Optimal Parallelization Strategies for Active Flow Control in Deep Reinforcement Learning-Based Computational Fluid Dynamics

0
🤿
Sign in to get full access
Overview
- This paper explores the use of Deep Reinforcement Learning (DRL) to address the challenges of Active Flow Control (AFC) problems, which can be highly dynamic and nonlinear.
- The main focus is on optimizing DRL-based algorithms to enable efficient scaling on high-performance computing architectures, addressing the computational cost associated with training DRL models.
- The study validates an existing state-of-the-art DRL framework for AFC problems and investigates various hybrid parallelization configurations to improve its efficiency.
- Refinements to input/output (I/O) operations in multi-environment DRL training are also explored to tackle critical overhead associated with data movement.
Plain English Explanation
Deep Reinforcement Learning (DRL) is a powerful technique that can help solve complex problems, like controlling the flow of air or fluid around an object. Imagine you have a car or airplane that needs to move through the air as efficiently as possible. DRL can help you figure out the best way to control the air flow around the vehicle to reduce drag and improve performance.
The challenge with DRL is that it can be computationally expensive to train the models, especially when dealing with highly dynamic and nonlinear problems like air flow control. This paper looks at ways to make DRL-based algorithms more efficient and scalable, so they can be used on powerful computer systems to solve these problems faster.
The researchers started by validating an existing DRL framework used for air flow control problems, and then looked at ways to optimize it. They broke down the framework into different components and tested how well each one could be parallelized, or run on multiple computers at the same time. This allowed them to find the most efficient way to use the available computing power.
Additionally, the researchers looked at ways to improve the way the DRL model handles the data it needs to learn, reducing the time-consuming process of moving data around. By making these improvements, the researchers were able to significantly speed up the training process, making DRL a more practical tool for solving complex air flow control problems.
Technical Explanation
The paper first validates an existing state-of-the-art DRL framework used for AFC problems and identifies efficiency bottlenecks. To address these, the researchers deconstructed the overall framework and conducted extensive scalability benchmarks for individual components.
This investigation led to the exploration of various hybrid parallelization configurations. The researchers proposed efficient parallelization strategies by analyzing the performance of different parallelization approaches, such as data parallelism and model parallelism.
Furthermore, the paper focuses on refining the input/output (I/O) operations in multi-environment DRL training. This is crucial to tackle the critical overhead associated with data movement, which can significantly impact the overall training efficiency.
The optimized framework was then demonstrated on a typical AFC problem, where near-linear scaling was achieved for the overall framework. The researchers were able to boost the parallel efficiency from around 49% to approximately 78%, and the training process was accelerated by approximately 47 times using 60 CPU cores.
Critical Analysis
The paper provides a comprehensive approach to optimizing DRL-based algorithms for efficient scaling on high-performance computing architectures. The researchers have identified and addressed key bottlenecks in the existing state-of-the-art DRL framework, such as computational cost and I/O overhead.
One potential limitation of the study is the specificity of the AFC problem used for the experiments. While the researchers demonstrate the effectiveness of their optimization strategies on this particular problem, it would be valuable to evaluate the performance of the optimized framework on a wider range of DRL-based applications, including multi-agent coordination or resource allocation problems, to fully assess its generalizability.
Additionally, the paper does not provide detailed insights into the specific parallelization strategies employed or the trade-offs between different configurations. A more in-depth discussion of the design choices and their implications could further enhance the understanding and replicability of the proposed optimization techniques.
Conclusion
This study presents a significant contribution to the field of DRL by addressing the computational challenges associated with training DRL models for Active Flow Control (AFC) problems. The researchers have successfully optimized a state-of-the-art DRL framework, achieving substantial improvements in parallel efficiency and training acceleration.
The findings of this work are expected to provide valuable insights for further advancements in DRL-based AFC studies and potentially other DRL applications that require efficient scaling on high-performance computing architectures. The optimization strategies and insights developed in this paper could serve as a foundation for future research in this area, paving the way for more widespread adoption of DRL techniques in real-world, computationally-intensive problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Optimal Parallelization Strategies for Active Flow Control in Deep Reinforcement Learning-Based Computational Fluid Dynamics
Wang Jia, Hang Xu
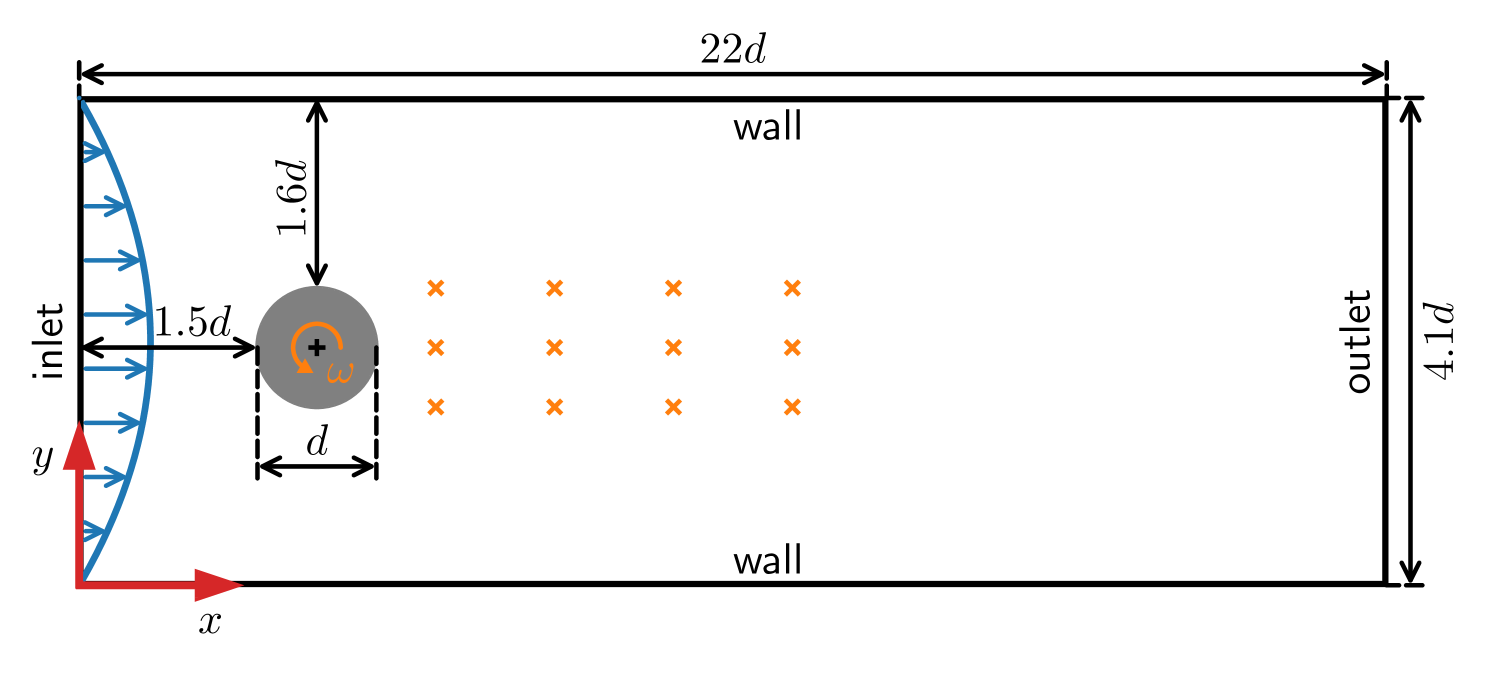
Deep Reinforcement Learning (DRL) has emerged as a promising approach for handling highly dynamic and nonlinear Active Flow Control (AFC) problems. However, the computational cost associated with training DRL models presents a significant performance bottleneck. To address this challenge and enable efficient scaling on high-performance computing architectures, this study focuses on optimizing DRL-based algorithms in parallel settings. We validate an existing state-of-the-art DRL framework used for AFC problems and discuss its efficiency bottlenecks. Subsequently, by deconstructing the overall framework and conducting extensive scalability benchmarks for individual components, we investigate various hybrid parallelization configurations and propose efficient parallelization strategies. Moreover, we refine input/output (I/O) operations in multi-environment DRL training to tackle critical overhead associated with data movement. Finally, we demonstrate the optimized framework for a typical AFC problem where near-linear scaling can be obtained for the overall framework. We achieve a significant boost in parallel efficiency from around 49% to approximately 78%, and the training process is accelerated by approximately 47 times using 60 central processing unit (CPU) cores. These findings are expected to provide valuable insights for further advancements in DRL-based AFC studies. Consequently, it continues to be a prominent and actively studied problem of significant interest.
Read more9/27/2024
0
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
Read more4/11/2024

0
Automated Design and Optimization of Distributed Filtering Circuits via Reinforcement Learning
Peng Gao, Tao Yu, Fei Wang, Ru-Yue Yuan
Designing distributed filter circuits (DFCs) is complex and time-consuming, involving setting and optimizing multiple hyperparameters. Traditional optimization methods, such as using the commercial finite element solver HFSS (High-Frequency Structure Simulator) to enumerate all parameter combinations with fixed steps and then simulate each combination, are not only time-consuming and labor-intensive but also rely heavily on the expertise and experience of electronics engineers, making it difficult to adapt to rapidly changing design requirements. Additionally, these commercial tools struggle with precise adjustments when parameters are sensitive to numerical changes, resulting in limited optimization effectiveness. This study proposes a novel end-to-end automated method for DFC design. The proposed method harnesses reinforcement learning (RL) algorithms, eliminating the dependence on the design experience of engineers. Thus, it significantly reduces the subjectivity and constraints associated with circuit design. The experimental findings demonstrate clear improvements in design efficiency and quality when comparing the proposed method with traditional engineer-driven methods. Furthermore, the proposed method achieves superior performance when designing complex or rapidly evolving DFCs, highlighting the substantial potential of RL in circuit design automation. In particular, compared to the existing DFC automation design method CircuitGNN, our method achieves an average performance improvement of 8.72%. Additionally, the execution efficiency of our method is 2000 times higher than CircuitGNN on the CPU and 241 times higher on the GPU.
Read more7/30/2024

0
Design Optimization of Nuclear Fusion Reactor through Deep Reinforcement Learning
Jinsu Kim, Jaemin Seo
This research explores the application of Deep Reinforcement Learning (DRL) to optimize the design of a nuclear fusion reactor. DRL can efficiently address the challenging issues attributed to multiple physics and engineering constraints for steady-state operation. The fusion reactor design computation and the optimization code applicable to parallelization with DRL are developed. The proposed framework enables finding the optimal reactor design that satisfies the operational requirements while reducing building costs. Multi-objective design optimization for a fusion reactor is now simplified by DRL, indicating the high potential of the proposed framework for advancing the efficient and sustainable design of future reactors.
Read more9/14/2024