Question Translation Training for Better Multilingual Reasoning

0
🏋️
Sign in to get full access
Overview
- Large language models (LLMs) excel at reasoning tasks but struggle with non-English languages
- Typical solution is "translate-training" - translating instructions to multiple languages, then training on the multilingual data
- This approach is costly and results in poorly translated data due to formatting issues
- This paper explores "question alignment" - training the model to translate reasoning questions into English using parallel question data
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can perform a variety of complex reasoning tasks. However, they tend to perform much worse when working with languages other than English. This is likely due to the fact that most of the data used to train these models consists of English text and instructions.
A common solution to this problem is called "translate-training." In this approach, the instructions and materials used to train the LLM are translated into multiple languages, and the model is then trained on this multilingual data. While this can help the model perform better in different languages, it also comes with some downsides. Translating all of the training data is a costly and time-consuming process, and the resulting translations may not be of high quality, particularly when it comes to formatting mathematical reasoning steps and concepts.
To address these issues, the researchers in this paper explore an alternative approach called "question alignment." Instead of translating all of the training data, they focus on training the LLM to translate reasoning questions into English. By doing this, they can leverage the large amount of high-quality English instruction data that is typically used to train these models, while still unlocking the LLM's ability to perform multilingual reasoning.
Technical Explanation
The key idea behind the question alignment approach is to fine-tune the LLM on a dataset of parallel question pairs, where each question is presented in both the original language and in English. By training the model to translate the reasoning questions into English, the researchers were able to elicit better multilingual reasoning performance from the LLM, without the need for costly and error-prone full translation of all training data.
The researchers tested this approach using the LLaMA2-13B LLM, and evaluated its performance on two multilingual reasoning benchmarks: MGSM and MSVAMP. Their results showed that the question alignment approach consistently outperformed the traditional translate-training approach, with an average improvement of 11.3% and 16.1% accuracy across the ten languages tested.
Critical Analysis
The paper presents a clever and novel approach to improving the multilingual reasoning capabilities of LLMs. However, it's important to note that the researchers only tested their method on a single LLM (LLaMA2-13B) and two specific reasoning benchmarks. It would be valuable to see how the question alignment approach performs on a wider range of LLMs and multilingual tasks, to better understand its broader applicability and limitations.
Additionally, the paper does not delve into the potential downsides or caveats of the question alignment approach. For example, it's unclear how the method would scale as the number of target languages increases, or how it would perform on more open-ended reasoning tasks that don't have a clear "correct" translation.
Overall, the research presented in this paper is a promising step towards eliciting better multilingual reasoning from LLMs, but further investigation and validation would be valuable to fully assess the strengths and weaknesses of this approach.
Conclusion
This paper introduces a novel "question alignment" approach to improving the multilingual reasoning capabilities of large language models (LLMs). By training the LLM to translate reasoning questions into English, rather than translating all training data, the researchers were able to achieve consistent performance improvements over the traditional "translate-training" method.
The results presented in the paper suggest that this targeted, in-domain language alignment technique can be an effective way to leverage the wealth of high-quality English data available to train LLMs, while still unlocking their potential for multilingual reasoning. As AI systems become increasingly capable and ubiquitous, techniques like this that can improve their performance across languages will be crucial for ensuring equitable access and usability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Question Translation Training for Better Multilingual Reasoning
Wenhao Zhu, Shujian Huang, Fei Yuan, Shuaijie She, Jiajun Chen, Alexandra Birch
Large language models show compelling performance on reasoning tasks but they tend to perform much worse in languages other than English. This is unsurprising given that their training data largely consists of English text and instructions. A typical solution is to translate instruction data into all languages of interest, and then train on the resulting multilingual data, which is called translate-training. This approach not only incurs high cost, but also results in poorly translated data due to the non-standard formatting of mathematical chain-of-thought. In this paper, we explore the benefits of question alignment, where we train the model to translate reasoning questions into English by finetuning on X-English parallel question data. In this way we perform targeted, in-domain language alignment which makes best use of English instruction data to unlock the LLMs' multilingual reasoning abilities. Experimental results on LLaMA2-13B show that question alignment leads to consistent improvements over the translate-training approach: an average improvement of 11.3% and 16.1% accuracy across ten languages on the MGSM and MSVAMP multilingual reasoning benchmarks. The project will be available at: https://github.com/NJUNLP/QAlign.
Read more7/2/2024

0
The Power of Question Translation Training in Multilingual Reasoning: Broadened Scope and Deepened Insights
Wenhao Zhu, Shujian Huang, Fei Yuan, Cheng Chen, Jiajun Chen, Alexandra Birch
Bridging the significant gap between large language model's English and non-English performance presents a great challenge. While some previous studies attempt to mitigate this gap with translated training data, the recently proposed question alignment approach leverages the model's English expertise to improve multilingual performance with minimum usage of expensive, error-prone translation. In this paper, we explore how broadly this method can be applied by examining its effects in reasoning with executable code and reasoning with common sense. We also explore how to apply this approach efficiently to extremely large language models using proxy-tuning. Experiment results on multilingual reasoning benchmarks mGSM, mSVAMP and xCSQA demonstrate that the question alignment approach can be used to boost multilingual performance across diverse reasoning scenarios, model families, and sizes. For instance, when applied to the LLaMA2 models, our method brings an average accuracy improvements of 12.2% on mGSM even with the 70B model. To understand the mechanism of its success, we analyze representation space, chain-of-thought and translation data scales, which reveals how question translation training strengthens language alignment within LLMs and shapes their working patterns.
Read more5/3/2024

0
Eliciting Better Multilingual Structured Reasoning from LLMs through Code
Bryan Li, Tamer Alkhouli, Daniele Bonadiman, Nikolaos Pappas, Saab Mansour
The development of large language models (LLM) has shown progress on reasoning, though studies have largely considered either English or simple reasoning tasks. To address this, we introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multilingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus demonstrating our techniques maintain general-purpose abilities.
Read more6/13/2024
0
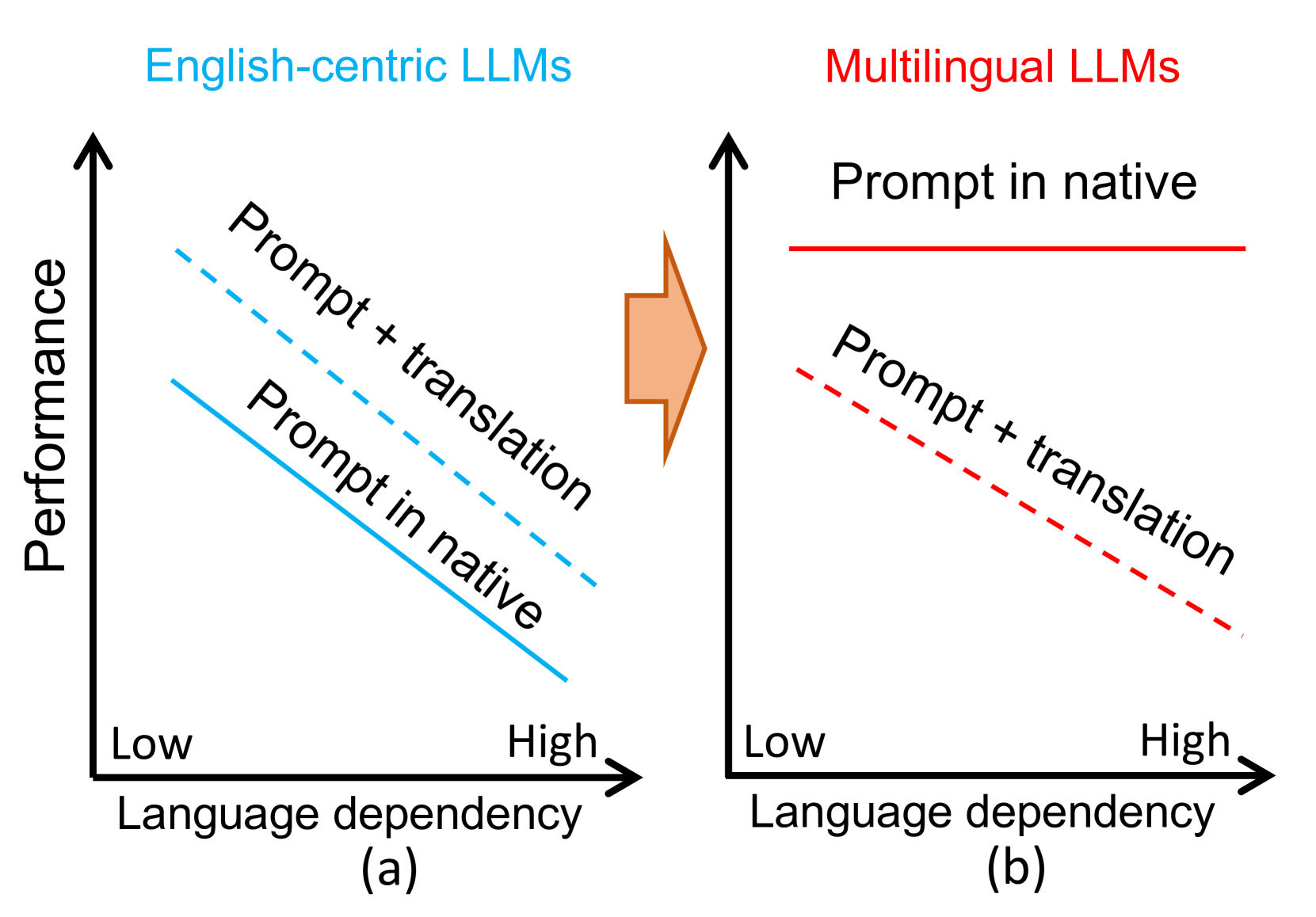
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
Read more6/21/2024