Probabilistic Constrained Reinforcement Learning with Formal Interpretability

0
🏅
Sign in to get full access
Overview
- Reinforcement learning can help with sequential decision-making problems, but interpreting the reward function and optimal policy is challenging.
- Representing these problems as probabilistic inference can provide mathematical tools to understand the dynamics and optimize the policy in a probabilistic way.
- The paper proposes a new method called Adaptive Wasserstein Variational Optimization (AWaVO) to address these interpretability challenges.
- AWaVO offers guaranteed interpretability through formal methods, including convergence guarantees, training transparency, and decision interpretation.
- The method is tested in simulations and practical quadrotor tasks, and outperforms state-of-the-art benchmarks in terms of performance and interpretability.
Plain English Explanation
Reinforcement learning is a powerful technique for solving sequential decision-making problems, such as how a robot should navigate through an environment. However, one persistent challenge is that it can be difficult to understand why the reinforcement learning algorithm is making the decisions it makes. In other words, the "reward function" and "optimal policy" that the algorithm learns are often not very interpretable.
The researchers in this paper propose a new approach that represents the decision-making problem as a form of "probabilistic inference." This means they model the problem in a way that allows them to use powerful mathematical tools to both understand the underlying dynamics and optimize the decision-making policy in a probabilistic manner. Their new method, called Adaptive Wasserstein Variational Optimization (AWaVO), is designed to provide guaranteed interpretability - you can understand why the algorithm is making the decisions it makes.
The key ideas behind AWaVO are:
- Formal methods: The researchers use rigorous mathematical techniques to ensure properties like convergence guarantees, training transparency, and intrinsic decision interpretation.
- Practical demonstrations: They show that AWaVO works well in simulations and real-world quadrotor control tasks, outperforming other state-of-the-art methods in terms of both performance and interpretability.
So in summary, this paper presents a new reinforcement learning approach that tackles the crucial challenge of interpretability, which could make these powerful algorithms more usable and trustworthy in real-world applications.
Technical Explanation
The paper proposes a novel Adaptive Wasserstein Variational Optimization (AWaVO) method to address the interpretability challenges in reinforcement learning. Reinforcement learning is effective for sequential decision-making problems with variable dynamics, but interpreting the reward function and optimal policy remains a persistent challenge.
The key innovation of AWaVO is to represent the sequential decision-making problem as a form of probabilistic inference. This probabilistic formulation allows the use of powerful mathematical tools from information theory and optimization to infer the stochastic dynamics and optimize the policy in a principled way.
Specifically, AWaVO employs formal methods to achieve three key properties:
- Convergence guarantee: AWaVO is proven to have an optimal global convergence rate.
- Training transparency: The training process of AWaVO is highly interpretable.
- Intrinsic decision-interpretation: The learned policy in AWaVO can be directly interpreted.
The researchers demonstrate the practicality of AWaVO through simulations and real-world quadrotor control tasks. Compared to state-of-the-art benchmarks like TRPO-IPO, PCPO, and CRPO, AWaVO offers a reasonable trade-off between high performance and sufficient interpretability.
Critical Analysis
The paper makes a strong case for the importance of interpretability in reinforcement learning and presents a novel approach, AWaVO, to address this challenge. The formal methods used to guarantee properties like convergence and training transparency are impressive and could help build trust in the decision-making process.
However, the paper does not delve into the potential limitations or caveats of the AWaVO method. For example, it would be useful to understand the computational complexity of the approach and how it scales with problem size or number of state/action variables. Additionally, the paper could have discussed potential failure modes or edge cases where the interpretability guarantees might break down.
Furthermore, the paper could have provided a more in-depth discussion of the implications of the probabilistic interpretation of the decision-making problem. While this is a key innovation, the paper does not explore how this framing might affect the types of problems that can be tackled or the applicability of the method in different domains.
Overall, the research presented in this paper is a valuable contribution to the field of interpretable reinforcement learning. The proposed AWaVO method demonstrates the potential for formal methods to enhance the transparency and trustworthiness of these powerful algorithms. However, further research is needed to fully understand the strengths, limitations, and broader implications of this approach.
Conclusion
This paper introduces a novel Adaptive Wasserstein Variational Optimization (AWaVO) method to address the interpretability challenges in reinforcement learning. By representing sequential decision-making problems as probabilistic inference, AWaVO leverages powerful mathematical tools to infer stochastic dynamics and optimize policies in a principled, interpretable way.
The key innovations of AWaVO include formal methods to guarantee convergence, training transparency, and intrinsic decision interpretation. The researchers demonstrate the practicality of their approach through simulations and real-world quadrotor control tasks, where AWaVO outperforms state-of-the-art benchmarks in terms of both performance and interpretability.
This work represents an important step towards making reinforcement learning more accessible and trustworthy for real-world applications. By enhancing the interpretability of these algorithms, the AWaVO method could help bridge the gap between the powerful decision-making capabilities of reinforcement learning and the need for human understanding and oversight. Further research in this area could yield valuable insights and unlock new frontiers for the practical deployment of reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Probabilistic Constrained Reinforcement Learning with Formal Interpretability
Yanran Wang, Qiuchen Qian, David Boyle
Reinforcement learning can provide effective reasoning for sequential decision-making problems with variable dynamics. Such reasoning in practical implementation, however, poses a persistent challenge in interpreting the reward function and the corresponding optimal policy. Consequently, representing sequential decision-making problems as probabilistic inference can have considerable value, as, in principle, the inference offers diverse and powerful mathematical tools to infer the stochastic dynamics whilst suggesting a probabilistic interpretation of policy optimization. In this study, we propose a novel Adaptive Wasserstein Variational Optimization, namely AWaVO, to tackle these interpretability challenges. Our approach uses formal methods to achieve the interpretability for convergence guarantee, training transparency, and intrinsic decision-interpretation. To demonstrate its practicality, we showcase guaranteed interpretability with an optimal global convergence rate in simulation and in practical quadrotor tasks. In comparison with state-of-the-art benchmarks including TRPO-IPO, PCPO and CRPO, we empirically verify that AWaVO offers a reasonable trade-off between high performance and sufficient interpretability.
Read more6/18/2024
🛠️
0
Constraint-Conditioned Policy Optimization for Versatile Safe Reinforcement Learning
Yihang Yao, Zuxin Liu, Zhepeng Cen, Jiacheng Zhu, Wenhao Yu, Tingnan Zhang, Ding Zhao
Safe reinforcement learning (RL) focuses on training reward-maximizing agents subject to pre-defined safety constraints. Yet, learning versatile safe policies that can adapt to varying safety constraint requirements during deployment without retraining remains a largely unexplored and challenging area. In this work, we formulate the versatile safe RL problem and consider two primary requirements: training efficiency and zero-shot adaptation capability. To address them, we introduce the Conditioned Constrained Policy Optimization (CCPO) framework, consisting of two key modules: (1) Versatile Value Estimation (VVE) for approximating value functions under unseen threshold conditions, and (2) Conditioned Variational Inference (CVI) for encoding arbitrary constraint thresholds during policy optimization. Our extensive experiments demonstrate that CCPO outperforms the baselines in terms of safety and task performance while preserving zero-shot adaptation capabilities to different constraint thresholds data-efficiently. This makes our approach suitable for real-world dynamic applications.
Read more5/1/2024
0
Overcoming Reward Overoptimization via Adversarial Policy Optimization with Lightweight Uncertainty Estimation
Xiaoying Zhang, Jean-Francois Ton, Wei Shen, Hongning Wang, Yang Liu
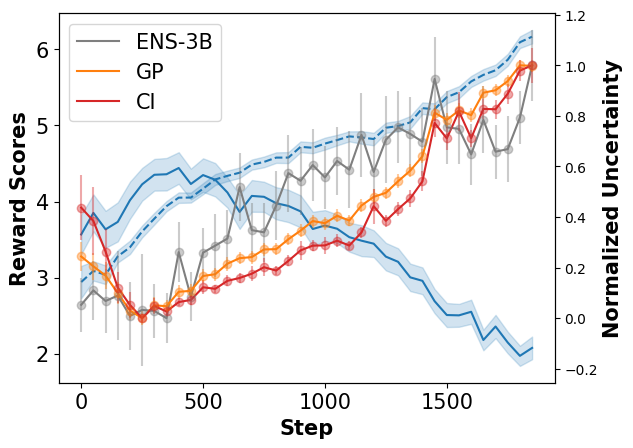
We introduce Adversarial Policy Optimization (AdvPO), a novel solution to the pervasive issue of reward over-optimization in Reinforcement Learning from Human Feedback (RLHF) for Large Language Models (LLMs). Over-optimization occurs when a reward model serves as an imperfect proxy for human preference, and RL-driven policy optimization erroneously exploits reward inaccuracies. In this paper, we begin by introducing a lightweight way to quantify uncertainties in rewards, relying solely on the last layer embeddings of the reward model, without the need for computationally expensive reward ensembles. AdvPO then addresses a distributionally robust optimization problem centred around the confidence interval of the reward model's predictions for policy improvement. Through comprehensive experiments on the Anthropic HH and TL;DR summarization datasets, we illustrate the efficacy of AdvPO in mitigating the overoptimization issue, consequently resulting in enhanced performance as evaluated through human-assisted evaluation.
Read more7/10/2024

0
Unveiling the Decision-Making Process in Reinforcement Learning with Genetic Programming
Manuel Eberhardinger, Florian Rupp, Johannes Maucher, Setareh Maghsudi
Despite tremendous progress, machine learning and deep learning still suffer from incomprehensible predictions. Incomprehensibility, however, is not an option for the use of (deep) reinforcement learning in the real world, as unpredictable actions can seriously harm the involved individuals. In this work, we propose a genetic programming framework to generate explanations for the decision-making process of already trained agents by imitating them with programs. Programs are interpretable and can be executed to generate explanations of why the agent chooses a particular action. Furthermore, we conduct an ablation study that investigates how extending the domain-specific language by using library learning alters the performance of the method. We compare our results with the previous state of the art for this problem and show that we are comparable in performance but require much less hardware resources and computation time.
Read more7/23/2024