RecGPT: Generative Pre-training for Text-based Recommendation

0
🏋️
Sign in to get full access
Overview
- Researchers present a large language model called RecGPT-7B and its instruction-following variant, RecGPT-7B-Instruct, for text-based recommendation tasks.
- The models outperform previous baselines on rating prediction and sequential recommendation tasks.
- The researchers are releasing the RecGPT models and their pre-training and fine-tuning datasets to support future research and applications.
Plain English Explanation
The researchers have developed a new large language model, RecGPT-7B, that is specialized for making text-based recommendations. This means the model can understand and generate text to provide personalized recommendations, such as for products, movies, or other items.
The model is trained on a large amount of data, allowing it to generate high-quality and relevant recommendations. The researchers also created an "instruction-following" version of the model, RecGPT-7B-Instruct, which can follow specific instructions or prompts to generate recommendations.
In tests, the RecGPT-7B-Instruct model outperformed previous strong recommendation models, showing it can make better recommendations based on text-based information. The researchers are making the RecGPT models and their training data publicly available, so other researchers and developers can build on this work and create new text-based recommendation applications.
Technical Explanation
The researchers present the RecGPT-7B model, a large language model that has been domain-adapted and fully trained for text-based recommendation tasks. They also introduce an instruction-following variant, RecGPT-7B-Instruct, which can follow specific prompts or instructions to generate personalized recommendations.
The models were trained on large datasets of text data related to recommendation, including product reviews, movie descriptions, and other relevant information. This pretraining allowed the models to learn the patterns and language of recommendation domains.
The researchers then fine-tuned the models on specific recommendation tasks, such as rating prediction and sequential recommendation. In these tasks, the models demonstrated strong performance, outperforming previous state-of-the-art baselines.
The key innovation of the RecGPT models is their ability to leverage large language models and text data to provide personalized and contextual recommendations. This contrasts with traditional recommendation systems that rely more on structured data, such as user profiles and item metadata.
By releasing the RecGPT models and datasets, the researchers aim to facilitate further research and development in the area of text-based recommendation and the use of large language models for recommendation systems.
Critical Analysis
The researchers acknowledge that the RecGPT models are trained on general text data and may not fully capture all the nuances and dynamics of real-world recommendation scenarios. There could be biases or limitations in the training data that affect the models' performance in certain domains or applications.
Additionally, the instruction-following capability of RecGPT-7B-Instruct, while a promising feature, may be dependent on the quality and relevance of the provided instructions. Further research is needed to understand the model's robustness and generalization to a wider range of recommendation tasks and user preferences.
It would also be valuable to investigate the interpretability and explainability of the RecGPT models' recommendation decisions, as this could help users understand and trust the system's outputs.
Overall, the RecGPT models represent an exciting development in the field of text-based recommendation, and the researchers' commitment to open sourcing the models and datasets is commendable. However, as with any new technology, further research and real-world testing will be necessary to fully assess the models' capabilities and limitations.
Conclusion
The RecGPT models presented in this research paper represent a significant advancement in the field of text-based recommendation systems. By leveraging large language models and comprehensive text data, the researchers have created models that can generate personalized and contextual recommendations, outperforming previous baselines.
The release of the RecGPT models and their associated datasets will enable other researchers and developers to build upon this work, exploring new applications and further improving the capabilities of text-based recommendation systems. As these systems become more advanced, they have the potential to enhance user experiences and provide more tailored and relevant recommendations across a wide range of domains.
While the research has limitations and areas for further exploration, the RecGPT models demonstrate the power of combining large language models with recommendation tasks, paving the way for more intelligent and user-centric recommendation systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
RecGPT: Generative Pre-training for Text-based Recommendation
Hoang Ngo, Dat Quoc Nguyen
We present the first domain-adapted and fully-trained large language model, RecGPT-7B, and its instruction-following variant, RecGPT-7B-Instruct, for text-based recommendation. Experimental results on rating prediction and sequential recommendation tasks show that our model, RecGPT-7B-Instruct, outperforms previous strong baselines. We are releasing our RecGPT models as well as their pre-training and fine-tuning datasets to facilitate future research and downstream applications in text-based recommendation. Public huggingface links to our RecGPT models and datasets are available at: https://github.com/VinAIResearch/RecGPT
Read more5/22/2024
0
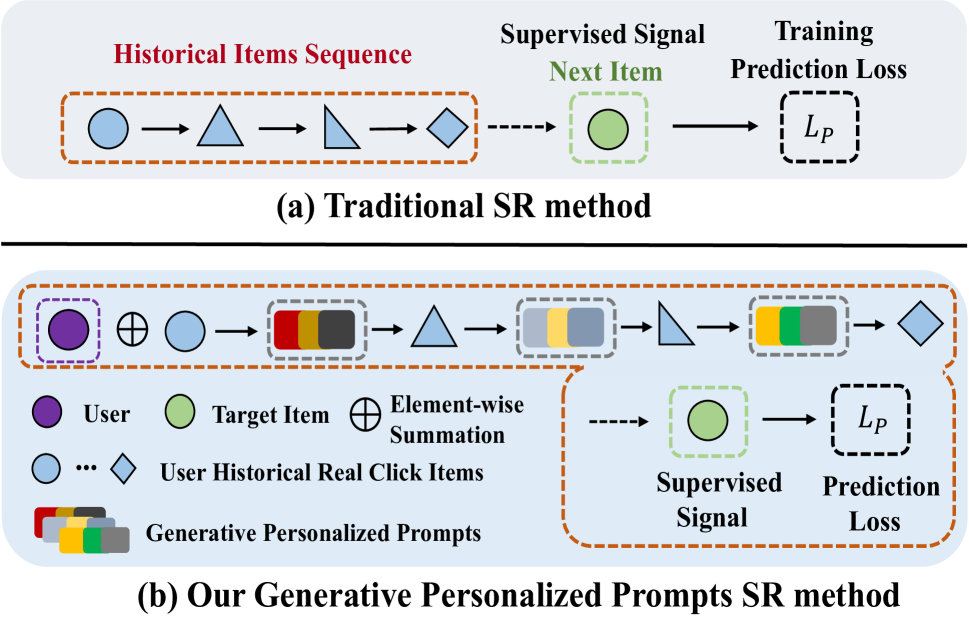
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Yabin Zhang, Wenhui Yu, Erhan Zhang, Xu Chen, Lantao Hu, Peng Jiang, Kun Gai
ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
Read more4/16/2024

0
IDGenRec: LLM-RecSys Alignment with Textual ID Learning
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, Yongfeng Zhang
Generative recommendation based on Large Language Models (LLMs) have transformed the traditional ranking-based recommendation style into a text-to-text generation paradigm. However, in contrast to standard NLP tasks that inherently operate on human vocabulary, current research in generative recommendations struggles to effectively encode recommendation items within the text-to-text framework using concise yet meaningful ID representations. To better align LLMs with recommendation needs, we propose IDGen, representing each item as a unique, concise, semantically rich, platform-agnostic textual ID using human language tokens. This is achieved by training a textual ID generator alongside the LLM-based recommender, enabling seamless integration of personalized recommendations into natural language generation. Notably, as user history is expressed in natural language and decoupled from the original dataset, our approach suggests the potential for a foundational generative recommendation model. Experiments show that our framework consistently surpasses existing models in sequential recommendation under standard experimental setting. Then, we explore the possibility of training a foundation recommendation model with the proposed method on data collected from 19 different datasets and tested its recommendation performance on 6 unseen datasets across different platforms under a completely zero-shot setting. The results show that the zero-shot performance of the pre-trained foundation model is comparable to or even better than some traditional recommendation models based on supervised training, showing the potential of the IDGen paradigm serving as the foundation model for generative recommendation. Code and data are open-sourced at https://github.com/agiresearch/IDGenRec.
Read more5/20/2024

0
GenRec: Generative Personalized Sequential Recommendation
Panfeng Cao, Pietro Lio
Sequential recommendation is a task to capture hidden user preferences from historical user item interaction data and recommend next items for the user. Significant progress has been made in this domain by leveraging classification based learning methods. Inspired by the recent paradigm of 'pretrain, prompt and predict' in NLP, we consider sequential recommendation as a sequence to sequence generation task and propose a novel model named Generative Recommendation (GenRec). Unlike classification based models that learn explicit user and item representations, GenRec utilizes the sequence modeling capability of Transformer and adopts the masked item prediction objective to effectively learn the hidden bidirectional sequential patterns. Different from existing generative sequential recommendation models, GenRec does not rely on manually designed hard prompts. The input to GenRec is textual user item sequence and the output is top ranked next items. Moreover, GenRec is lightweight and requires only a few hours to train effectively in low-resource settings, making it highly applicable to real-world scenarios and helping to democratize large language models in the sequential recommendation domain. Our extensive experiments have demonstrated that GenRec generalizes on various public real-world datasets and achieves state-of-the-art results. Our experiments also validate the effectiveness of the the proposed masked item prediction objective that improves the model performance by a large margin.
Read more8/30/2024