PALM: Predicting Actions through Language Models

0
💬
Sign in to get full access
Overview
- This paper introduces PALM, a novel approach for long-term action anticipation in egocentric vision.
- Egocentric vision focuses on capturing the visual perspective of the camera wearer, which is crucial for understanding human activities.
- Traditional methods rely on representation learning from large video datasets, but this is challenging due to the complex and variable nature of human activities.
- PALM combines an action recognition model to track past actions and a vision-language model to capture relevant environmental details.
- It leverages this context to devise a prompting strategy for action anticipation using large language models (LLMs).
- The paper demonstrates that PALM outperforms state-of-the-art methods on the Ego4D benchmark for long-term action anticipation, and its effectiveness is validated across additional benchmarks.
Plain English Explanation
Predicting what a person will do in the future based on their current activities is a complex task, but it's essential for understanding human behavior, especially from the perspective of the person wearing the camera (known as "egocentric vision"). Previous methods have relied on training AI models on large datasets of video footage, but this has been challenging because human activities can be highly varied and unpredictable.
The researchers behind this study developed a new approach called PALM that tackles the problem of long-term action anticipation - forecasting a sequence of future actions over an extended period. PALM combines two key components: an action recognition model that tracks a person's past actions, and a vision-language model that can understand the relevant details in the person's environment. By leveraging the context provided by these past events and environmental factors, PALM uses large language models to predict what the person is likely to do next.
The researchers tested PALM on a benchmark dataset called Ego4D and found that it outperformed other state-of-the-art methods in anticipating long-term actions. They also validated PALM's effectiveness on two additional datasets, showing that it can generalize well to different types of human activities and taxonomies.
Technical Explanation
The key innovation of PALM is its integration of two complementary models: an action recognition model and a vision-language model. The action recognition model tracks the sequence of a person's past actions, while the vision-language model extracts relevant environmental details that could provide context for future actions.
By combining these two sources of information, PALM can leverage a prompting strategy to leverage large language models (LLMs) for long-term action anticipation. The researchers implement a maximal marginal relevance approach to select the most informative examples for in-context learning of the LLMs.
The experiments on the Ego4D benchmark demonstrate PALM's superior performance compared to state-of-the-art methods, such as OmniActions, Intention-Conditioned Long-Term Human Egocentric Action Prediction, and Action Contextualization for Adaptive Task Planning and Action Tuning. The researchers also validate PALM's generalization capabilities on two additional benchmarks, Survey of Vision-Language-Action Models for Embodied AI and [Ego4D].
Critical Analysis
While the PALM approach demonstrates impressive performance on the task of long-term action anticipation, the paper does acknowledge some limitations and areas for further research. The authors note that the effectiveness of PALM may be influenced by the quality and breadth of the training data used for the underlying action recognition and vision-language models.
Additionally, the paper does not delve into the computational efficiency or real-time inference capabilities of PALM, which could be crucial considerations for practical deployment in real-world applications. Further research could explore ways to optimize the model's performance and make it more suitable for deployment in dynamic, resource-constrained environments.
Another potential area for improvement is the interpretability of PALM's predictions. Understanding the reasoning behind the model's anticipations could be valuable for human-machine collaboration and building trust in the system's outputs.
Despite these limitations, the PALM approach represents a significant advancement in the field of egocentric vision and long-term action anticipation. The integration of action recognition and vision-language modeling, coupled with the novel prompting strategy, showcases the potential of leveraging large language models for complex forecasting tasks.
Conclusion
The PALM approach introduced in this paper addresses the challenge of long-term action anticipation in egocentric vision, a crucial task for understanding human behavior and activities. By combining action recognition and vision-language modeling, PALM is able to leverage the context of past actions and environmental details to forecast future action sequences using large language models.
The experimental results demonstrate PALM's superior performance on the Ego4D benchmark and its ability to generalize across different datasets and taxonomies of human activities. While the paper acknowledges some limitations and areas for further research, the PALM approach represents a significant advancement in the field of egocentric vision and action anticipation, with potential applications in various domains, such as human-robot interaction, activity monitoring, and assistive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
PALM: Predicting Actions through Language Models
Sanghwan Kim, Daoji Huang, Yongqin Xian, Otmar Hilliges, Luc Van Gool, Xi Wang
Understanding human activity is a crucial yet intricate task in egocentric vision, a field that focuses on capturing visual perspectives from the camera wearer's viewpoint. Traditional methods heavily rely on representation learning that is trained on a large amount of video data. However, a major challenge arises from the difficulty of obtaining effective video representation. This difficulty stems from the complex and variable nature of human activities, which contrasts with the limited availability of data. In this study, we introduce PALM, an approach that tackles the task of long-term action anticipation, which aims to forecast forthcoming sequences of actions over an extended period. Our method PALM incorporates an action recognition model to track previous action sequences and a vision-language model to articulate relevant environmental details. By leveraging the context provided by these past events, we devise a prompting strategy for action anticipation using large language models (LLMs). Moreover, we implement maximal marginal relevance for example selection to facilitate in-context learning of the LLMs. Our experimental results demonstrate that PALM surpasses the state-of-the-art methods in the task of long-term action anticipation on the Ego4D benchmark. We further validate PALM on two additional benchmarks, affirming its capacity for generalization across intricate activities with different sets of taxonomies.
Read more7/19/2024

0
Open-vocabulary Temporal Action Localization using VLMs
Naoki Wake, Atsushi Kanehira, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
Video action localization aims to find timings of a specific action from a long video. Although existing learning-based approaches have been successful, those require annotating videos that come with a considerable labor cost. This paper proposes a learning-free, open-vocabulary approach based on emerging off-the-shelf vision-language models (VLM). The challenge stems from the fact that VLMs are neither designed to process long videos nor tailored for finding actions. We overcome these problems by extending an iterative visual prompting technique. Specifically, we sample video frames into a concatenated image with frame index labels, making a VLM guess a frame that is considered to be closest to the start/end of the action. Iterating this process by narrowing a sampling time window results in finding a specific frame of start and end of an action. We demonstrate that this sampling technique yields reasonable results, illustrating a practical extension of VLMs for understanding videos. A sample code is available at https://microsoft.github.io/VLM-Video-Action-Localization/.
Read more9/10/2024

0
OmniActions: Predicting Digital Actions in Response to Real-World Multimodal Sensory Inputs with LLMs
Jiahao Nick Li, Yan Xu, Tovi Grossman, Stephanie Santosa, Michelle Li
The progression to Pervasive Augmented Reality envisions easy access to multimodal information continuously. However, in many everyday scenarios, users are occupied physically, cognitively or socially. This may increase the friction to act upon the multimodal information that users encounter in the world. To reduce such friction, future interactive interfaces should intelligently provide quick access to digital actions based on users' context. To explore the range of possible digital actions, we conducted a diary study that required participants to capture and share the media that they intended to perform actions on (e.g., images or audio), along with their desired actions and other contextual information. Using this data, we generated a holistic design space of digital follow-up actions that could be performed in response to different types of multimodal sensory inputs. We then designed OmniActions, a pipeline powered by large language models (LLMs) that processes multimodal sensory inputs and predicts follow-up actions on the target information grounded in the derived design space. Using the empirical data collected in the diary study, we performed quantitative evaluations on three variations of LLM techniques (intent classification, in-context learning and finetuning) and identified the most effective technique for our task. Additionally, as an instantiation of the pipeline, we developed an interactive prototype and reported preliminary user feedback about how people perceive and react to the action predictions and its errors.
Read more5/8/2024
0
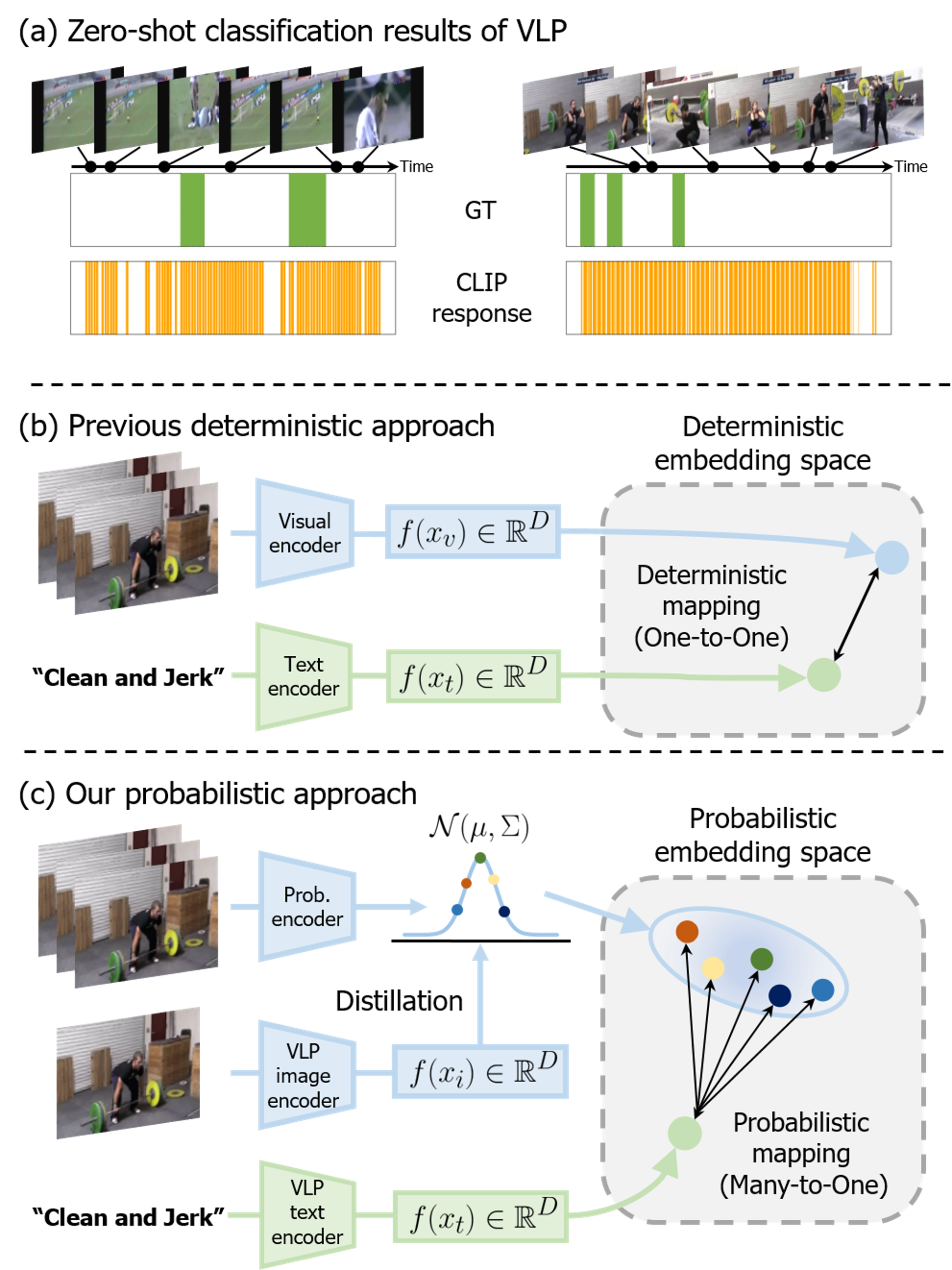
Probabilistic Vision-Language Representation for Weakly Supervised Temporal Action Localization
Geuntaek Lim, Hyunwoo Kim, Joonsoo Kim, Yukyung Choi
Weakly supervised temporal action localization (WTAL) aims to detect action instances in untrimmed videos using only video-level annotations. Since many existing works optimize WTAL models based on action classification labels, they encounter the task discrepancy problem (i.e., localization-by-classification). To tackle this issue, recent studies have attempted to utilize action category names as auxiliary semantic knowledge through vision-language pre-training (VLP). However, there are still areas where existing research falls short. Previous approaches primarily focused on leveraging textual information from language models but overlooked the alignment of dynamic human action and VLP knowledge in a joint space. Furthermore, the deterministic representation employed in previous studies struggles to capture fine-grained human motions. To address these problems, we propose a novel framework that aligns human action knowledge and VLP knowledge in a probabilistic embedding space. Moreover, we propose intra- and inter-distribution contrastive learning to enhance the probabilistic embedding space based on statistical similarities. Extensive experiments and ablation studies reveal that our method significantly outperforms all previous state-of-the-art methods. Code is available at https://github.com/sejong-rcv/PVLR.
Read more8/13/2024