Volumetric Semantically Consistent 3D Panoptic Mapping

0

Sign in to get full access
Overview
- This paper presents a method for volumetric 3D panoptic mapping that is semantically consistent across different sensor modalities.
- The approach involves mapping semantic and instance-level information into a unified 3D representation, allowing for better understanding and reasoning about complex 3D environments.
- Key innovations include multi-view semantic fusion, instance-aware mapping, and temporal consistency.
Plain English Explanation
The paper describes a new technique for creating detailed 3D maps of the world that not only show the shapes and locations of objects, but also understand what those objects are and how they relate to each other. This is an important capability for applications like self-driving cars, robots, and augmented reality, where machines need to have a deep understanding of their 3D environment.
The core idea is to fuse information from different camera views to build a comprehensive 3D model that captures both the semantic (what type of object it is) and instance-level (individual object) information. By maintaining temporal consistency over time, the 3D map can be kept up-to-date as the environment changes. This allows the system to reason about the 3D world in a more sophisticated way, understanding not just the raw geometry, but the semantic meaning and relationships between objects.
The authors demonstrate the effectiveness of their approach on standard 3D mapping benchmarks, showing improvements in accuracy and completeness compared to prior methods. This represents an important step forward in the field of 3D perception and understanding, with applications in areas like autonomous vehicles, robotics, and augmented reality.
Technical Explanation
The key technical contributions of this work are:
-
Multi-View Semantic Fusion: The system takes input from multiple camera views and fuses the semantic and instance-level information into a unified 3D representation. This allows the model to resolve ambiguities and inconsistencies across different viewpoints.
-
Instance-Aware Mapping: The 3D map maintains individual object instances rather than just semantic classes, enabling more sophisticated reasoning about the environment. This builds on prior work in open-set 3D semantic instance mapping.
-
Temporal Consistency: By tracking objects over time, the system is able to update the 3D map in a temporally consistent manner, accounting for changes in the environment. This improves the overall coherence and stability of the 3D representation.
The authors evaluate their approach on standard 3D mapping benchmarks, demonstrating improvements in semantic segmentation accuracy, instance segmentation quality, and overall 3D reconstruction completeness compared to previous methods. The results highlight the benefits of their multi-modal, semantically-aware 3D mapping approach.
Critical Analysis
One potential limitation of the proposed method is its reliance on multiple camera views. In some scenarios, such as a single-camera robot or a monocular self-driving car, only a single viewpoint may be available. The authors do not address how their technique would scale to such cases, where the fusion of semantic and instance-level information across views is not possible.
Additionally, the paper does not provide a detailed analysis of the computational complexity and runtime performance of the system. For many real-world applications, such as autonomous navigation or augmented reality, the ability to operate in real-time is a critical requirement. The authors could have explored the trade-offs between accuracy and efficiency, and discussed potential optimizations to improve the system's practical viability.
Finally, while the results on standard benchmarks are promising, it would be valuable to see the approach evaluated in more realistic, real-world scenarios. The authors could have included case studies or qualitative examples that demonstrate the system's performance in challenging, dynamic environments with occlusions, lighting changes, and other practical challenges.
Conclusion
This paper presents a novel approach for volumetric 3D panoptic mapping that integrates semantic and instance-level information in a unified representation. By fusing multi-view data and maintaining temporal consistency, the system is able to build more comprehensive and semantically meaningful 3D maps of complex environments.
The authors demonstrate the effectiveness of their method on standard benchmarks, highlighting improvements over previous techniques. This work represents an important step forward in the field of 3D perception and understanding, with potential applications in areas like autonomous vehicles, robotics, and augmented reality. Further research is needed to address the limitations and explore the practical deployment of such systems in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Volumetric Semantically Consistent 3D Panoptic Mapping
Yang Miao, Iro Armeni, Marc Pollefeys, Daniel Barath
We introduce an online 2D-to-3D semantic instance mapping algorithm aimed at generating comprehensive, accurate, and efficient semantic 3D maps suitable for autonomous agents in unstructured environments. The proposed approach is based on a Voxel-TSDF representation used in recent algorithms. It introduces novel ways of integrating semantic prediction confidence during mapping, producing semantic and instance-consistent 3D regions. Further improvements are achieved by graph optimization-based semantic labeling and instance refinement. The proposed method achieves accuracy superior to the state of the art on public large-scale datasets, improving on a number of widely used metrics. We also highlight a downfall in the evaluation of recent studies: using the ground truth trajectory as input instead of a SLAM-estimated one substantially affects the accuracy, creating a large gap between the reported results and the actual performance on real-world data.
Read more7/9/2024

0
Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Laksh Nanwani, Kumaraditya Gupta, Aditya Mathur, Swayam Agrawal, A. H. Abdul Hafez, K. Madhava Krishna
Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
Read more4/30/2024

0
QueSTMaps: Queryable Semantic Topological Maps for 3D Scene Understanding
Yash Mehan, Kumaraditya Gupta, Rohit Jayanti, Anirudh Govil, Sourav Garg, Madhava Krishna
Understanding the structural organisation of 3D indoor scenes in terms of rooms is often accomplished via floorplan extraction. Robotic tasks such as planning and navigation require a semantic understanding of the scene as well. This is typically achieved via object-level semantic segmentation. However, such methods struggle to segment out topological regions like kitchen in the scene. In this work, we introduce a two-step pipeline. First, we extract a topological map, i.e., floorplan of the indoor scene using a novel multi-channel occupancy representation. Then, we generate CLIP-aligned features and semantic labels for every room instance based on the objects it contains using a self-attention transformer. Our language-topology alignment supports natural language querying, e.g., a place to cook locates the kitchen. We outperform the current state-of-the-art on room segmentation by ~20% and room classification by ~12%. Our detailed qualitative analysis and ablation studies provide insights into the problem of joint structural and semantic 3D scene understanding.
Read more4/10/2024
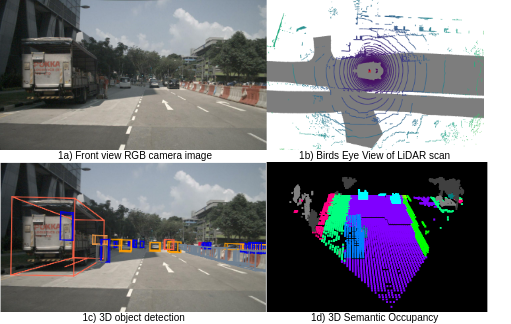
0
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
Read more5/21/2024