle complex or unexpected situations.
Further research and evaluation would be needed to fully assess the viability and potential impact of this system. It would be interesting to see how the embodied interaction and multimodal capabilities of the agent could be extended to other domains or applications beyond the café setting.
Conclusion
This paper presents a promising concept for a multimodal embodied interactive agent designed for a café setting. By combining computer vision, natural language processing, and embodied interaction, the researchers have created a virtual assistant that can engage with customers in a more natural and lifelike way.
The potential impact of this system is the ability to enhance the customer experience in a café by providing a more personalized and engaging interaction. If further developed and evaluated, this technology could be applied in other service-oriented environments, such as hotels, retail stores, or even in-home assistants.
Overall, this research demonstrates the value of integrating multiple modalities, such as vision, language, and embodied interaction, to create more realistic and effective virtual agents. As large language models and embodied AI continue to advance, the potential for these types of multimodal systems to transform human-computer interaction is substantial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MEIA: Towards Realistic Multimodal Interaction and Manipulation for Embodied Robots
Yang Liu, Xinshuai Song, Kaixuan Jiang, Weixing Chen, Jingzhou Luo, Guanbin Li, Liang Lin
With the surge in the development of large language models, embodied intelligence has attracted increasing attention. Nevertheless, prior works on embodied intelligence typically encode scene or historical memory in an unimodal manner, either visual or linguistic, which complicates the alignment of the model's action planning with embodied control. To overcome this limitation, we introduce the Multimodal Embodied Interactive Agent (MEIA), capable of translating high-level tasks expressed in natural language into a sequence of executable actions. Specifically, we propose a novel Multimodal Environment Memory (MEM) module, facilitating the integration of embodied control with large models through the visual-language memory of scenes. This capability enables MEIA to generate executable action plans based on diverse requirements and the robot's capabilities. Furthermore, we construct an embodied question answering dataset based on a dynamic virtual cafe environment with the help of the large language model. In this virtual environment, we conduct several experiments, utilizing multiple large models through zero-shot learning, and carefully design scenarios for various situations. The experimental results showcase the promising performance of our MEIA in various embodied interactive tasks.
Read more7/30/2024
🤖
0
Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI
Song Yaoxian, Sun Penglei, Liu Haoyu, Li Zhixu, Song Wei, Xiao Yanghua, Zhou Xiaofang
Embodied AI is one of the most popular studies in artificial intelligence and robotics, which can effectively improve the intelligence of real-world agents (i.e. robots) serving human beings. Scene knowledge is important for an agent to understand the surroundings and make correct decisions in the varied open world. Currently, knowledge base for embodied tasks is missing and most existing work use general knowledge base or pre-trained models to enhance the intelligence of an agent. For conventional knowledge base, it is sparse, insufficient in capacity and cost in data collection. For pre-trained models, they face the uncertainty of knowledge and hard maintenance. To overcome the challenges of scene knowledge, we propose a scene-driven multimodal knowledge graph (Scene-MMKG) construction method combining conventional knowledge engineering and large language models. A unified scene knowledge injection framework is introduced for knowledge representation. To evaluate the advantages of our proposed method, we instantiate Scene-MMKG considering typical indoor robotic functionalities (Manipulation and Mobility), named ManipMob-MMKG. Comparisons in characteristics indicate our instantiated ManipMob-MMKG has broad superiority in data-collection efficiency and knowledge quality. Experimental results on typical embodied tasks show that knowledge-enhanced methods using our instantiated ManipMob-MMKG can improve the performance obviously without re-designing model structures complexly. Our project can be found at https://sites.google.com/view/manipmob-mmkg
Read more5/14/2024
🤿
0
Leveraging Intra-modal and Inter-modal Interaction for Multi-Modal Entity Alignment
Zhiwei Hu, V'ictor Guti'errez-Basulto, Zhiliang Xiang, Ru Li, Jeff Z. Pan
Multi-modal entity alignment (MMEA) aims to identify equivalent entity pairs across different multi-modal knowledge graphs (MMKGs). Existing approaches focus on how to better encode and aggregate information from different modalities. However, it is not trivial to leverage multi-modal knowledge in entity alignment due to the modal heterogeneity. In this paper, we propose a Multi-Grained Interaction framework for Multi-Modal Entity Alignment (MIMEA), which effectively realizes multi-granular interaction within the same modality or between different modalities. MIMEA is composed of four modules: i) a Multi-modal Knowledge Embedding module, which extracts modality-specific representations with multiple individual encoders; ii) a Probability-guided Modal Fusion module, which employs a probability guided approach to integrate uni-modal representations into joint-modal embeddings, while considering the interaction between uni-modal representations; iii) an Optimal Transport Modal Alignment module, which introduces an optimal transport mechanism to encourage the interaction between uni-modal and joint-modal embeddings; iv) a Modal-adaptive Contrastive Learning module, which distinguishes the embeddings of equivalent entities from those of non-equivalent ones, for each modality. Extensive experiments conducted on two real-world datasets demonstrate the strong performance of MIMEA compared to the SoTA. Datasets and code have been submitted as supplementary materials.
Read more4/30/2024

0
Retrieval-Augmented Embodied Agents
Yichen Zhu, Zhicai Ou, Xiaofeng Mou, Jian Tang
Embodied agents operating in complex and uncertain environments face considerable challenges. While some advanced agents handle complex manipulation tasks with proficiency, their success often hinges on extensive training data to develop their capabilities. In contrast, humans typically rely on recalling past experiences and analogous situations to solve new problems. Aiming to emulate this human approach in robotics, we introduce the Retrieval-Augmented Embodied Agent (RAEA). This innovative system equips robots with a form of shared memory, significantly enhancing their performance. Our approach integrates a policy retriever, allowing robots to access relevant strategies from an external policy memory bank based on multi-modal inputs. Additionally, a policy generator is employed to assimilate these strategies into the learning process, enabling robots to formulate effective responses to tasks. Extensive testing of RAEA in both simulated and real-world scenarios demonstrates its superior performance over traditional methods, representing a major leap forward in robotic technology.
Read more4/19/2024