No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
2403.06249
0
0

Abstract
While the progression of Large Language Models (LLMs) has notably propelled financial analysis, their application has largely been confined to singular language realms, leaving untapped the potential of bilingual Chinese-English capacity. To bridge this chasm, we introduce ICE-PIXIU, seamlessly amalgamating the ICE-INTENT model and ICE-FLARE benchmark for bilingual financial analysis. ICE-PIXIU uniquely integrates a spectrum of Chinese tasks, alongside translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It provides unrestricted access to diverse model variants, a substantial compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, comprising 10 NLP tasks, 20 bilingual specific tasks, totaling 95k datasets. Our thorough evaluation emphasizes the advantages of incorporating these bilingual datasets, especially in translation tasks and utilizing original English data, enhancing both linguistic flexibility and analytical acuity in financial contexts. Notably, ICE-INTENT distinguishes itself by showcasing significant enhancements over conventional LLMs and existing financial LLMs in bilingual milieus, underscoring the profound impact of robust bilingual data on the accuracy and efficacy of financial NLP.
Create account to get full access
Overview
- This paper presents a framework for unifying Chinese and English in financial large language models (LLMs), instruction data, and benchmarks.
- The researchers aim to address the lack of multilingual capabilities in current LLMs, which are often English-centric, by introducing a unified approach that can benefit both Chinese and English users.
- The proposed method involves cross-lingual pretraining, fine-tuning, and evaluation, with the goal of creating LLMs that can understand and generate content in both Chinese and English.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, most current LLMs are primarily focused on the English language, leaving out other languages like Chinese. This can be a problem for users who need to work with financial information in both Chinese and English.
To address this issue, the researchers in this paper developed a new framework that can unify Chinese and English in financial LLMs, the data used to train them, and the benchmarks used to evaluate their performance. This means creating LLMs that can understand and generate content in both languages, which can be very useful for people who need to work with financial information in multiple languages.
The key steps in their approach include:
- Cross-lingual Pretraining: The researchers first trained the LLM on a large amount of text in both Chinese and English, so that it could understand and generate content in both languages.
- Fine-tuning: They then fine-tuned the model on financial data in both languages, so that it could specialize in understanding financial concepts and terminology.
- Evaluation: Finally, they developed new benchmarks that can test the model's abilities in both Chinese and English, to ensure that it performs well in both languages.
By taking this unified approach, the researchers were able to create LLMs that can be useful for a wider range of users, regardless of their language preferences. This could be particularly helpful for businesses or organizations that need to work with financial information in multiple languages.
Technical Explanation
The researchers approach the problem of unifying Chinese and English in financial LLMs, instruction data, and benchmarks through several key steps:
-
Cross-lingual Pretraining: The researchers pretrain their LLM on a large corpus of text in both Chinese and English, using techniques like SambaLingo to ensure the model can understand and generate content in both languages. This allows the model to build a strong foundation of knowledge across the two languages.
-
Fine-tuning: After pretraining, the researchers fine-tune the model on financial datasets in both Chinese and English, using techniques like Do Large Language Models Understand Multi-Intent? to ensure the model can specialize in financial concepts and terminology. This allows the model to become highly proficient in financial tasks across the two languages.
-
Evaluation: The researchers develop new benchmarks that test the model's abilities in both Chinese and English, using a range of tasks that are relevant to the financial domain. This allows them to rigorously evaluate the model's performance and ensure it is effective in both languages.
By taking this unified approach, the researchers are able to create financial LLMs that can understand and generate content in both Chinese and English. This can be particularly useful for applications where users need to work with financial information in multiple languages, such as in international business or finance.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their work:
- The datasets used for pretraining and fine-tuning may not be fully representative of the diversity of financial data and terminology in the real world. Expanding the dataset coverage could further improve the model's performance.
- The benchmarks developed for evaluation may not capture all the nuances of financial tasks in both languages. Developing more comprehensive and multilingual evaluation suites could provide a deeper understanding of the model's capabilities.
- While the unified approach is a step in the right direction, there may be additional challenges in truly understanding multi-intent or expanding spoken language understanding across languages that require further exploration.
Overall, the researchers' approach represents an important advancement in the field of multilingual LLMs, particularly in the financial domain. However, continued research and refinement will be necessary to fully realize the potential of Chinese-centric large language models and truly multilingual LLMs that can seamlessly serve users across different languages.
Conclusion
This paper presents a framework for unifying Chinese and English in financial large language models, instruction data, and benchmarks. By taking a cross-lingual approach to pretraining, fine-tuning, and evaluation, the researchers have developed LLMs that can understand and generate content in both languages, which can be highly valuable for users who need to work with financial information in multiple languages.
The key contributions of this work include the development of effective techniques for cross-lingual training and evaluation, as well as the creation of new benchmarks that can assess the performance of financial LLMs in both Chinese and English. While the researchers acknowledge some limitations, this research represents an important step towards more inclusive and multilingual AI systems in the financial domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
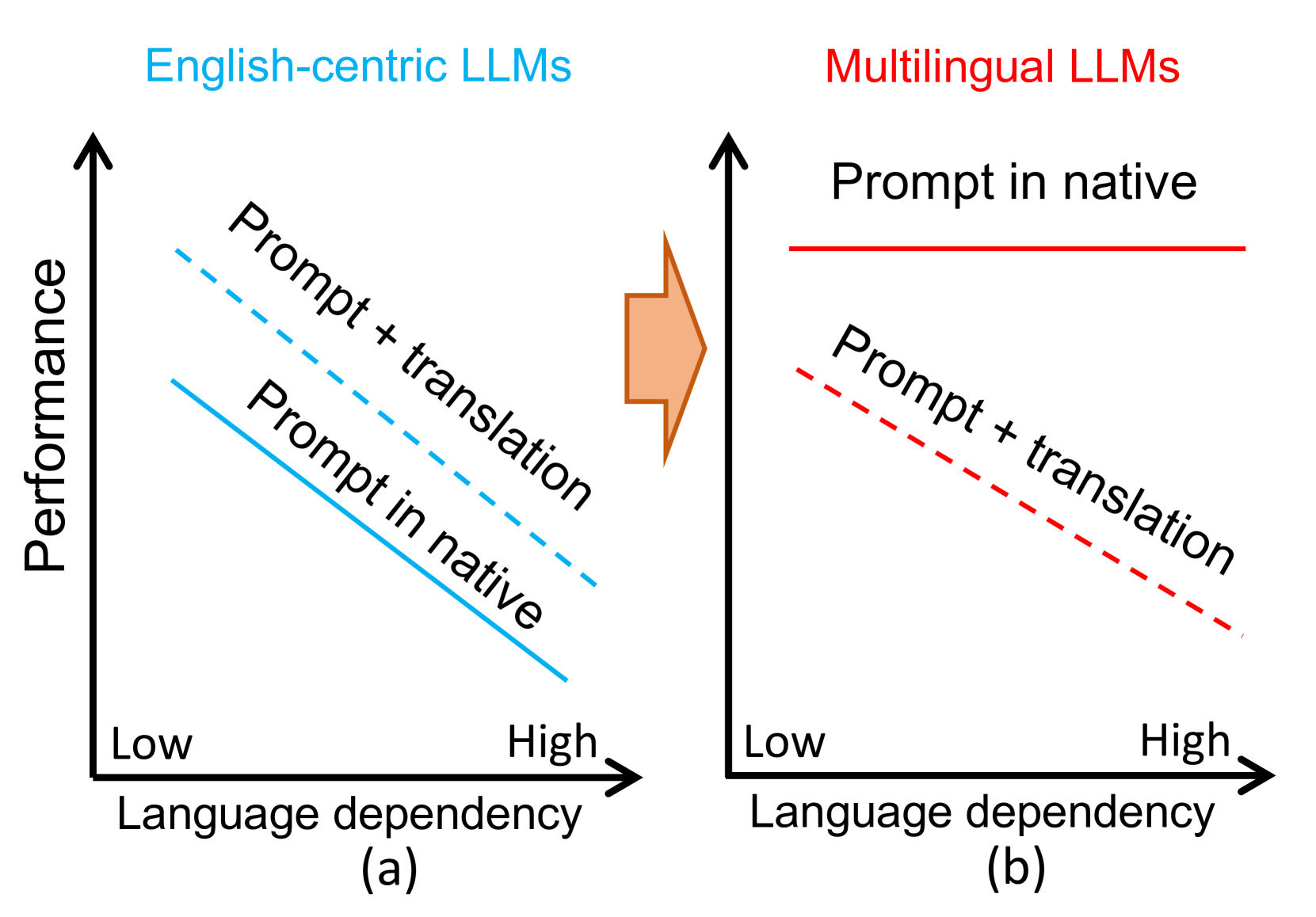
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
0
0
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
6/21/2024
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Binhang Yuan, Wenhu Chen, Jie Fu, Ge Zhang
0
0
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
4/10/2024

Taiyi-Diffusion-XL: Advancing Bilingual Text-to-Image Generation with Large Vision-Language Model Support
Xiaojun Wu, Dixiang Zhang, Ruyi Gan, Junyu Lu, Ziwei Wu, Renliang Sun, Jiaxing Zhang, Pingjian Zhang, Yan Song
0
0
Recent advancements in text-to-image models have significantly enhanced image generation capabilities, yet a notable gap of open-source models persists in bilingual or Chinese language support. To address this need, we present Taiyi-Diffusion-XL, a new Chinese and English bilingual text-to-image model which is developed by extending the capabilities of CLIP and Stable-Diffusion-XL through a process of bilingual continuous pre-training. This approach includes the efficient expansion of vocabulary by integrating the most frequently used Chinese characters into CLIP's tokenizer and embedding layers, coupled with an absolute position encoding expansion. Additionally, we enrich text prompts by large vision-language model, leading to better images captions and possess higher visual quality. These enhancements are subsequently applied to downstream text-to-image models. Our empirical results indicate that the developed CLIP model excels in bilingual image-text retrieval.Furthermore, the bilingual image generation capabilities of Taiyi-Diffusion-XL surpass previous models. This research leads to the development and open-sourcing of the Taiyi-Diffusion-XL model, representing a notable advancement in the field of image generation, particularly for Chinese language applications. This contribution is a step forward in addressing the need for more diverse language support in multimodal research. The model and demonstration are made publicly available at href{https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-XL-3.5B/}, fostering further research and collaboration in this domain.
6/19/2024

Benchmarking Large Language Models on CFLUE -- A Chinese Financial Language Understanding Evaluation Dataset
Jie Zhu, Junhui Li, Yalong Wen, Lifan Guo
0
0
In light of recent breakthroughs in large language models (LLMs) that have revolutionized natural language processing (NLP), there is an urgent need for new benchmarks to keep pace with the fast development of LLMs. In this paper, we propose CFLUE, the Chinese Financial Language Understanding Evaluation benchmark, designed to assess the capability of LLMs across various dimensions. Specifically, CFLUE provides datasets tailored for both knowledge assessment and application assessment. In knowledge assessment, it consists of 38K+ multiple-choice questions with associated solution explanations. These questions serve dual purposes: answer prediction and question reasoning. In application assessment, CFLUE features 16K+ test instances across distinct groups of NLP tasks such as text classification, machine translation, relation extraction, reading comprehension, and text generation. Upon CFLUE, we conduct a thorough evaluation of representative LLMs. The results reveal that only GPT-4 and GPT-4-turbo achieve an accuracy exceeding 60% in answer prediction for knowledge assessment, suggesting that there is still substantial room for improvement in current LLMs. In application assessment, although GPT-4 and GPT-4-turbo are the top two performers, their considerable advantage over lightweight LLMs is noticeably diminished. The datasets and scripts associated with CFLUE are openly accessible at https://github.com/aliyun/cflue.
5/20/2024