Period Singer: Integrating Periodic and Aperiodic Variational Autoencoders for Natural-Sounding End-to-End Singing Voice Synthesis

0

Sign in to get full access
Overview
- The paper introduces a novel end-to-end singing voice synthesis model called "Period Singer" that integrates periodic and aperiodic variational autoencoders (VAEs) to generate natural-sounding singing voices.
- The model combines a periodic VAE that captures the harmonic structure of singing voices with an aperiodic VAE that models the noise-like aspects, resulting in more realistic and expressive synthesized singing.
- The authors also propose a self-supervised pre-training approach and a semi-supervised training method to address the challenge of limited singing voice data.
Plain English Explanation
The paper describes a new way to generate artificial singing voices that sound more natural and expressive. The key idea is to break down the singing voice into two main components: the periodic (harmonic) part and the aperiodic (noise-like) part.
The periodic part is responsible for the harmonic structure of the singing voice, like the notes and melody. The aperiodic part captures the more random, noise-like aspects, such as the breath and imperfections in the voice. By modeling these two components separately using variational autoencoders, the researchers were able to produce singing voices that sound more lifelike and natural.
To make this work, the researchers also developed some additional techniques. First, they used a self-supervised pre-training approach to better learn the characteristics of singing voices, even when there is limited data available. Second, they used a semi-supervised training method that can effectively use both labeled and unlabeled singing voice data.
The end result is a singing voice synthesis system called "Period Singer" that can generate more natural and expressive artificial singing voices, even when training data is scarce. This could have applications in music production, virtual assistants, and other areas where realistic-sounding singing voices are needed.
Technical Explanation
The "Period Singer" model proposed in the paper consists of two main components: a periodic variational autoencoder (VAE) and an aperiodic VAE. The periodic VAE is responsible for modeling the harmonic structure of the singing voice, capturing the melodic and note-like aspects. The aperiodic VAE, on the other hand, models the noise-like, nonharmonic aspects, such as breathing and imperfections in the voice.
By integrating these two VAEs, the model can generate singing voices that are more natural and expressive compared to previous end-to-end singing voice synthesis approaches. The periodic VAE ensures the generated singing follows a clear melody, while the aperiodic VAE adds the necessary nuance and realism.
To address the challenge of limited singing voice data, the authors also introduce two additional techniques. First, they propose a self-supervised pre-training approach, where the model learns general representations of singing voices from unlabeled data. This helps the model better capture the underlying characteristics of singing voices.
Second, the researchers developed a semi-supervised training method that can effectively leverage both labeled and unlabeled singing voice data. This allows the model to benefit from the limited labeled data while also learning from the wider pool of unlabeled samples, resulting in improved performance.
Critical Analysis
The "Period Singer" model presented in the paper is a novel and promising approach to generating more natural-sounding artificial singing voices. By separating the periodic and aperiodic components of the singing voice and modeling them separately, the researchers have addressed a key limitation of previous end-to-end singing voice synthesis techniques.
However, the paper does not provide a thorough evaluation of the model's performance compared to state-of-the-art alternatives. While the authors mention that "Period Singer" outperforms previous methods, more detailed comparisons and subjective listening tests would be helpful to fully assess the model's capabilities.
Additionally, the paper does not discuss potential limitations or areas for future research. For example, it would be interesting to know how the model handles different singing styles or genres, or how it performs on more challenging datasets. The authors could also explore ways to further improve the model's efficiency and reduce the reliance on labeled data.
Overall, the "Period Singer" model represents an important advancement in the field of singing voice synthesis, and the paper provides a solid technical foundation for the approach. With further evaluation and refinement, this work could have significant implications for a wide range of applications that require natural-sounding artificial singing voices.
Conclusion
The "Period Singer" model introduced in this paper is a novel approach to end-to-end singing voice synthesis that integrates periodic and aperiodic variational autoencoders. By modeling the harmonic and noise-like aspects of singing voices separately, the model is able to generate more natural and expressive artificial singing voices.
The authors also propose effective techniques to address the challenge of limited singing voice data, including a self-supervised pre-training approach and a semi-supervised training method. These innovations further enhance the model's ability to produce high-quality synthetic singing voices, even in data-scarce scenarios.
While the technical details of the model are sound, the paper would benefit from a more thorough evaluation and discussion of potential limitations and future research directions. Nonetheless, the "Period Singer" framework represents a significant advancement in the field of singing voice synthesis, with promising applications in music production, virtual assistants, and other areas that require realistic-sounding artificial singing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Period Singer: Integrating Periodic and Aperiodic Variational Autoencoders for Natural-Sounding End-to-End Singing Voice Synthesis
Taewoo Kim, Choongsang Cho, Young Han Lee
In this paper, we present Period Singer, a novel end-to-end singing voice synthesis (SVS) model that utilizes variational inference for periodic and aperiodic components, aimed at producing natural-sounding waveforms. Recent end-to-end SVS models have demonstrated the capability of synthesizing high-fidelity singing voices. However, owing to deterministic pitch conditioning, they do not fully address the one-to-many problem. To address this problem, we present the Period Singer architecture, which integrates variational autoencoders for the periodic and aperiodic components. Additionally, our methodology eliminates the dependency on an external aligner by estimating the phoneme alignment through a monotonic alignment search within note boundaries. Our empirical evaluations show that Period Singer outperforms existing end-to-end SVS models on Mandarin and Korean datasets. The efficacy of the proposed method was further corroborated by ablation studies.
Read more9/12/2024
0
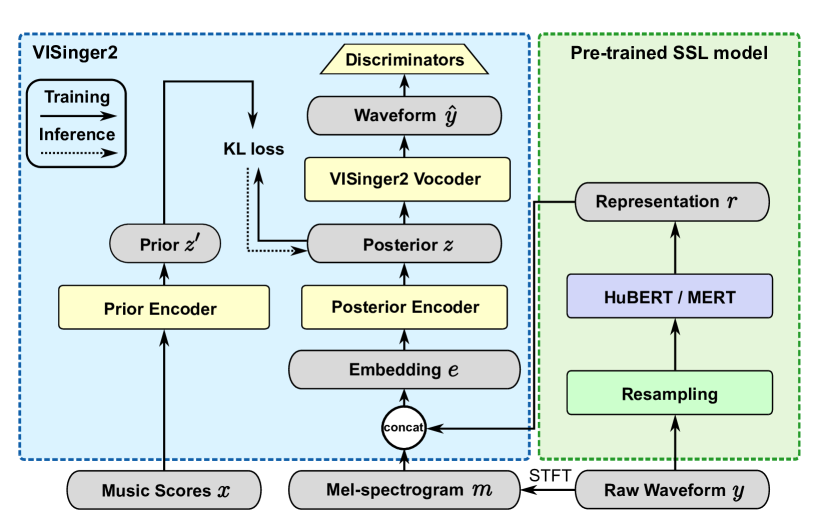
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Read more6/14/2024

0
DNN-based ensemble singing voice synthesis with interactions between singers
Hiroaki Hyodo, Shinnosuke Takamichi, Tomohiko Nakamura, Junya Koguchi, Hiroshi Saruwatari
We propose a singing voice synthesis (SVS) method for a more unified ensemble singing voice by modeling interactions between singers. Most existing SVS methods aim to synthesize a solo voice, and do not consider interactions between singers, i.e., adjusting one's own voice to the others' voices. Since the production of ensemble voices from solo singing voices ignores the interactions, it can degrade the unity of the vocal ensemble. Therefore, we propose a SVS that reproduces the interactions. It is based on an architecture that uses musical scores of multiple voice parts, and loss functions that simulate the interactions' effect to acoustic features. Experimental results show that our methods improve the unity of the vocal ensemble.
Read more9/17/2024

0
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
Yongqi Wang, Ruofan Hu, Rongjie Huang, Zhiqing Hong, Ruiqi Li, Wenrui Liu, Fuming You, Tao Jin, Zhou Zhao
Recent singing-voice-synthesis (SVS) methods have achieved remarkable audio quality and naturalness, yet they lack the capability to control the style attributes of the synthesized singing explicitly. We propose Prompt-Singer, the first SVS method that enables attribute controlling on singer gender, vocal range and volume with natural language. We adopt a model architecture based on a decoder-only transformer with a multi-scale hierarchy, and design a range-melody decoupled pitch representation that enables text-conditioned vocal range control while keeping melodic accuracy. Furthermore, we explore various experiment settings, including different types of text representations, text encoder fine-tuning, and introducing speech data to alleviate data scarcity, aiming to facilitate further research. Experiments show that our model achieves favorable controlling ability and audio quality. Audio samples are available at http://prompt-singer.github.io .
Read more7/10/2024