Octo: An Open-Source Generalist Robot Policy

0
Sign in to get full access
Overview
- Introduces Octo, an open-source generalist robot policy
- Discusses related work in areas like large language models as generalizable policies, evaluating real-world robot manipulation policies in simulation, and generating robot policy code
- Describes the key components and experiments of the Octo system
Plain English Explanation
The paper presents Octo, an open-source system that aims to create flexible, general-purpose robot policies. Rather than designing specialized algorithms for each task, Octo takes a more holistic approach by training a single model that can handle a wide variety of robotic manipulation challenges.
The researchers draw inspiration from the way humans and animals learn - by building up a broad base of knowledge and skills that can then be applied to novel situations. Similarly, Octo is designed to learn fundamental principles of physics, object manipulation, and task planning that allow it to tackle new problems without requiring extensive retraining.
The system uses a graph neural network architecture to efficiently represent the state of the robot and its environment. This allows Octo to reason about the relationships between different objects and plan sequences of actions to achieve its goals.
Through a series of simulated experiments, the researchers demonstrate Octo's ability to perform tasks like stacking blocks, opening doors, and arranging cluttered environments. Importantly, they also show that Octo's policies can be successfully transferred to a real-world robot platform, highlighting the system's potential for practical applications.
Overall, Octo represents an intriguing step towards more versatile and adaptable robot capabilities, moving beyond narrow, specialized solutions towards a more generalist robotic model that can learn and apply knowledge across a broad range of tasks.
Technical Explanation
The Octo system is built around a graph neural network architecture that allows it to efficiently represent the state of the robot and its environment. This graph-based approach enables Octo to reason about the relationships between different objects and plan sequences of actions to achieve its goals.
The researchers train Octo using a combination of reinforcement learning and imitation learning techniques. In the reinforcement learning phase, the system learns to optimize its behavior through trial-and-error interactions with a simulated environment. The imitation learning component allows Octo to refine its policies by observing expert demonstrations of the target tasks.
Through extensive experimentation in simulation, the team evaluates Octo's performance on a diverse set of robotic manipulation challenges, including block stacking, door opening, and cluttered environment rearrangement. The results demonstrate Octo's ability to learn generalizable policies that can be effectively transferred to a real-world robot platform.
Importantly, the researchers also compare Octo's performance to alternative approaches that rely on more specialized, task-specific algorithms. The findings suggest that Octo's generalist approach can match or exceed the capabilities of these specialized systems, highlighting the potential benefits of a more flexible, adaptable robot policy.
Critical Analysis
The Octo system represents a promising step towards more versatile and capable robot policies, but it is not without its limitations. While the researchers demonstrate successful transfer of Octo's policies to a real-world robot, the experiments are still confined to relatively simple, controlled environments. Scaling Octo to handle the full complexity of real-world scenarios with unpredictable and dynamic elements may require further advancements.
Additionally, the paper does not delve deeply into the interpretability or explainability of Octo's decision-making process. As these systems become more capable and influential, understanding the underlying reasoning behind their actions will be critical for building trust and ensuring safe and ethical deployment.
Future research could also explore ways to further enhance Octo's generalization capabilities, perhaps through the integration of mixture-of-experts approaches or by incorporating more diverse training data and environments. Continued progress in this direction could lead to increasingly flexible and adaptable robot policies that can seamlessly navigate a wide range of real-world challenges.
Conclusion
The Octo system represents an important step towards the development of more versatile and capable robot policies. By adopting a generalist approach inspired by human and animal learning, the researchers have created a system that can tackle a diverse set of robotic manipulation tasks, with the potential for successful transfer to real-world applications.
While the current implementation has some limitations, the underlying concepts and approaches explored in this paper lay the groundwork for further advancements in the field of generalist robotics. As the capabilities of these systems continue to grow, they may play an increasingly important role in a wide range of industries and applications, from manufacturing and logistics to assistive technologies and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
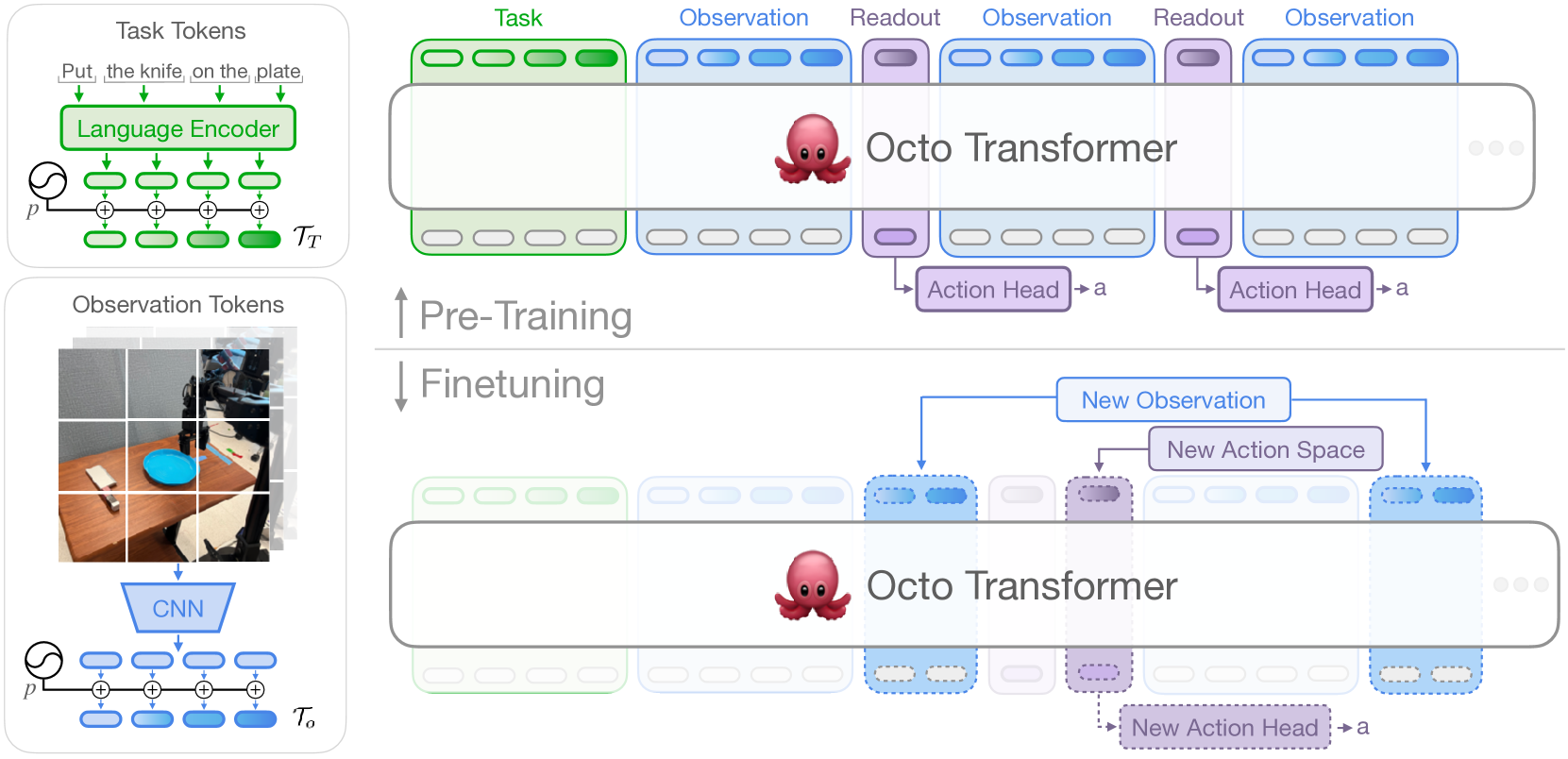
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, Sergey Levine
Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.
Read more5/28/2024

0
Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, Sergey Levine
Modern machine learning systems rely on large datasets to attain broad generalization, and this often poses a challenge in robot learning, where each robotic platform and task might have only a small dataset. By training a single policy across many different kinds of robots, a robot learning method can leverage much broader and more diverse datasets, which in turn can lead to better generalization and robustness. However, training a single policy on multi-robot data is challenging because robots can have widely varying sensors, actuators, and control frequencies. We propose CrossFormer, a scalable and flexible transformer-based policy that can consume data from any embodiment. We train CrossFormer on the largest and most diverse dataset to date, 900K trajectories across 20 different robot embodiments. We demonstrate that the same network weights can control vastly different robots, including single and dual arm manipulation systems, wheeled robots, quadcopters, and quadrupeds. Unlike prior work, our model does not require manual alignment of the observation or action spaces. Extensive experiments in the real world show that our method matches the performance of specialist policies tailored for each embodiment, while also significantly outperforming the prior state of the art in cross-embodiment learning.
Read more8/22/2024
0
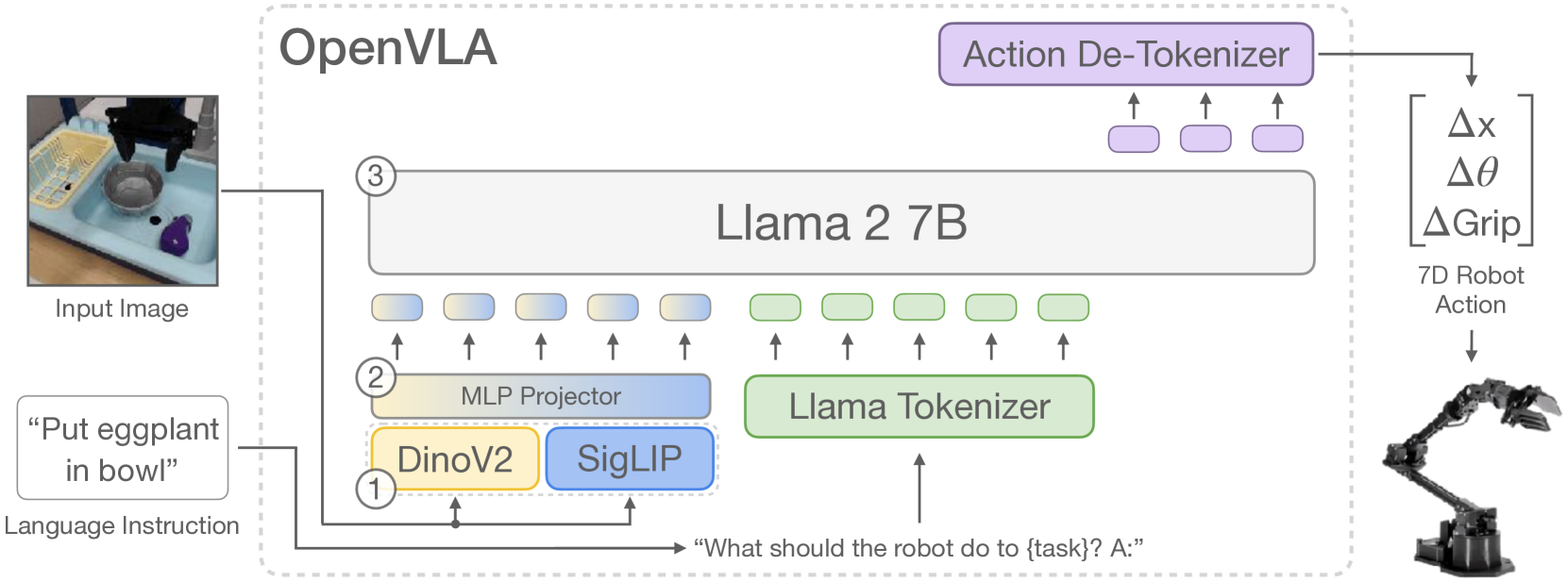
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
Read more9/9/2024
0
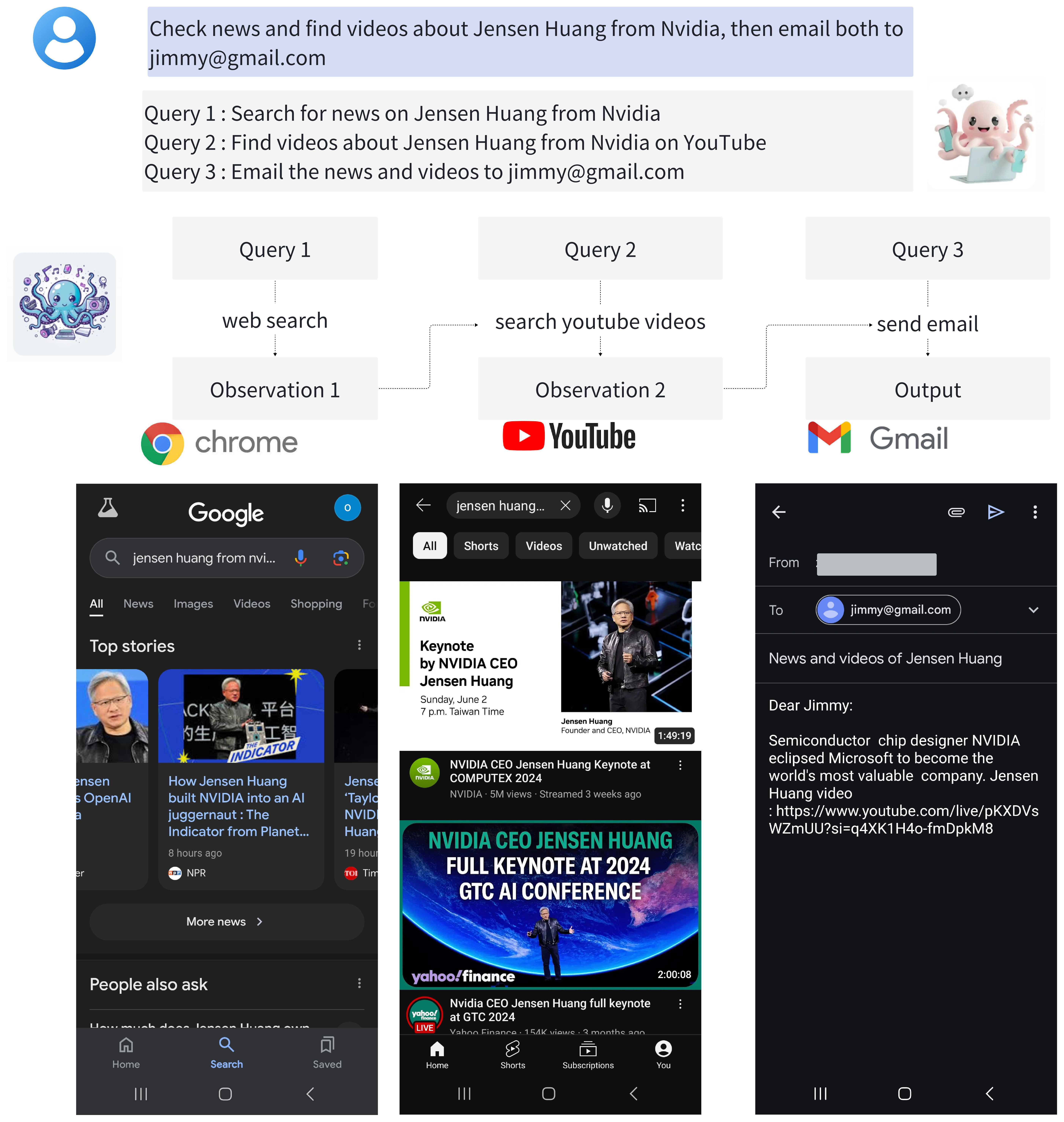
Octo-planner: On-device Language Model for Planner-Action Agents
Wei Chen, Zhiyuan Li, Zhen Guo, Yikang Shen
AI agents have become increasingly significant in various domains, enabling autonomous decision-making and problem-solving. To function effectively, these agents require a planning process that determines the best course of action and then executes the planned actions. In this paper, we present an efficient on-device Planner-Action framework that separates planning and action execution into two distinct components: a planner agent based on Phi-3 Mini, a 3.8 billion parameter LLM optimized for edge devices, and an action agent using the Octopus model for function execution. The planner agent first responds to user queries by decomposing tasks into a sequence of sub-steps, which are then executed by the action agent. To optimize performance on resource-constrained devices, we employ model fine-tuning instead of in-context learning, reducing computational costs and energy consumption while improving response times. Our approach involves using GPT-4 to generate diverse planning queries and responses based on available functions, with subsequent validations to ensure data quality. We fine-tune the Phi-3 Mini model on this curated dataset, achieving a 97% success rate in our in-domain test environment. To address multi-domain planning challenges, we developed a multi-LoRA training method that merges weights from LoRAs trained on distinct function subsets. This approach enables flexible handling of complex, multi-domain queries while maintaining computational efficiency on resource-constrained devices. To support further research, we have open-sourced our model weights at url{https://huggingface.co/NexaAIDev/octopus-planning}. For the demo, please refer to url{https://www.nexa4ai.com/octo-planner}.
Read more6/27/2024