OmniActions: Predicting Digital Actions in Response to Real-World Multimodal Sensory Inputs with LLMs

0

Sign in to get full access
Overview
- This paper presents OmniActions, a system that can predict digital actions in response to real-world multimodal sensory inputs using large language models (LLMs).
- The researchers conducted a diary study to collect a dataset of real-world multimodal experiences and the corresponding digital actions taken by participants.
- They then used this dataset to train an LLM-based model that can predict the most likely digital actions a user would take in response to various sensory inputs, such as visual, audio, and haptic cues.
- The model is designed to enable a "predictive interface" that can proactively suggest or carry out digital actions to augment and enhance users' real-world experiences, a concept known as pervasive augmented reality.
Plain English Explanation
The paper describes a system called OmniActions that can predict the digital actions a person might take in response to their experiences in the real world. The researchers first collected data by having people keep a diary of their daily activities and the digital actions they took in response, like checking their phone or making a note. They then used this data to train a machine learning model that can understand the connection between real-world sensory inputs, like sights and sounds, and the corresponding digital actions people tend to take.
The goal is to create a "predictive interface" that can anticipate what a person might want to do digitally based on their current situation. For example, if the system detects that you're in a meeting, it might automatically create a note or schedule a follow-up. Or if it senses you're in a noisy environment, it could suggest turning on noise-cancelling headphones. The idea is to seamlessly blend the digital and physical worlds to enhance your overall experience.
Technical Explanation
The OmniActions system is built on the premise that there are predictable patterns between real-world sensory inputs and the digital actions people take in response. To capture these patterns, the researchers conducted a diary study where participants logged their daily experiences and the corresponding digital actions they performed, such as taking a photo, making a to-do list, or sending a message.
Using this dataset, the researchers trained a large language model (LLM) to learn the relationships between multimodal sensory cues (visual, audio, haptic, etc.) and the likelihood of different digital actions being taken. The model is designed to be able to ingest a variety of multimodal inputs and output the most probable digital actions the user might want to perform.
Key to the system's effectiveness is its ability to contextualize the user's current situation and adapt its predictions accordingly. For example, if the system detects the user is in a meeting, it will prioritize actions like taking notes or scheduling a follow-up, rather than suggesting posting on social media.
Critical Analysis
The OmniActions system represents an ambitious attempt to bridge the gap between the physical and digital realms, but it faces some potential challenges. One limitation is the reliance on the diary study data, which may not fully capture the nuance and complexity of real-world human behavior and decision-making.
Additionally, there are privacy concerns around a system that so closely monitors and anticipates a user's actions. The researchers acknowledge this and note that user consent and control will be critical in the deployment of such a system.
Further research is also needed to better understand the long-term impacts of a "predictive interface" on human cognition and behavior. There is a risk of users becoming overly dependent on the system's recommendations and losing the ability to make their own decisions.
Overall, the OmniActions concept is an interesting step towards more seamless integration of digital capabilities into our physical experiences, but significant technical and ethical challenges remain to be addressed.
Conclusion
The OmniActions system represents an innovative approach to leveraging large language models and multimodal data to predict and enable digital actions that can enhance real-world user experiences. By bridging the gap between the physical and digital realms, the system aims to create a more seamless and "pervasive" form of augmented reality.
While the technical foundations of the system appear promising, the researchers acknowledge the need to carefully address privacy concerns and potential unintended consequences. Ongoing research and development in this area will be crucial to ensuring that such predictive interfaces empower and enrich users, rather than diminish their autonomy and decision-making abilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OmniActions: Predicting Digital Actions in Response to Real-World Multimodal Sensory Inputs with LLMs
Jiahao Nick Li, Yan Xu, Tovi Grossman, Stephanie Santosa, Michelle Li
The progression to Pervasive Augmented Reality envisions easy access to multimodal information continuously. However, in many everyday scenarios, users are occupied physically, cognitively or socially. This may increase the friction to act upon the multimodal information that users encounter in the world. To reduce such friction, future interactive interfaces should intelligently provide quick access to digital actions based on users' context. To explore the range of possible digital actions, we conducted a diary study that required participants to capture and share the media that they intended to perform actions on (e.g., images or audio), along with their desired actions and other contextual information. Using this data, we generated a holistic design space of digital follow-up actions that could be performed in response to different types of multimodal sensory inputs. We then designed OmniActions, a pipeline powered by large language models (LLMs) that processes multimodal sensory inputs and predicts follow-up actions on the target information grounded in the derived design space. Using the empirical data collected in the diary study, we performed quantitative evaluations on three variations of LLM techniques (intent classification, in-context learning and finetuning) and identified the most effective technique for our task. Additionally, as an instantiation of the pipeline, we developed an interactive prototype and reported preliminary user feedback about how people perceive and react to the action predictions and its errors.
Read more5/8/2024

0
Comparing Apples to Oranges: LLM-powered Multimodal Intention Prediction in an Object Categorization Task
Hassan Ali, Philipp Allgeuer, Stefan Wermter
Intention-based Human-Robot Interaction (HRI) systems allow robots to perceive and interpret user actions to proactively interact with humans and adapt to their behavior. Therefore, intention prediction is pivotal in creating a natural interactive collaboration between humans and robots. In this paper, we examine the use of Large Language Models (LLMs) for inferring human intention during a collaborative object categorization task with a physical robot. We introduce a hierarchical approach for interpreting user non-verbal cues, like hand gestures, body poses, and facial expressions and combining them with environment states and user verbal cues captured using an existing Automatic Speech Recognition (ASR) system. Our evaluation demonstrates the potential of LLMs to interpret non-verbal cues and to combine them with their context-understanding capabilities and real-world knowledge to support intention prediction during human-robot interaction.
Read more4/15/2024
0
LaMI: Large Language Models for Multi-Modal Human-Robot Interaction
Chao Wang, Stephan Hasler, Daniel Tanneberg, Felix Ocker, Frank Joublin, Antonello Ceravola, Joerg Deigmoeller, Michael Gienger
This paper presents an innovative large language model (LLM)-based robotic system for enhancing multi-modal human-robot interaction (HRI). Traditional HRI systems relied on complex designs for intent estimation, reasoning, and behavior generation, which were resource-intensive. In contrast, our system empowers researchers and practitioners to regulate robot behavior through three key aspects: providing high-level linguistic guidance, creating atomic actions and expressions the robot can use, and offering a set of examples. Implemented on a physical robot, it demonstrates proficiency in adapting to multi-modal inputs and determining the appropriate manner of action to assist humans with its arms, following researchers' defined guidelines. Simultaneously, it coordinates the robot's lid, neck, and ear movements with speech output to produce dynamic, multi-modal expressions. This showcases the system's potential to revolutionize HRI by shifting from conventional, manual state-and-flow design methods to an intuitive, guidance-based, and example-driven approach. Supplementary material can be found at https://hri-eu.github.io/Lami/
Read more4/12/2024
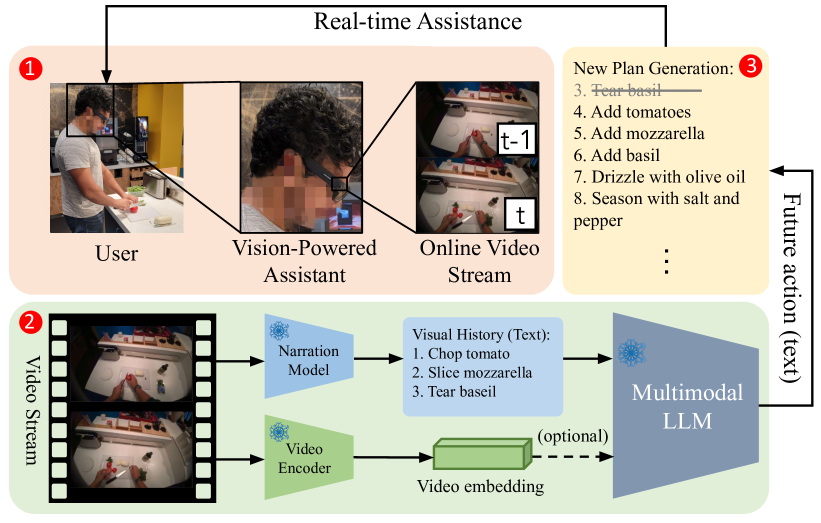
0
User-in-the-loop Evaluation of Multimodal LLMs for Activity Assistance
Mrinal Verghese, Brian Chen, Hamid Eghbalzadeh, Tushar Nagarajan, Ruta Desai
Our research investigates the capability of modern multimodal reasoning models, powered by Large Language Models (LLMs), to facilitate vision-powered assistants for multi-step daily activities. Such assistants must be able to 1) encode relevant visual history from the assistant's sensors, e.g., camera, 2) forecast future actions for accomplishing the activity, and 3) replan based on the user in the loop. To evaluate the first two capabilities, grounding visual history and forecasting in short and long horizons, we conduct benchmarking of two prominent classes of multimodal LLM approaches -- Socratic Models and Vision Conditioned Language Models (VCLMs) on video-based action anticipation tasks using offline datasets. These offline benchmarks, however, do not allow us to close the loop with the user, which is essential to evaluate the replanning capabilities and measure successful activity completion in assistive scenarios. To that end, we conduct a first-of-its-kind user study, with 18 participants performing 3 different multi-step cooking activities while wearing an egocentric observation device called Aria and following assistance from multimodal LLMs. We find that the Socratic approach outperforms VCLMs in both offline and online settings. We further highlight how grounding long visual history, common in activity assistance, remains challenging in current models, especially for VCLMs, and demonstrate that offline metrics do not indicate online performance.
Read more8/14/2024