Pictures Of MIDI: Controlled Music Generation via Graphical Prompts for Image-Based Diffusion Inpainting

0
Sign in to get full access
Overview
- This paper introduces a novel approach called "Pictures of MIDI" for generating music through graphical prompts and image-based diffusion inpainting.
- The method allows users to create musical compositions by sketching visual prompts, which are then used to guide a diffusion model in generating MIDI-based music.
- This approach aims to provide a more intuitive and accessible way for non-musicians to engage in music creation, leveraging the power of AI-driven image-to-music generation.
Plain English Explanation
The researchers have developed a system that lets you create music just by drawing pictures. You don't need to know how to play an instrument or read sheet music. You simply sketch some shapes and lines on a digital canvas, and the system uses a special type of AI called a "diffusion model" to turn those drawings into a musical composition.
The key idea is that the visual prompts you provide act as a guide for the diffusion model, shaping the music it generates. So if you draw something that looks like musical notes or instruments, the system will try to incorporate those elements into the final piece of music.
This approach aims to make music creation more accessible and intuitive, especially for people who don't have a traditional musical background. Instead of struggling to master an instrument or learn complex music theory, you can just express your ideas visually and let the AI do the heavy lifting of turning that into an actual song.
Technical Explanation
The Pictures of MIDI system uses a diffusion model architecture inspired by recent work on sketch-guided image inpainting and semantically consistent video inpainting. The model takes in a user-provided visual prompt, which can include freeform sketches, shapes, and text annotations, and uses a steerable, long-term diffusion process to generate a MIDI-based musical composition that aligns with the input prompt.
Key technical innovations include:
- Graphical Prompt Encoding: The system uses a lazy diffusion transformer to efficiently encode the user's graphical prompt into a latent representation that can guide the music generation process.
- Diffusion-based Music Generation: The core of the system is a conditional diffusion model that generates MIDI-based music by iteratively refining a noisy input towards a final musical composition that matches the visual prompt.
- Prompt-Guided Synthesis: The diffusion process is steered by the encoded graphical prompt, allowing the model to generate music that is semantically consistent with the user's visual input, as demonstrated in FilterPrompt.
Critical Analysis
The "Pictures of MIDI" approach presents an intriguing and potentially transformative way to engage with music creation, especially for individuals without formal musical training. By leveraging the power of diffusion models and graphical prompts, the system aims to lower the barriers to entry and provide a more intuitive, visual-based interface for generating musical compositions.
However, the paper does not address certain limitations of the current approach. For instance, it is unclear how well the system would perform on more complex or abstract visual prompts, or how the generated music would fare in terms of aesthetic quality and coherence compared to compositions created by human musicians.
Additionally, the paper does not delve into potential ethical considerations, such as the implications of democratizing music creation and the potential for misuse or unintended consequences. As the field of AI-assisted creativity continues to evolve, it will be crucial to carefully consider these types of issues.
Conclusion
The "Pictures of MIDI" research represents a significant step forward in the quest to make music creation more accessible and approachable for a broader audience. By combining the power of diffusion models and graphical prompts, the system offers a novel and intriguing way for users to express their musical ideas without the need for traditional musical skills or knowledge.
While the paper highlights the technical merits of the approach, further exploration is needed to fully assess its practical implications and potential limitations. As the field of AI-driven music generation continues to advance, it will be important to carefully consider the ethical and societal ramifications of such technologies, ensuring that they are developed and deployed in a responsible and inclusive manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pictures Of MIDI: Controlled Music Generation via Graphical Prompts for Image-Based Diffusion Inpainting
Scott H. Hawley
Recent years have witnessed significant progress in generative models for music, featuring diverse architectures that balance output quality, diversity, speed, and user control. This study explores a user-friendly graphical interface enabling the drawing of masked regions for inpainting by an Hourglass Diffusion Transformer (HDiT) model trained on MIDI piano roll images. To enhance note generation in specified areas, masked regions can be repainted with extra noise. The non-latent HDiTs linear scaling with pixel count allows efficient generation in pixel space, providing intuitive and interpretable controls such as masking throughout the network and removing the need to operate in compressed latent spaces such as those provided by pretrained autoencoders. We demonstrate that, in addition to inpainting of melodies, accompaniment, and continuations, the use of repainting can help increase note density yielding musical structures closely matching user specifications such as rising, falling, or diverging melody and/or accompaniment, even when these lie outside the typical training data distribution. We achieve performance on par with prior results while operating at longer context windows, with no autoencoder, and can enable complex geometries for inpainting masks, increasing the options for machine-assisted composers to control the generated music.
Read more7/2/2024
0
Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
Liwei Lin, Gus Xia, Yixiao Zhang, Junyan Jiang
Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To address this gap, we propose a novel approach leveraging a parameter-efficient heterogeneous adapter combined with a masking training scheme. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. The source codes and a demo page showcasing our work are available at https://kikyo-16.github.io/AIR.
Read more6/11/2024
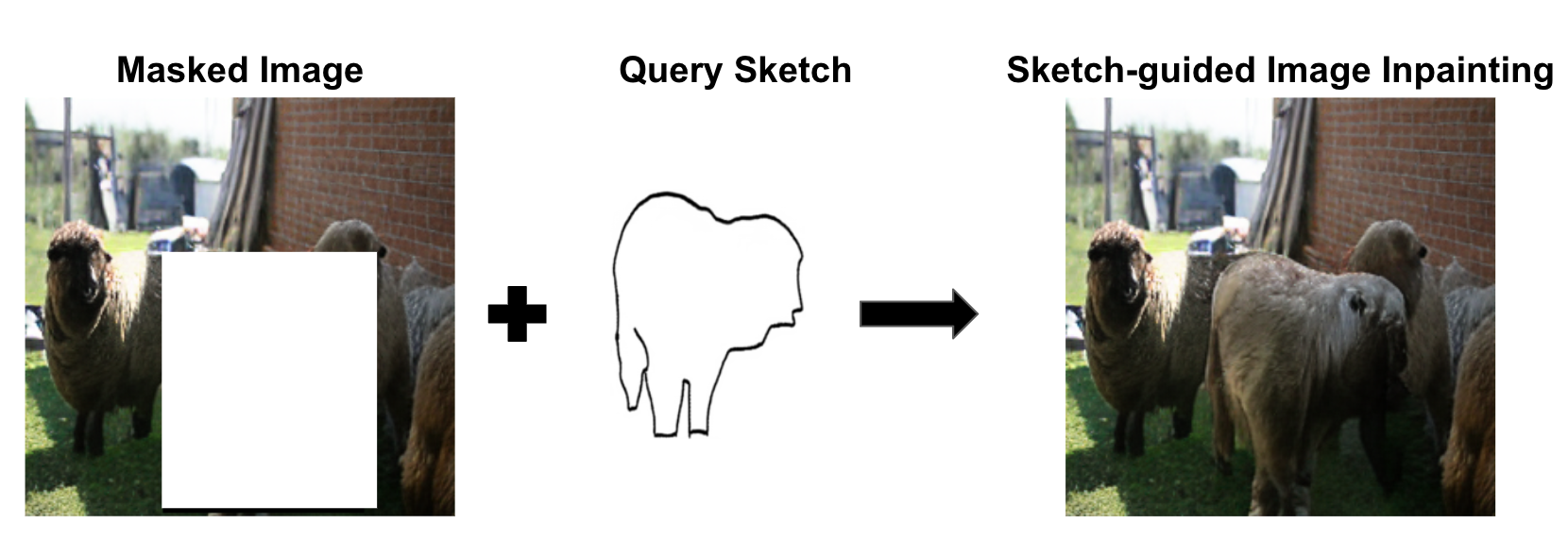
0
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Nakul Sharma, Aditay Tripathi, Anirban Chakraborty, Anand Mishra
In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
Read more4/19/2024

0
Disrupting Diffusion-based Inpainters with Semantic Digression
Geonho Son, Juhun Lee, Simon S. Woo
The fabrication of visual misinformation on the web and social media has increased exponentially with the advent of foundational text-to-image diffusion models. Namely, Stable Diffusion inpainters allow the synthesis of maliciously inpainted images of personal and private figures, and copyrighted contents, also known as deepfakes. To combat such generations, a disruption framework, namely Photoguard, has been proposed, where it adds adversarial noise to the context image to disrupt their inpainting synthesis. While their framework suggested a diffusion-friendly approach, the disruption is not sufficiently strong and it requires a significant amount of GPU and time to immunize the context image. In our work, we re-examine both the minimal and favorable conditions for a successful inpainting disruption, proposing DDD, a Digression guided Diffusion Disruption framework. First, we identify the most adversarially vulnerable diffusion timestep range with respect to the hidden space. Within this scope of noised manifold, we pose the problem as a semantic digression optimization. We maximize the distance between the inpainting instance's hidden states and a semantic-aware hidden state centroid, calibrated both by Monte Carlo sampling of hidden states and a discretely projected optimization in the token space. Effectively, our approach achieves stronger disruption and a higher success rate than Photoguard while lowering the GPU memory requirement, and speeding the optimization up to three times faster.
Read more7/16/2024