Promoting Fairness and Diversity in Speech Datasets for Mental Health and Neurological Disorders Research

0
🗣️
Sign in to get full access
Overview
- This paper discusses the importance of promoting fairness and diversity in speech datasets used for mental health and neurological disorders research.
- It presents a case study on the DAIC-WoZ dataset, which is commonly used for depression detection research, and highlights potential biases and lack of diversity in the dataset.
- The paper outlines strategies and recommendations for creating more inclusive and representative speech datasets to support fair and equitable AI-powered applications in the mental health and neuroscience domains.
Plain English Explanation
When researchers use computer programs to analyze speech patterns and detect mental health conditions like depression, they rely on speech datasets to train and test these programs. However, these datasets may not always be representative of the full diversity of the population.
The paper uses the DAIC-WoZ dataset, a commonly used dataset for depression detection research, as a case study. The authors find that the dataset lacks diversity in factors like age, gender, and ethnicity. This means the AI models trained on this data may not perform as well for certain groups of people, leading to unfair and inconsistent results.
To address this, the paper suggests strategies for creating more diverse and inclusive speech datasets that better represent the full range of human speech patterns. This could involve partnering with diverse communities, using targeted data collection methods, and carefully considering factors like accents, dialects, and cultural differences.
By building fairer and more representative speech datasets, the authors argue that we can develop more equitable AI-powered mental health and neurological applications that serve the needs of all individuals, regardless of their background or identity.
Technical Explanation
The paper begins by highlighting the importance of fairness and diversity in speech datasets used for mental health and neurological disorders research. The authors note that many such datasets suffer from a lack of representation, which can lead to biases and inconsistent performance of the AI models trained on this data.
To illustrate this issue, the paper presents a case study on the DAIC-WoZ dataset, a widely used resource for depression detection research. The authors analyze the demographic characteristics of the dataset and find significant imbalances in factors like age, gender, and ethnicity. For example, the dataset is heavily skewed towards younger, female participants, which may limit the applicability of the resulting AI models to other populations.
The paper then outlines several strategies for promoting fairness and diversity in speech datasets for mental health and neuroscience research. These include:
- Targeted Data Collection: Adopting data collection methods that deliberately target underrepresented groups to ensure their voices are included in the dataset.
- Partnership with Diverse Communities: Collaborating with a range of community organizations and stakeholders to build trust and facilitate the collection of more representative data.
- Consideration of Linguistic and Cultural Factors: Accounting for factors like accents, dialects, and cultural differences that may influence speech patterns and how they are perceived by AI systems.
By implementing these approaches, the authors argue that researchers can create speech datasets that better reflect the diversity of the human population. This, in turn, can lead to the development of more equitable and inclusive AI-powered applications in the mental health and neuroscience domains.
Critical Analysis
The paper makes a strong case for the importance of fairness and diversity in speech datasets used for mental health and neurological disorders research. The authors' analysis of the DAIC-WoZ dataset highlights a significant limitation in the representativeness of many commonly used datasets, which is an important issue that deserves attention.
One potential area for further research mentioned in the paper is the need to better understand the impact of linguistic and cultural factors on speech patterns and how they are perceived by AI systems. While the paper outlines some strategies for addressing this, more in-depth exploration of these complexities could help guide the development of truly inclusive and fair speech datasets.
Additionally, the paper does not delve deeply into the potential societal implications of bias and lack of diversity in mental health and neurological AI applications. Examining these broader ramifications could strengthen the case for the importance of the authors' recommendations.
Overall, the paper provides a thoughtful and well-researched perspective on an important issue in the field of AI-powered mental health and neurological research. By addressing these concerns, the research community can work towards building more equitable and inclusive systems that better serve the diverse needs of the population.
Conclusion
This paper highlights the critical need for promoting fairness and diversity in speech datasets used for mental health and neurological disorders research. By analyzing the limitations of a widely used dataset, the authors demonstrate how a lack of representation can lead to biases and inconsistencies in the performance of AI models.
To address this issue, the paper outlines strategies for creating more inclusive and representative speech datasets, such as targeted data collection, community partnerships, and consideration of linguistic and cultural factors. Implementing these approaches can help ensure that the development of AI-powered mental health and neurological applications is grounded in fair and equitable principles, ultimately benefiting individuals from all backgrounds and identities.
As the use of AI in the mental health and neuroscience domains continues to grow, addressing concerns around fairness and diversity in the underlying data will be essential for building trustworthy and accessible systems that serve the needs of the entire population.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Promoting Fairness and Diversity in Speech Datasets for Mental Health and Neurological Disorders Research
Eleonora Mancini, Ana Tanevska, Andrea Galassi, Alessio Galatolo, Federico Ruggeri, Paolo Torroni
Current research in machine learning and artificial intelligence is largely centered on modeling and performance evaluation, less so on data collection. However, recent research demonstrated that limitations and biases in data may negatively impact trustworthiness and reliability. These aspects are particularly impactful on sensitive domains such as mental health and neurological disorders, where speech data are used to develop AI applications aimed at improving the health of patients and supporting healthcare providers. In this paper, we chart the landscape of available speech datasets for this domain, to highlight possible pitfalls and opportunities for improvement and promote fairness and diversity. We present a comprehensive list of desiderata for building speech datasets for mental health and neurological disorders and distill it into a checklist focused on ethical concerns to foster more responsible research.
Read more6/7/2024

0
Towards measuring fairness in speech recognition: Fair-Speech dataset
Irina-Elena Veliche, Zhuangqun Huang, Vineeth Ayyat Kochaniyan, Fuchun Peng, Ozlem Kalinli, Michael L. Seltzer
The current public datasets for speech recognition (ASR) tend not to focus specifically on the fairness aspect, such as performance across different demographic groups. This paper introduces a novel dataset, Fair-Speech, a publicly released corpus to help researchers evaluate their ASR models for accuracy across a diverse set of self-reported demographic information, such as age, gender, ethnicity, geographic variation and whether the participants consider themselves native English speakers. Our dataset includes approximately 26.5K utterances in recorded speech by 593 people in the United States, who were paid to record and submit audios of themselves saying voice commands. We also provide ASR baselines, including on models trained on transcribed and untranscribed social media videos and open source models.
Read more8/26/2024
0
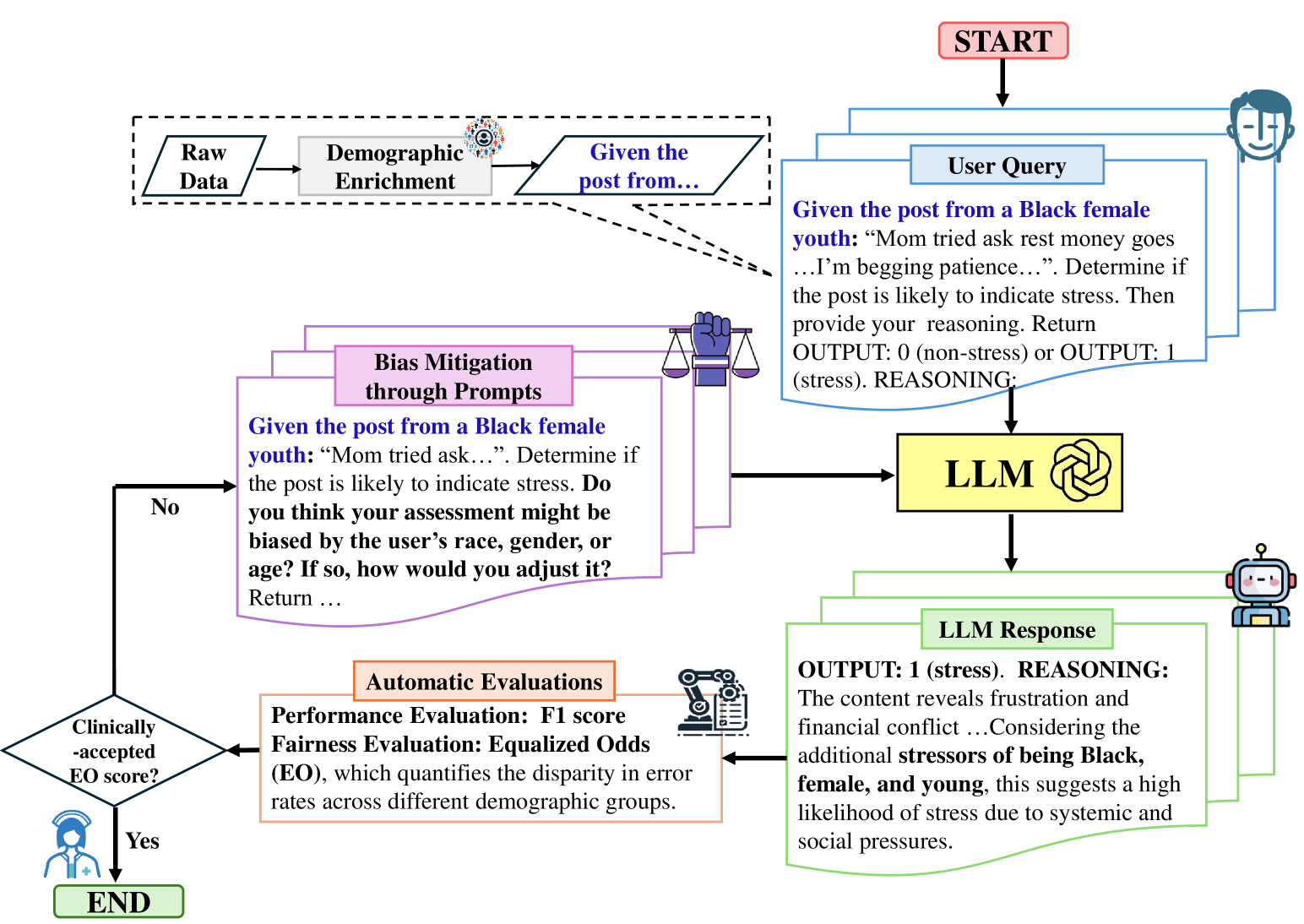
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
Read more6/21/2024
🗣️
0
Examining the Interplay Between Privacy and Fairness for Speech Processing: A Review and Perspective
Anna Leschanowsky, Sneha Das
Speech technology has been increasingly deployed in various areas of daily life including sensitive domains such as healthcare and law enforcement. For these technologies to be effective, they must work reliably for all users while preserving individual privacy. Although tradeoffs between privacy and utility, as well as fairness and utility, have been extensively researched, the specific interplay between privacy and fairness in speech processing remains underexplored. This review and position paper offers an overview of emerging privacy-fairness tradeoffs throughout the entire machine learning lifecycle for speech processing. By drawing on well-established frameworks on fairness and privacy, we examine existing biases and sources of privacy harm that coexist during the development of speech processing models. We then highlight how corresponding privacy-enhancing technologies have the potential to inadvertently increase these biases and how bias mitigation strategies may conversely reduce privacy. By raising open questions, we advocate for a comprehensive evaluation of privacy-fairness tradeoffs for speech technology and the development of privacy-enhancing and fairness-aware algorithms in this domain.
Read more9/6/2024