PEEB: Part-based Image Classifiers with an Explainable and Editable Language Bottleneck

0
Sign in to get full access
Overview
- This paper introduces PEEB, a part-based image classification model with an explainable and editable language bottleneck.
- The key innovation is the use of a language model to provide a semantic understanding of image parts, allowing the model to be more interpretable and editable.
- The system is evaluated on the Bird-11K dataset, a collection of bird images with part-level annotations.
Plain English Explanation
PEEB is a new type of image classification model that tries to be more understandable and adjustable than traditional models. Typical image classifiers are like black boxes - they take an image as input and output a label, but it's hard to know how they made that decision. PEEB is different because it explicitly models the different parts of the image, like the beak, wings, and tail of a bird, and uses a language model to describe those parts.
This allows the model to explain its reasoning in natural language, which makes it more transparent. It also means the model can be edited by changing the language descriptions of the parts, rather than having to retrain the whole model from scratch. This could be useful if you want to customize the model for a specific application or correct any mistakes it's making.
The researchers tested PEEB on a dataset of bird images, since birds have well-defined parts that are easy to label and describe. But the general approach could potentially work for classifying other types of objects as well.
Technical Explanation
The key components of PEEB are:
-
Part Detector: This module identifies the different parts of the input image (e.g. beak, wings, tail for a bird image) using bounding box annotations.
-
Language Bottleneck: A language model is used to generate natural language descriptions of each detected part. This provides a semantic, interpretable representation of the image.
-
Part Classifier: The language descriptions are then used to classify each part and the overall image. The classifiers are trained end-to-end with the language model.
The researchers evaluate PEEB on the Bird-11K dataset, which contains over 11,000 bird images with part-level annotations. They show that PEEB achieves competitive classification performance compared to other state-of-the-art models. Importantly, the language bottleneck makes the model more explainable, as users can inspect the textual descriptions to understand the model's reasoning.
Additionally, the model can be edited by modifying the language descriptions, allowing users to fine-tune the model for their specific needs without retraining the entire system from scratch. This is a valuable property that distinguishes PEEB from more opaque black-box classifiers.
Critical Analysis
The main strength of PEEB is its ability to provide an interpretable, editable interface for image classification. By grounding the model in natural language, it becomes more transparent and customizable compared to typical deep learning approaches.
However, the paper does not extensively explore the limitations of this approach. For example, it's unclear how well PEEB would scale to more complex, diverse datasets beyond the relatively constrained Bird-11K domain. The language model might struggle to accurately describe more ambiguous or abstract visual concepts.
Additionally, the paper does not delve into potential biases or failure modes that could arise from the language-based representations. As recent research has shown, language models can pick up on spurious correlations and biases present in their training data, which could then be reflected in the image classifications.
Further investigation is needed to understand the broader applicability and robustness of the PEEB approach, especially as it relates to zero-shot and few-shot learning scenarios, as well as the interpretability of the language-based representations.
Conclusion
The PEEB model presents an interesting approach to image classification that leverages language modeling to make the system more explainable and editable. This could be a valuable property for applications where transparency and customization are important, such as medical diagnosis or security screening.
While the current evaluation shows promising results on the Bird-11K dataset, further research is needed to understand the broader applicability and limitations of this approach. Exploring how PEEB performs on more diverse and challenging datasets, as well as investigating potential biases and failure modes, will be important next steps to fully assess the merits and drawbacks of this language-grounded image classification paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PEEB: Part-based Image Classifiers with an Explainable and Editable Language Bottleneck
Thang M. Pham, Peijie Chen, Tin Nguyen, Seunghyun Yoon, Trung Bui, Anh Totti Nguyen
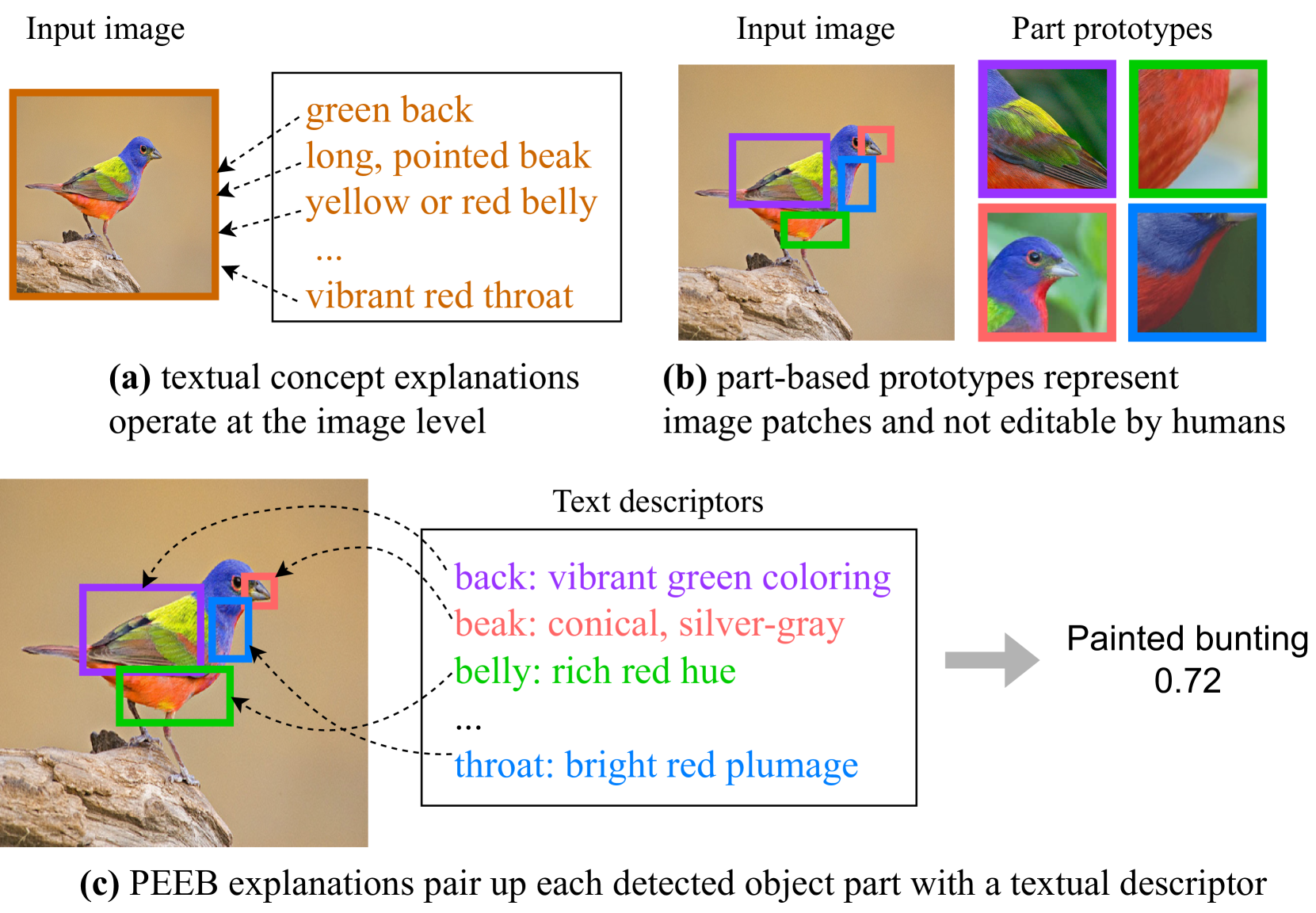
CLIP-based classifiers rely on the prompt containing a {class name} that is known to the text encoder. Therefore, they perform poorly on new classes or the classes whose names rarely appear on the Internet (e.g., scientific names of birds). For fine-grained classification, we propose PEEB - an explainable and editable classifier to (1) express the class name into a set of text descriptors that describe the visual parts of that class; and (2) match the embeddings of the detected parts to their textual descriptors in each class to compute a logit score for classification. In a zero-shot setting where the class names are unknown, PEEB outperforms CLIP by a huge margin (~10x in top-1 accuracy). Compared to part-based classifiers, PEEB is not only the state-of-the-art (SOTA) on the supervised-learning setting (88.80% and 92.20% accuracy on CUB-200 and Dogs-120, respectively) but also the first to enable users to edit the text descriptors to form a new classifier without any re-training. Compared to concept bottleneck models, PEEB is also the SOTA in both zero-shot and supervised-learning settings.
Read more4/16/2024
0
CLIP-QDA: An Explainable Concept Bottleneck Model
R'emi Kazmierczak, Eloise Berthier, Goran Frehse, Gianni Franchi
In this paper, we introduce an explainable algorithm designed from a multi-modal foundation model, that performs fast and explainable image classification. Drawing inspiration from CLIP-based Concept Bottleneck Models (CBMs), our method creates a latent space where each neuron is linked to a specific word. Observing that this latent space can be modeled with simple distributions, we use a Mixture of Gaussians (MoG) formalism to enhance the interpretability of this latent space. Then, we introduce CLIP-QDA, a classifier that only uses statistical values to infer labels from the concepts. In addition, this formalism allows for both local and global explanations. These explanations come from the inner design of our architecture, our work is part of a new family of greybox models, combining performances of opaque foundation models and the interpretability of transparent models. Our empirical findings show that in instances where the MoG assumption holds, CLIP-QDA achieves similar accuracy with state-of-the-art methods CBMs. Our explanations compete with existing XAI methods while being faster to compute.
Read more6/3/2024

0
CLIP model is an Efficient Online Lifelong Learner
Leyuan Wang, Liuyu Xiang, Yujie Wei, Yunlong Wang, Zhaofeng He
Online Lifelong Learning (OLL) addresses the challenge of learning from continuous and non-stationary data streams. Existing online lifelong learning methods based on image classification models often require preset conditions such as the total number of classes or maximum memory capacity, which hinders the realization of real never-ending learning and renders them impractical for real-world scenarios. In this work, we propose that vision-language models, such as Contrastive Language-Image Pretraining (CLIP), are more suitable candidates for online lifelong learning. We discover that maintaining symmetry between image and text is crucial during Parameter-Efficient Tuning (PET) for CLIP model in online lifelong learning. To this end, we introduce the Symmetric Image-Text (SIT) tuning strategy. We conduct extensive experiments on multiple lifelong learning benchmark datasets and elucidate the effectiveness of SIT through gradient analysis. Additionally, we assess the impact of lifelong learning on generalizability of CLIP and found that tuning the image encoder is beneficial for lifelong learning, while tuning the text encoder aids in zero-shot learning.
Read more5/27/2024
🖼️
0
What's in a Name? Beyond Class Indices for Image Recognition
Kai Han, Xiaohu Huang, Yandong Li, Sagar Vaze, Jie Li, Xuhui Jia
Existing machine learning models demonstrate excellent performance in image object recognition after training on a large-scale dataset under full supervision. However, these models only learn to map an image to a predefined class index, without revealing the actual semantic meaning of the object in the image. In contrast, vision-language models like CLIP are able to assign semantic class names to unseen objects in a 'zero-shot' manner, though they are once again provided a pre-defined set of candidate names at test-time. In this paper, we reconsider the recognition problem and task a vision-language model with assigning class names to images given only a large (essentially unconstrained) vocabulary of categories as prior information. We leverage non-parametric methods to establish meaningful relationships between images, allowing the model to automatically narrow down the pool of candidate names. Our proposed approach entails iteratively clustering the data and employing a voting mechanism to determine the most suitable class names. Additionally, we investigate the potential of incorporating additional textual features to enhance clustering performance. To achieve this, we employ the CLIP vision and text encoders to retrieve relevant texts from an external database, which can provide supplementary semantic information to inform the clustering process. Furthermore, we tackle this problem both in unsupervised and partially supervised settings, as well as with a coarse-grained and fine-grained search space as the unconstrained dictionary. Remarkably, our method leads to a roughly 50% improvement over the baseline on ImageNet in the unsupervised setting.
Read more7/30/2024