Panacea: Pareto Alignment via Preference Adaptation for LLMs

0

Sign in to get full access
Overview
- This paper introduces "Panacea," a novel method for aligning large language models (LLMs) with human preferences using preference adaptation.
- Panacea aims to find a Pareto-optimal set of LLM outputs that balance different user preferences, such as safety, coherence, and informativeness.
- The approach involves iteratively updating the LLM's preferences based on user feedback to converge on an aligned model.
Plain English Explanation
Panacea is a new technique for training large language models (LLMs) to better match human preferences. LLMs are AI systems that can generate human-like text, but they don't always produce outputs that align with what people want.
The key idea behind Panacea is to find a set of LLM outputs that balance different user preferences, like safety, coherence, and informativeness. This "Pareto-optimal" set represents the best trade-offs between these preferences.
To do this, Panacea repeatedly updates the LLM's preferences based on feedback from users. Over time, the model converges on outputs that satisfy the users' desired priorities. This preference adaptation process helps the LLM learn to generate text that is more closely aligned with human values and needs.
By finding this sweet spot between competing preferences, Panacea aims to create LLMs that are more useful and trustworthy for real-world applications. This could lead to language models that are better at tasks like link to "Linear Alignment: Closed-Form Solution for Aligning Human and Machine Preferences" generating helpful responses, link to "Knowledgeable Preference Alignment for LLMs in Domain-Specific Question Answering" answering questions accurately, link to "SPO: Multi-Dimensional Preference for Sequential Alignment of Implicit Reward" and link to "Value-Augmented Sampling: Language Model Alignment through Personalization" and link to "Aligning Language Models with Human Preferences" expressing preferences that match human values.
Technical Explanation
Panacea builds on the concept of Pareto set learning, which seeks to find a set of optimal solutions that balance multiple, potentially conflicting objectives. In the context of LLM alignment, these objectives could include safety, coherence, informativeness, and other user preferences.
The Panacea approach works as follows:
- The user provides feedback on sample LLM outputs, indicating their preferences.
- Panacea uses this feedback to update the model's preferences, pushing it towards a Pareto-optimal set of outputs.
- The process repeats, with the LLM generating new outputs and the user providing further feedback, until convergence.
This iterative preference adaptation allows the LLM to learn the user's priorities and generate text that aligns with their values. The authors demonstrate Panacea's effectiveness on a variety of language tasks, showing that it can produce outputs that better satisfy user preferences compared to standard LLM training.
Critical Analysis
The Panacea paper provides a thoughtful approach to the challenging problem of aligning LLMs with human preferences. By focusing on finding a Pareto-optimal set of outputs, the method avoids the need to precisely specify and weight different preferences, which can be difficult in practice.
However, the paper acknowledges some limitations. The preference adaptation process relies on user feedback, which may be noisy or biased. Additionally, the technique may struggle to handle rapidly changing or contextual preferences. Further research is needed to address these challenges and explore ways to make the preference adaptation more robust and scalable.
Another potential concern is the potential for Panacea to amplify existing biases in the training data or user feedback. The authors note that careful curation of the data and feedback is important to avoid reinforcing harmful biases. Ongoing monitoring and adjustment of the system will likely be necessary to maintain alignment with evolving societal values.
Despite these caveats, Panacea represents an important step forward in the quest to create LLMs that are more closely aligned with human preferences. By focusing on Pareto optimality, the method offers a promising path towards building AI systems that can balance multiple, sometimes competing, objectives in a way that better serves user needs.
Conclusion
The Panacea paper introduces a novel approach for aligning large language models with human preferences using preference adaptation. By iteratively updating the model's preferences based on user feedback, Panacea can converge on a Pareto-optimal set of outputs that balance different objectives like safety, coherence, and informativeness.
This work represents a significant advance in the field of AI alignment, offering a more nuanced and flexible approach compared to traditional methods that rely on precisely specified and weighted preferences. While the technique has some limitations that require further research, Panacea demonstrates the potential for AI systems to better serve human values and needs, paving the way for more trustworthy and beneficial language models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Panacea: Pareto Alignment via Preference Adaptation for LLMs
Yifan Zhong, Chengdong Ma, Xiaoyuan Zhang, Ziran Yang, Haojun Chen, Qingfu Zhang, Siyuan Qi, Yaodong Yang
Current methods for large language model alignment typically use scalar human preference labels. However, this convention tends to oversimplify the multi-dimensional and heterogeneous nature of human preferences, leading to reduced expressivity and even misalignment. This paper presents Panacea, an innovative approach that reframes alignment as a multi-dimensional preference optimization problem. Panacea trains a single model capable of adapting online and Pareto-optimally to diverse sets of preferences without the need for further tuning. A major challenge here is using a low-dimensional preference vector to guide the model's behavior, despite it being governed by an overwhelmingly large number of parameters. To address this, Panacea is designed to use singular value decomposition (SVD)-based low-rank adaptation, which allows the preference vector to be simply injected online as singular values. Theoretically, we prove that Panacea recovers the entire Pareto front with common loss aggregation methods under mild conditions. Moreover, our experiments demonstrate, for the first time, the feasibility of aligning a single LLM to represent an exponentially vast spectrum of human preferences through various optimization methods. Our work marks a step forward in effectively and efficiently aligning models to diverse and intricate human preferences in a controllable and Pareto-optimal manner.
Read more5/24/2024

0
PAL: Pluralistic Alignment Framework for Learning from Heterogeneous Preferences
Daiwei Chen, Yi Chen, Aniket Rege, Ramya Korlakai Vinayak
Large foundation models pretrained on raw web-scale data are not readily deployable without additional step of extensive alignment to human preferences. Such alignment is typically done by collecting large amounts of pairwise comparisons from humans (Do you prefer output A or B?) and learning a reward model or a policy with the Bradley-Terry-Luce (BTL) model as a proxy for a human's underlying implicit preferences. These methods generally suffer from assuming a universal preference shared by all humans, which lacks the flexibility of adapting to plurality of opinions and preferences. In this work, we propose PAL, a framework to model human preference complementary to existing pretraining strategies, which incorporates plurality from the ground up. We propose using the ideal point model as a lens to view alignment using preference comparisons. Together with our novel reformulation and using mixture modeling, our framework captures the plurality of population preferences while simultaneously learning a common preference latent space across different preferences, which can few-shot generalize to new, unseen users. Our approach enables us to use the penultimate-layer representation of large foundation models and simple MLP layers to learn reward functions that are on-par with the existing large state-of-the-art reward models, thereby enhancing efficiency of reward modeling significantly. We show that PAL achieves competitive reward model accuracy compared to strong baselines on 1) Language models with Summary dataset ; 2) Image Generative models with Pick-a-Pic dataset ; 3) A new semisynthetic heterogeneous dataset generated using Anthropic Personas. Finally, our experiments also highlight the shortcoming of current preference datasets that are created using rigid rubrics which wash away heterogeneity, and call for more nuanced data collection approaches.
Read more6/13/2024
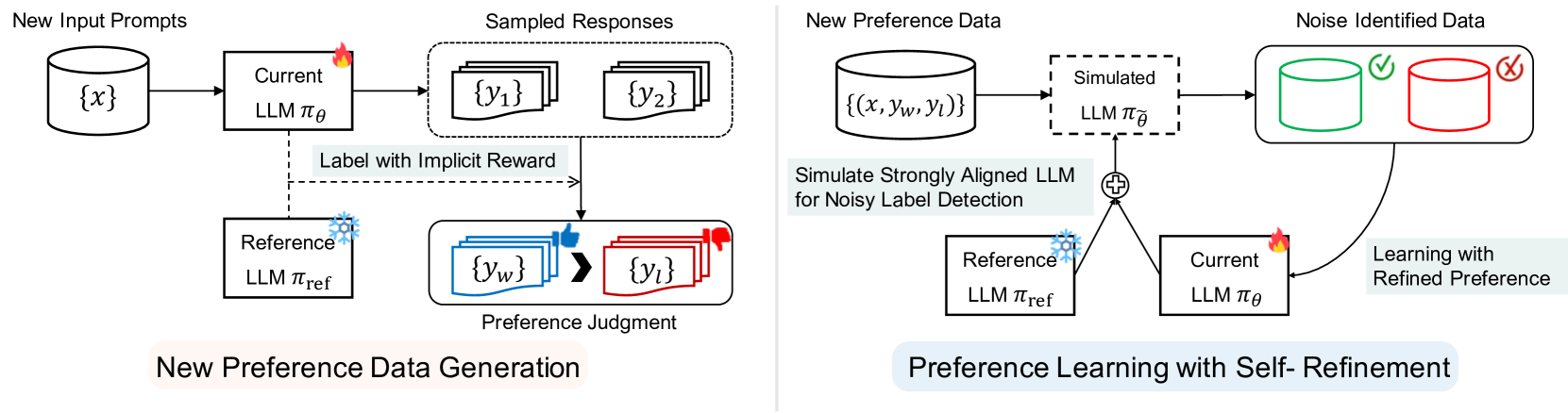
0
Aligning Large Language Models with Self-generated Preference Data
Dongyoung Kim, Kimin Lee, Jinwoo Shin, Jaehyung Kim
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
Read more6/10/2024
0
Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators
Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vuli'c, Anna Korhonen, Nigel Collier
Large Language Models (LLMs) have demonstrated promising capabilities as automatic evaluators in assessing the quality of generated natural language. However, LLMs still exhibit biases in evaluation and often struggle to generate coherent evaluations that align with human assessments. In this work, we first conduct a systematic study of the misalignment between LLM evaluators and human judgement, revealing that existing calibration methods aimed at mitigating biases are insufficient for effectively aligning LLM evaluators. Inspired by the use of preference data in RLHF, we formulate the evaluation as a ranking problem and introduce Pairwise-preference Search (PairS), an uncertainty-guided search method that employs LLMs to conduct pairwise comparisons and efficiently ranks candidate texts. PairS achieves state-of-the-art performance on representative evaluation tasks and demonstrates significant improvements over direct scoring. Furthermore, we provide insights into the role of pairwise preference in quantifying the transitivity of LLMs and demonstrate how PairS benefits from calibration.
Read more8/13/2024