Reasoning Runtime Behavior of a Program with LLM: How Far Are We?

0

Sign in to get full access
Overview
- This paper evaluates the performance of large language models (LLMs) by analyzing their runtime behavior when executing programs.
- The researchers developed a framework called CodeMind to challenge LLMs on their ability to reason about and execute programs.
- The study goes beyond just measuring model accuracy and explores the models' underlying reasoning capabilities when faced with programmatic tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have made impressive advances in natural language processing, but how well can they handle more complex tasks like coding and program execution? The researchers in this paper wanted to dig deeper and evaluate LLMs beyond just their surface-level performance on standard benchmarks.
They created a framework called CodeMind that presents LLMs with a variety of programming challenges. Rather than just asking the models to generate or complete code, CodeMind evaluates how well the models can actually reason about the behavior and execution of programs.
For example, the researchers might give an LLM a program and ask it to predict what the output will be, or to identify any bugs or errors in the code. This taps into the models' underlying understanding of programming concepts, control flow, data structures, and so on.
The goal is to go beyond just accuracy and really understand the reasoning capabilities of these large language models. Can they actually reason about "wild" programs, or are they just good at pattern matching and generating plausible-sounding text?
By evaluating LLMs on these more challenging, program-oriented tasks, the researchers hope to gain insights that go beyond just mathematical or coding competency and shed light on the models' broader reasoning abilities.
Technical Explanation
The paper introduces a framework called CodeMind that is designed to challenge large language models (LLMs) on their ability to reason about and execute programs. The key idea is to move beyond simply evaluating LLM performance on standard natural language benchmarks, and instead assess their underlying capabilities when it comes to understanding and manipulating code.
CodeMind presents LLMs with a variety of programming-related tasks, such as predicting the output of a given program, identifying bugs or errors in code, or explaining the high-level behavior of a piece of software. By analyzing the runtime behavior of the models as they attempt to execute these tasks, the researchers aim to gain insights into the models' reasoning processes and programming comprehension.
The paper describes several specific experiments conducted using CodeMind. For example, one experiment involved giving LLMs a program and asking them to predict the output. The researchers found that while the models were able to generate plausible-looking code, their ability to correctly predict program behavior was limited. This suggests that the models may be relying more on pattern matching and language modeling than on true program understanding.
Another experiment looked at the models' ability to identify bugs or errors in code. The researchers introduced various types of bugs, ranging from simple syntax errors to more complex logical flaws, and found that the LLMs struggled to consistently and accurately detect these issues.
The paper also discusses experiments that explored the models' understanding of higher-level programming concepts, such as control flow, data structures, and algorithm design. Again, the results indicated that the LLMs had significant limitations in these areas, often failing to grasp the underlying logic and reasoning behind the code.
Overall, the key finding of the paper is that while LLMs have made impressive strides in natural language processing, their ability to reason about and execute programs is still quite limited. The researchers argue that more work is needed to develop LLMs that can truly understand and manipulate code at a deeper level.
Critical Analysis
The paper makes a compelling case for the need to move beyond traditional accuracy-based evaluations of large language models (LLMs) and to delve deeper into their underlying reasoning capabilities, particularly when it comes to understanding and executing programs.
The CodeMind framework developed by the researchers is a valuable contribution, as it provides a structured way to challenge LLMs on more complex, program-oriented tasks. By analyzing the runtime behavior of the models as they attempt to complete these tasks, the researchers are able to gain insights that go beyond simple measures of correctness.
However, it's important to note that the paper's findings are limited to the specific experiments and tasks included in the CodeMind framework. While the researchers make a strong argument for the importance of this type of evaluation, it's possible that LLMs could perform better on other types of programming-related tasks or with further refinement and training.
Additionally, the paper doesn't explore the potential reasons behind the LLMs' limitations in program understanding and execution. It would be interesting to see a deeper analysis of the underlying architectural or training factors that contribute to these shortcomings, as this could inform future model development and training strategies.
Overall, the paper makes a valuable contribution to the ongoing discussion around the capabilities and limitations of large language models. By challenging these models on more complex, reasoning-oriented tasks, the researchers have highlighted important areas for further research and development.
Conclusion
This paper presents a novel framework called CodeMind for evaluating the performance of large language models (LLMs) on tasks related to program execution and reasoning. The key finding is that while LLMs have made significant advancements in natural language processing, their ability to understand and manipulate code at a deeper level is still quite limited.
The CodeMind framework allows the researchers to go beyond simple accuracy-based evaluations and explore the underlying reasoning capabilities of the models. By analyzing the runtime behavior of the LLMs as they attempt to complete various programming-related tasks, the study sheds light on the models' strengths and weaknesses in areas such as control flow, data structures, and algorithm design.
The results suggest that while LLMs can generate plausible-looking code, they struggle to accurately predict program behavior, identify bugs, and reason about higher-level programming concepts. This highlights the need for further research and development to create LLMs that can truly understand and manipulate code at a more fundamental level.
Overall, this paper makes an important contribution to the ongoing efforts to evaluate and improve the capabilities of large language models, pushing beyond traditional benchmarks and exploring the models' underlying reasoning abilities in the context of program execution.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reasoning Runtime Behavior of a Program with LLM: How Far Are We?
Junkai Chen, Zhiyuan Pan, Xing Hu, Zhenhao Li, Ge Li, Xin Xia
Large language models for code (i.e., code LLMs) have shown strong code understanding and generation capabilities. To evaluate the capabilities of code LLMs in various aspects, many benchmarks have been proposed (e.g., HumanEval and ClassEval). Code reasoning is one of the most essential abilities of code LLMs, but existing benchmarks for code reasoning are not sufficient. Typically, they focus on predicting the input and output of a program, ignoring the evaluation of the intermediate behavior during program execution, as well as the logical consistency (e.g., the model should not give the correct output if the prediction of execution path is wrong) when performing the reasoning. To address these problems, in this paper, we propose a framework, namely REval, for evaluating code reasoning abilities and consistency of code LLMs with program execution. We utilize existing code benchmarks and adapt them to new benchmarks within our framework. A large-scale empirical study is conducted and most LLMs show unsatisfactory performance on both Runtime Behavior Reasoning (i.e., an average accuracy of 44.4%) and Incremental Consistency Evaluation (i.e., an average IC score of 10.3). Evaluation results of current code LLMs reflect the urgent need for the community to strengthen the code reasoning capability of code LLMs. Our code, data, and newname leaderboard are available at https://r-eval.github.io.
Read more9/24/2024
0
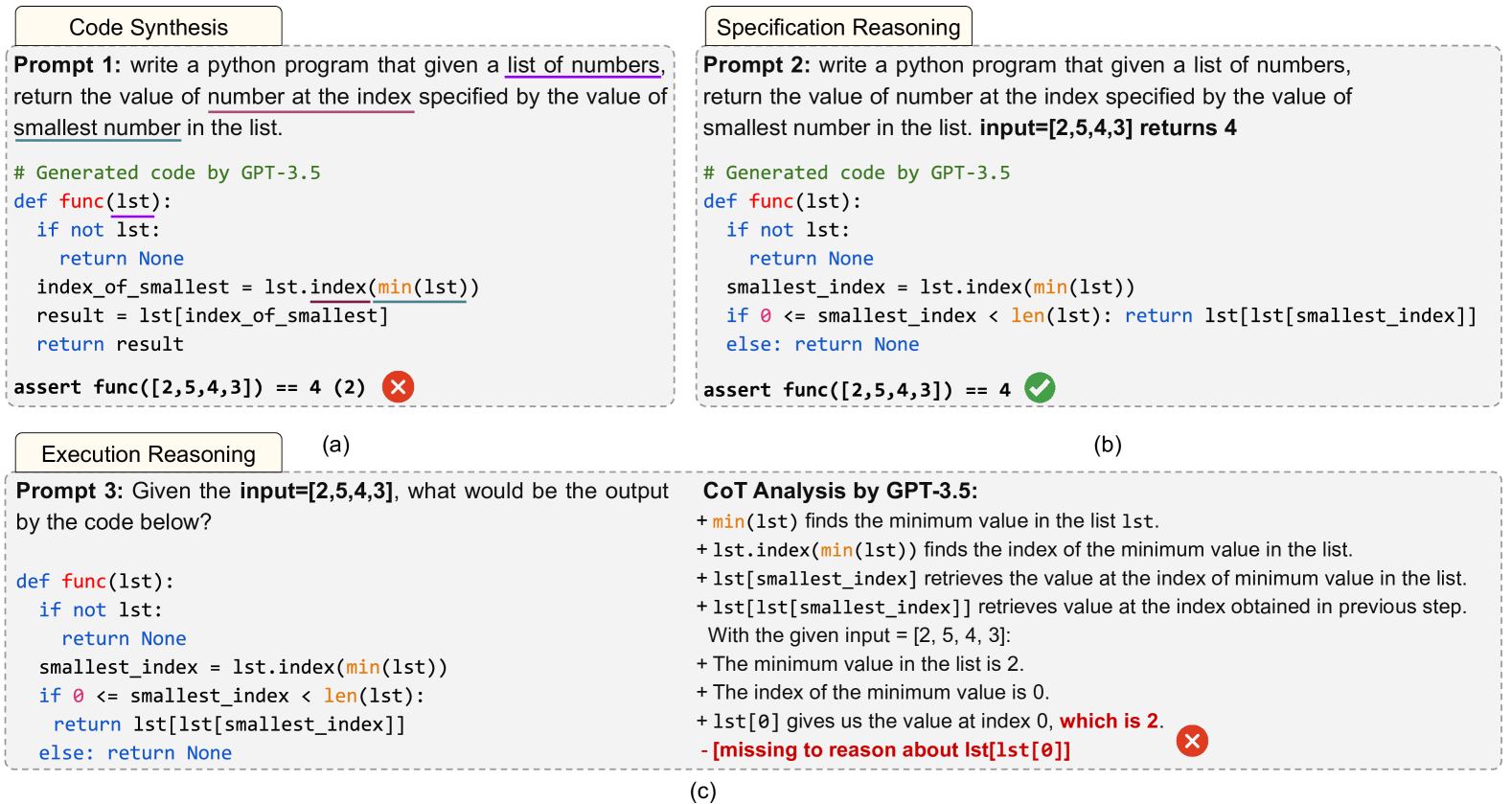
CodeMind: A Framework to Challenge Large Language Models for Code Reasoning
Changshu Liu, Shizhuo Dylan Zhang, Ali Reza Ibrahimzada, Reyhaneh Jabbarvand
Solely relying on test passing to evaluate Large Language Models (LLMs) for code synthesis may result in unfair assessment or promoting models with data leakage. As an alternative, we introduce CodeMind, a framework designed to gauge the code reasoning abilities of LLMs. CodeMind currently supports three code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). The first two evaluate models to predict the execution output of an arbitrary code or code the model could correctly synthesize. The third one evaluates the extent to which LLMs implement the specified expected behavior. Our extensive evaluation of nine LLMs across five benchmarks in two different programming languages using CodeMind shows that LLMs fairly follow control flow constructs and, in general, explain how inputs evolve to output, specifically for simple programs and the ones they can correctly synthesize. However, their performance drops for code with higher complexity, non-trivial logical and arithmetic operators, non-primitive types, and API calls. Furthermore, we observe that, while correlated, specification reasoning (essential for code synthesis) does not imply execution reasoning (essential for broader programming tasks such as testing and debugging): ranking LLMs based on test passing can be different compared to code reasoning.
Read more4/4/2024

0
Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on sophisticated reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
Read more8/7/2024

0
Can LLMs Reason in the Wild with Programs?
Yuan Yang, Siheng Xiong, Ali Payani, Ehsan Shareghi, Faramarz Fekri
Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild
Read more6/21/2024