PAL: Pluralistic Alignment Framework for Learning from Heterogeneous Preferences

0

Sign in to get full access
Overview
- This paper presents a novel framework called PAL (Pluralistic Alignment) for learning from heterogeneous preferences.
- PAL aims to address the challenge of aligning large language models (LLMs) with diverse human preferences, which is crucial for developing safe and beneficial AI systems.
- The framework leverages Aligning Large Language Models with Self-Generated Preference, PARL: A Unified Framework for Policy Alignment in Reinforcement Learning, and other related work to create a more comprehensive approach.
Plain English Explanation
The paper introduces a new framework called PAL that helps train large language models (LLMs) to better align with diverse human preferences. This is an important challenge, as we want AI systems to behave in ways that are beneficial and safe for humans.
The key idea behind PAL is to combine different techniques from previous research to create a more comprehensive approach. For example, it builds on work that teaches LLMs to generate their own preferences, as well as research on aligning reinforcement learning agents with human values.
By using this multifaceted approach, PAL aims to train LLMs that can understand and respond to a wider range of human preferences, rather than just optimizing for a single objective. This could help ensure that as AI systems become more advanced, they remain well-aligned with the interests and values of the humans they interact with.
Technical Explanation
The PAL framework consists of several key components:
-
Preference Learning: PAL learns a distribution over human preferences by aggregating feedback from diverse sources, such as Aligning Crowd Feedback via Distributional Preference Reward and Aligning Language Models with Human Preferences.
-
Preference Adaptation: The model then adapts its behavior to align with this distribution of preferences, drawing inspiration from PANACEA: Pareto Alignment via Preference Adaptation in LLMs.
-
Multi-Objective Optimization: PAL optimizes the model to balance multiple objectives, including satisfying the learned preferences while also maintaining other desirable properties, such as coherence and factual accuracy.
The authors demonstrate the effectiveness of PAL through experiments on a variety of tasks, showing that it can outperform baseline approaches in terms of aligning model outputs with human preferences.
Critical Analysis
The PAL framework represents an important step forward in the challenge of aligning large language models with diverse human preferences. By drawing on a range of existing techniques, it offers a more comprehensive approach than previous work.
That said, the paper acknowledges several limitations and areas for future research. For example, the preference learning component relies on aggregating feedback from diverse sources, which may be challenging to scale or maintain in practice. Additionally, the multi-objective optimization process introduces complexity that could make the framework harder to apply in real-world settings.
More research is also needed to understand the long-term implications of this type of preference alignment approach. While the short-term results are promising, there may be unintended consequences or edge cases that require further exploration.
Ultimately, the PAL framework is a valuable contribution to the ongoing effort to develop AI systems that reliably act in accordance with human values and preferences. However, continued research and careful consideration of the potential risks and limitations will be necessary to ensure the safe and beneficial deployment of such technologies.
Conclusion
The PAL framework introduced in this paper represents an important step forward in the quest to align large language models with diverse human preferences. By drawing on a range of existing techniques, it offers a more comprehensive approach than previous work, with the potential to create AI systems that are better attuned to the values and interests of the humans they interact with.
While the paper highlights several limitations and areas for future research, the core ideas behind PAL are a significant advancement in the field. As AI systems become increasingly sophisticated, frameworks like this will be crucial for ensuring they remain well-aligned with human priorities and behave in ways that are beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PAL: Pluralistic Alignment Framework for Learning from Heterogeneous Preferences
Daiwei Chen, Yi Chen, Aniket Rege, Ramya Korlakai Vinayak
Large foundation models pretrained on raw web-scale data are not readily deployable without additional step of extensive alignment to human preferences. Such alignment is typically done by collecting large amounts of pairwise comparisons from humans (Do you prefer output A or B?) and learning a reward model or a policy with the Bradley-Terry-Luce (BTL) model as a proxy for a human's underlying implicit preferences. These methods generally suffer from assuming a universal preference shared by all humans, which lacks the flexibility of adapting to plurality of opinions and preferences. In this work, we propose PAL, a framework to model human preference complementary to existing pretraining strategies, which incorporates plurality from the ground up. We propose using the ideal point model as a lens to view alignment using preference comparisons. Together with our novel reformulation and using mixture modeling, our framework captures the plurality of population preferences while simultaneously learning a common preference latent space across different preferences, which can few-shot generalize to new, unseen users. Our approach enables us to use the penultimate-layer representation of large foundation models and simple MLP layers to learn reward functions that are on-par with the existing large state-of-the-art reward models, thereby enhancing efficiency of reward modeling significantly. We show that PAL achieves competitive reward model accuracy compared to strong baselines on 1) Language models with Summary dataset ; 2) Image Generative models with Pick-a-Pic dataset ; 3) A new semisynthetic heterogeneous dataset generated using Anthropic Personas. Finally, our experiments also highlight the shortcoming of current preference datasets that are created using rigid rubrics which wash away heterogeneity, and call for more nuanced data collection approaches.
Read more6/13/2024

0
A Survey on Human Preference Learning for Large Language Models
Ruili Jiang, Kehai Chen, Xuefeng Bai, Zhixuan He, Juntao Li, Muyun Yang, Tiejun Zhao, Liqiang Nie, Min Zhang
The recent surge of versatile large language models (LLMs) largely depends on aligning increasingly capable foundation models with human intentions by preference learning, enhancing LLMs with excellent applicability and effectiveness in a wide range of contexts. Despite the numerous related studies conducted, a perspective on how human preferences are introduced into LLMs remains limited, which may prevent a deeper comprehension of the relationships between human preferences and LLMs as well as the realization of their limitations. In this survey, we review the progress in exploring human preference learning for LLMs from a preference-centered perspective, covering the sources and formats of preference feedback, the modeling and usage of preference signals, as well as the evaluation of the aligned LLMs. We first categorize the human feedback according to data sources and formats. We then summarize techniques for human preferences modeling and compare the advantages and disadvantages of different schools of models. Moreover, we present various preference usage methods sorted by the objectives to utilize human preference signals. Finally, we summarize some prevailing approaches to evaluate LLMs in terms of alignment with human intentions and discuss our outlooks on the human intention alignment for LLMs.
Read more6/19/2024
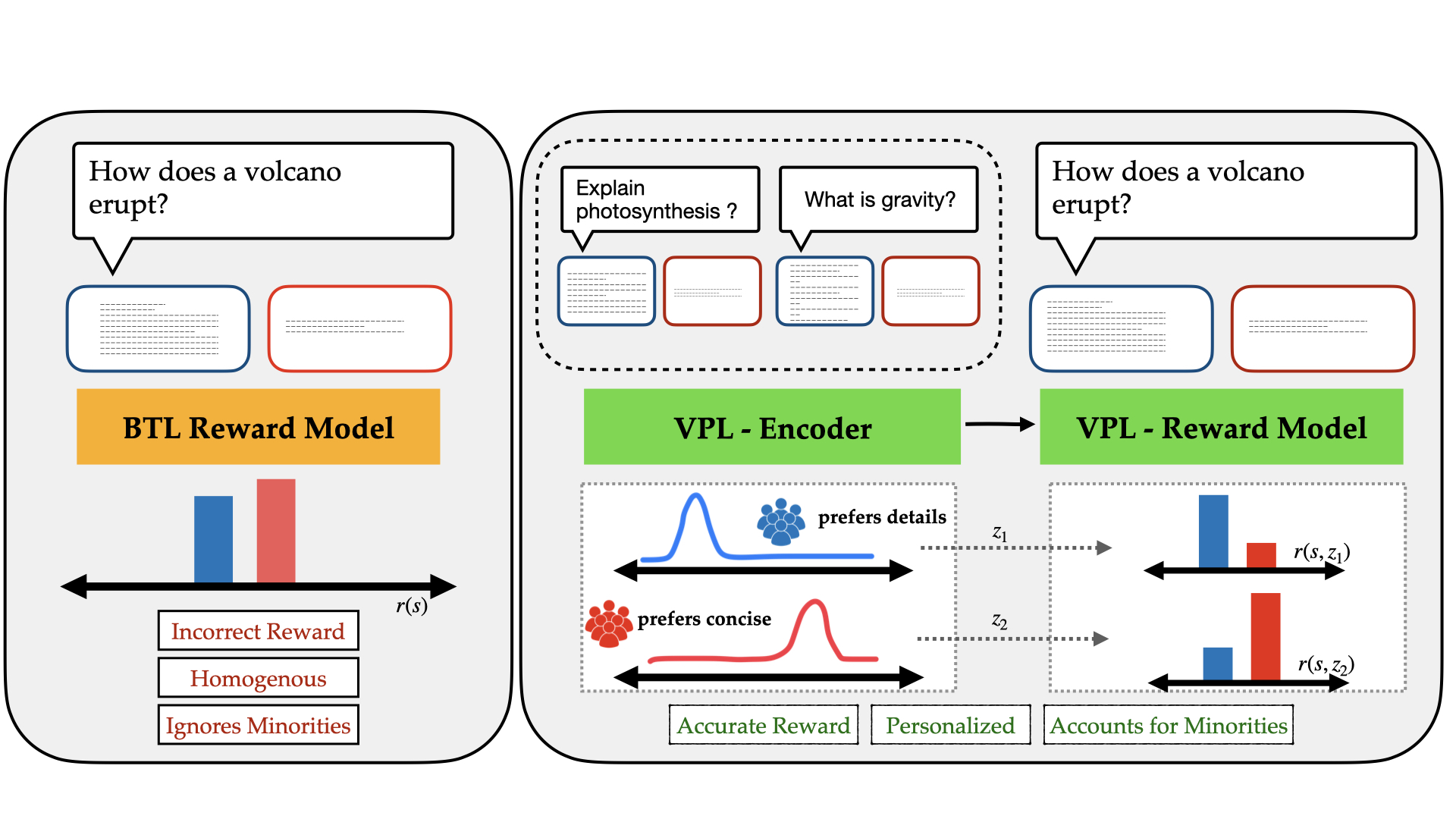
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024
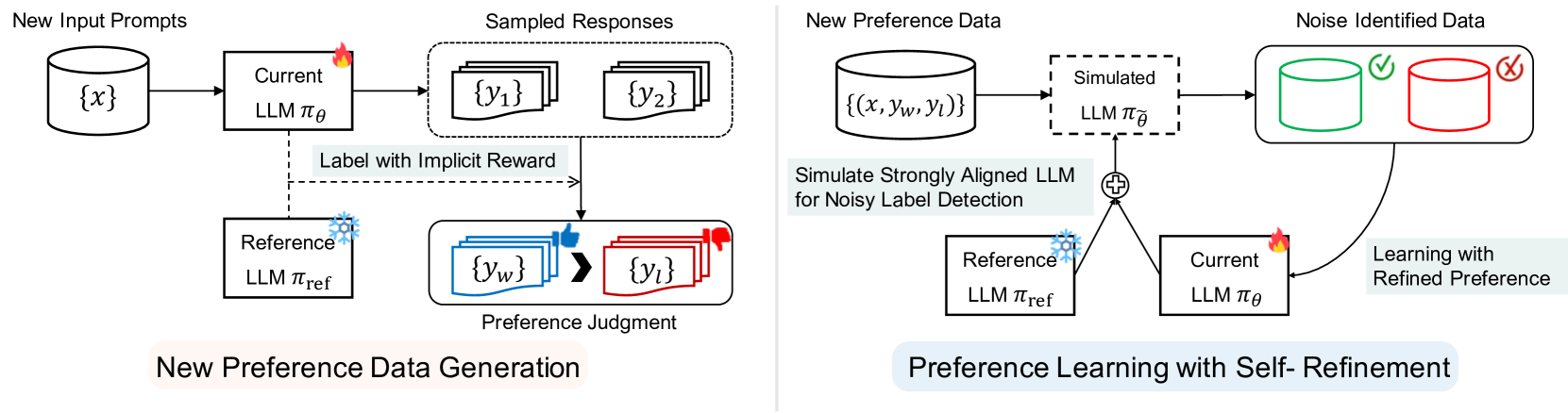
0
Aligning Large Language Models with Self-generated Preference Data
Dongyoung Kim, Kimin Lee, Jinwoo Shin, Jaehyung Kim
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
Read more6/10/2024