Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
2304.01982
2
0
🔎
Abstract
Multi-vector retrieval models such as ColBERT [Khattab and Zaharia, 2020] allow token-level interactions between queries and documents, and hence achieve state of the art on many information retrieval benchmarks. However, their non-linear scoring function cannot be scaled to millions of documents, necessitating a three-stage process for inference: retrieving initial candidates via token retrieval, accessing all token vectors, and scoring the initial candidate documents. The non-linear scoring function is applied over all token vectors of each candidate document, making the inference process complicated and slow. In this paper, we aim to simplify the multi-vector retrieval by rethinking the role of token retrieval. We present XTR, ConteXtualized Token Retriever, which introduces a simple, yet novel, objective function that encourages the model to retrieve the most important document tokens first. The improvement to token retrieval allows XTR to rank candidates only using the retrieved tokens rather than all tokens in the document, and enables a newly designed scoring stage that is two-to-three orders of magnitude cheaper than that of ColBERT. On the popular BEIR benchmark, XTR advances the state-of-the-art by 2.8 nDCG@10 without any distillation. Detailed analysis confirms our decision to revisit the token retrieval stage, as XTR demonstrates much better recall of the token retrieval stage compared to ColBERT.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Multi-vector retrieval models like ColBERT allow for more advanced interactions between queries and documents, leading to state-of-the-art performance on information retrieval tasks.
- However, their non-linear scoring function is computationally expensive, requiring a complex three-stage inference process.
- This paper introduces XTR, a novel approach that simplifies multi-vector retrieval by rethinking the token retrieval stage.
Plain English Explanation
The paper discusses a new way to improve information retrieval systems, which are used to search through large collections of documents and find the most relevant ones. Typical search engines use simple keyword matching, but more advanced "multi-vector" models like ColBERT can achieve better results by examining the relationships between individual words in the query and document.
The downside of these multi-vector models is that their scoring process is complex and computationally intensive, requiring multiple steps to first find candidate documents and then score them. The authors of this paper propose a new approach called XTR that simplifies this process. XTR focuses on improving the initial token retrieval stage, encouraging the model to identify the most important words in the document first. This allows XTR to rank documents using only the retrieved tokens, rather than having to look at all the tokens in each document, making the overall process much faster.
The researchers tested XTR on a popular benchmark and found that it outperformed previous state-of-the-art models, while also demonstrating significant improvements in the key token retrieval stage. This suggests that rethinking this foundational component of information retrieval systems can lead to meaningful performance gains.
Technical Explanation
The paper introduces XTR, a novel "Contextualized Token Retriever" model for multi-vector retrieval. Multi-vector models like ColBERT allow for more fine-grained interactions between query and document tokens, leading to state-of-the-art performance on tasks like the BEIR benchmark.
However, the non-linear scoring function used by these models is computationally expensive, requiring a complex three-stage inference process: 1) retrieving initial candidate documents, 2) accessing all token vectors for those candidates, and 3) scoring the candidates using the non-linear function. This makes the overall system slow and difficult to scale to large document collections.
XTR aims to simplify the multi-vector retrieval process by rethinking the token retrieval stage. The authors introduce a novel objective function that encourages the model to retrieve the most important document tokens first. This allows XTR to rank candidate documents using only the retrieved tokens, rather than having to access all tokens in each document. This newly designed scoring stage is two to three orders of magnitude cheaper than ColBERT's approach.
Experiments on the BEIR benchmark show that XTR achieves state-of-the-art results, outperforming ColBERT by 2.8 nDCG@10 without any additional distillation. Analysis confirms that XTR demonstrates much better recall in the token retrieval stage compared to ColBERT, validating the authors' decision to focus on this key component of the retrieval process.
Critical Analysis
The paper makes a compelling case for re-examining the token retrieval stage in multi-vector retrieval models. By designing a novel objective function to improve this component, the authors are able to significantly simplify the overall inference process, leading to substantial performance gains.
However, the paper does not delve deeply into the potential limitations or drawbacks of the XTR approach. For example, it's unclear how well the model would scale to extremely large document collections, as the authors only evaluate on the BEIR benchmark, which may not be representative of real-world scenarios.
Additionally, the paper does not discuss the potential trade-offs between the improved token retrieval and the simplified scoring stage. It's possible that prioritizing the most important tokens could lead to some loss of nuance or context that the more comprehensive ColBERT approach was able to capture.
Further research would be needed to fully understand the strengths and weaknesses of the XTR approach, as well as its broader applicability to different information retrieval tasks and datasets. Nonetheless, the core idea of rethinking the token retrieval stage is a valuable contribution that could inspire further innovations in this area.
Conclusion
This paper presents XTR, a novel multi-vector retrieval model that simplifies the inference process by focusing on improving the token retrieval stage. By designing a novel objective function, XTR is able to retrieve the most important document tokens first, enabling a faster and more efficient scoring stage.
The results on the BEIR benchmark demonstrate that XTR can outperform state-of-the-art models like ColBERT while also significantly improving the key token retrieval component. This suggests that rethinking the fundamental building blocks of information retrieval systems can lead to meaningful performance gains.
The ideas presented in this paper could have broader implications for the development of more efficient and scalable retrieval systems, which are crucial for powering a wide range of applications, from search engines to question answering and real-time search. By continuing to learn when not to trust language models, researchers can push the boundaries of what's possible in information retrieval and unlock new capabilities for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
BTR: Binary Token Representations for Efficient Retrieval Augmented Language Models
Qingqing Cao, Sewon Min, Yizhong Wang, Hannaneh Hajishirzi
0
0
Retrieval augmentation addresses many critical problems in large language models such as hallucination, staleness, and privacy leaks. However, running retrieval-augmented language models (LMs) is slow and difficult to scale due to processing large amounts of retrieved text. We introduce binary token representations (BTR), which use 1-bit vectors to precompute every token in passages, significantly reducing computation during inference. Despite the potential loss of accuracy, our new calibration techniques and training objectives restore performance. Combined with offline and runtime compression, this only requires 127GB of disk space for encoding 3 billion tokens in Wikipedia. Our experiments show that on five knowledge-intensive NLP tasks, BTR accelerates state-of-the-art inference by up to 4x and reduces storage by over 100x while maintaining over 95% task performance.
5/6/2024
🤔
Semi-Parametric Retrieval via Binary Token Index
Jiawei Zhou, Li Dong, Furu Wei, Lei Chen
0
0
The landscape of information retrieval has broadened from search services to a critical component in various advanced applications, where indexing efficiency, cost-effectiveness, and freshness are increasingly important yet remain less explored. To address these demands, we introduce Semi-parametric Vocabulary Disentangled Retrieval (SVDR). SVDR is a novel semi-parametric retrieval framework that supports two types of indexes: an embedding-based index for high effectiveness, akin to existing neural retrieval methods; and a binary token index that allows for quick and cost-effective setup, resembling traditional term-based retrieval. In our evaluation on three open-domain question answering benchmarks with the entire Wikipedia as the retrieval corpus, SVDR consistently demonstrates superiority. It achieves a 3% higher top-1 retrieval accuracy compared to the dense retriever DPR when using an embedding-based index and an 9% higher top-1 accuracy compared to BM25 when using a binary token index. Specifically, the adoption of a binary token index reduces index preparation time from 30 GPU hours to just 2 CPU hours and storage size from 31 GB to 2 GB, achieving a 90% reduction compared to an embedding-based index.
5/6/2024
Information Retrieval with Entity Linking
Dahlia Shehata
0
0
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
4/16/2024
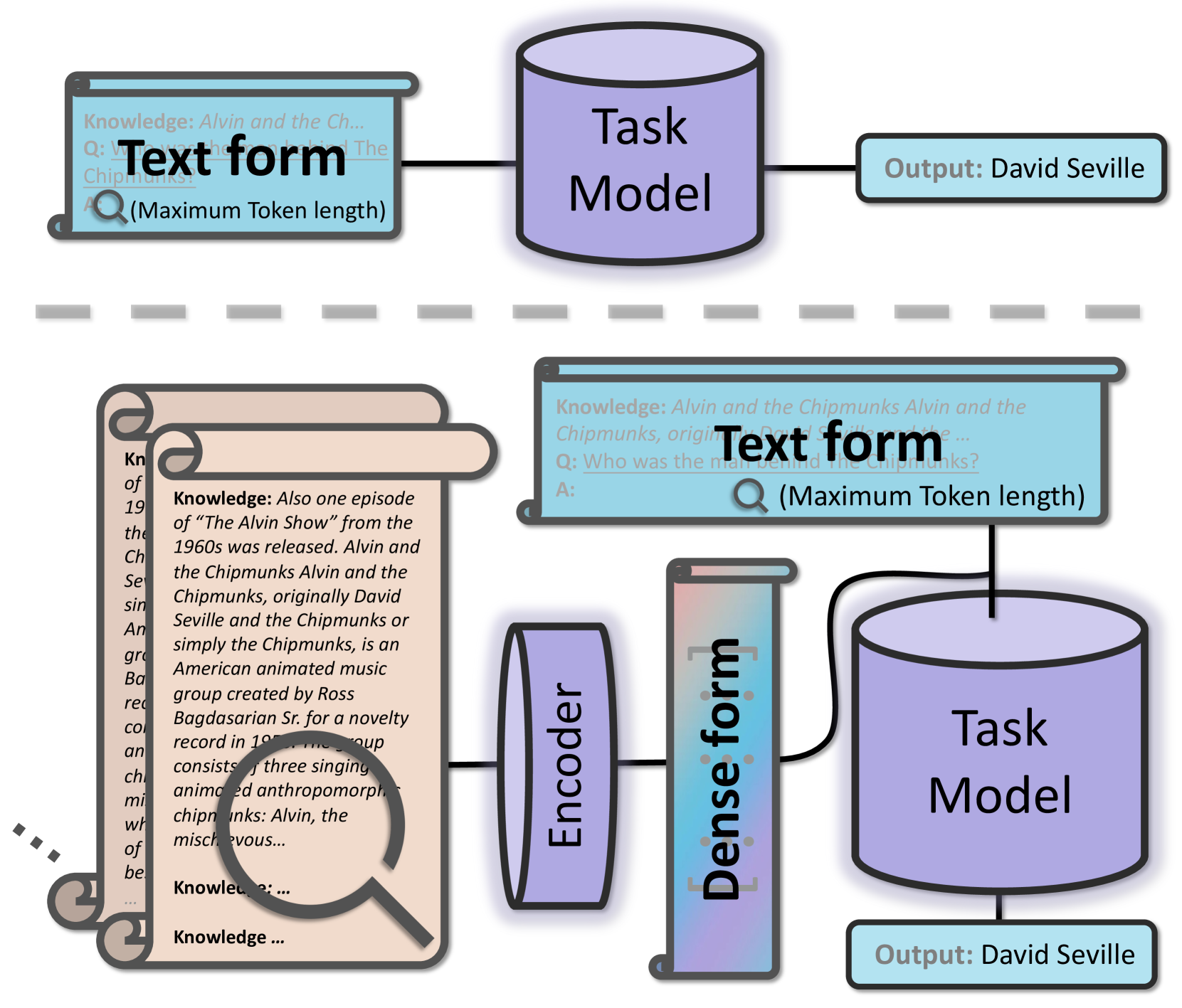
Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
Zhuo Chen, Xinyu Wang, Yong Jiang, Pengjun Xie, Fei Huang, Kewei Tu
0
0
In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
4/3/2024