RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold

0
Sign in to get full access
Overview
- This paper investigates the use of reinforcement learning (RL) on incorrect synthetic data to improve the math reasoning abilities of large language models (LLMs).
- The key finding is that using RL on "flawed" synthetic data can boost the efficiency of LLM math reasoning by up to 8 times, compared to training on correct data alone.
- This work builds on previous research on using synthetic data to enhance LLM capabilities, mitigating issues with synthetic data, and scaling up synthetic data generation.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can perform a wide range of language-related tasks, including math reasoning. However, training LLMs to reason effectively about math can be challenging. This paper explores a novel approach to improve the math reasoning abilities of LLMs.
The researchers found that by using reinforcement learning (RL) on "incorrect" or "flawed" synthetic data, they were able to significantly boost the efficiency of LLM math reasoning, up to 8 times better than training on correct data alone. This is a surprising result, as one might expect that training on inaccurate data would harm performance.
The key insight is that the RL process is able to learn from the mistakes in the synthetic data, and use that knowledge to build more robust and flexible math reasoning capabilities in the LLM. This builds on previous work on using synthetic data to enhance LLM capabilities, mitigating issues with synthetic data, and scaling up synthetic data generation.
The implications of this research are significant, as it suggests that carefully designed synthetic data, combined with RL, could be a powerful way to improve the reasoning abilities of large language models in a wide range of domains, not just math.
Technical Explanation
The paper presents a novel approach to enhancing the math reasoning capabilities of large language models (LLMs) using reinforcement learning (RL) on synthetic data.
The researchers first generate a large dataset of synthetic math problems and solutions, which includes both correct and "flawed" examples. They then train an RL agent to solve these math problems, using the synthetic data as the training environment.
Surprisingly, the researchers found that the RL agent trained on the flawed synthetic data significantly outperformed an LLM trained on the correct synthetic data alone. Specifically, they saw an 8-fold increase in the efficiency of the LLM's math reasoning abilities.
The key insight is that the RL process is able to learn from the mistakes in the synthetic data, and use that knowledge to build more robust and flexible math reasoning capabilities in the LLM. This builds on previous work on using synthetic data to enhance LLM capabilities, mitigating issues with synthetic data, and scaling up synthetic data generation.
The researchers also demonstrate that this approach can be further enhanced by using a theorem-proving system to generate more targeted, "difficult" synthetic math problems. This allows the RL agent to focus on the most challenging aspects of math reasoning.
Critical Analysis
The paper presents a compelling and innovative approach to improving the math reasoning capabilities of large language models. The key finding, that training on flawed synthetic data can actually boost performance, is both surprising and potentially very impactful.
However, the paper does not fully address some potential limitations and concerns with this approach. For example, it's unclear how well the RL-trained LLM would generalize to real-world math problems, which may have different characteristics than the synthetic data. There are also questions around the scalability and robustness of the synthetic data generation process.
Additionally, while the paper cites related work on mitigating issues with synthetic data, it would be helpful to see a more in-depth discussion of the potential risks and downsides of using flawed synthetic data, even with RL.
Overall, this paper represents an important step forward in the field of optimizing language models for reasoning abilities, but further research is needed to fully understand the capabilities and limitations of this approach.
Conclusion
This paper presents a novel and surprising finding: using reinforcement learning on incorrect synthetic data can significantly boost the math reasoning abilities of large language models, by up to 8 times compared to training on correct data alone.
The key insight is that the RL process is able to learn from the mistakes in the synthetic data, and use that knowledge to build more robust and flexible math reasoning capabilities in the LLM. This work builds on previous research on enhancing LLM capabilities with synthetic data, mitigating issues with synthetic data, and scaling up synthetic data generation.
The implications of this research are significant, as it suggests that carefully designed synthetic data, combined with RL, could be a powerful way to improve the reasoning abilities of large language models in a wide range of domains, not just math. However, further research is needed to fully understand the limitations and potential risks of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold
Amrith Setlur, Saurabh Garg, Xinyang Geng, Naman Garg, Virginia Smith, Aviral Kumar
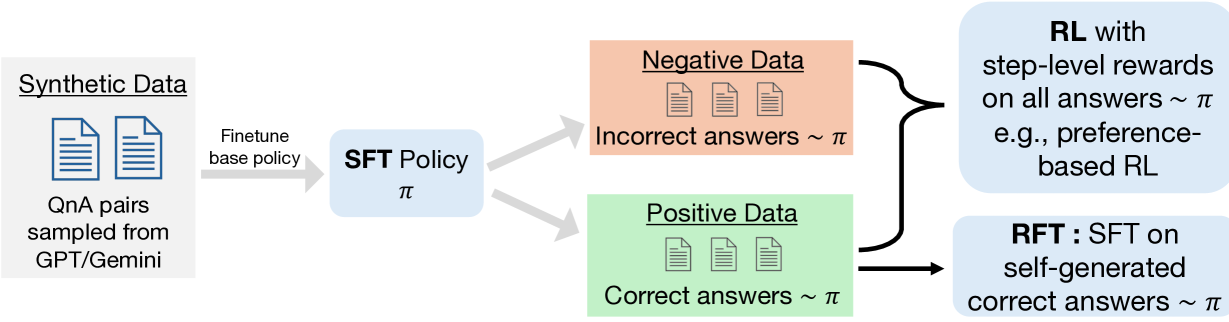
Training on model-generated synthetic data is a promising approach for finetuning LLMs, but it remains unclear when it helps or hurts. In this paper, we investigate this question for math reasoning via an empirical study, followed by building a conceptual understanding of our observations. First, we find that while the typical approach of finetuning a model on synthetic correct or positive problem-solution pairs generated by capable models offers modest performance gains, sampling more correct solutions from the finetuned learner itself followed by subsequent fine-tuning on this self-generated data $textbf{doubles}$ the efficiency of the same synthetic problems. At the same time, training on model-generated positives can amplify various spurious correlations, resulting in flat or even inverse scaling trends as the amount of data increases. Surprisingly, we find that several of these issues can be addressed if we also utilize negative responses, i.e., model-generated responses that are deemed incorrect by a final answer verifier. Crucially, these negatives must be constructed such that the training can appropriately recover the utility or advantage of each intermediate step in the negative response. With this per-step scheme, we are able to attain consistent gains over only positive data, attaining performance similar to amplifying the amount of synthetic data by $mathbf{8 times}$. We show that training on per-step negatives can help to unlearn spurious correlations in the positive data, and is equivalent to advantage-weighted reinforcement learning (RL), implying that it inherits robustness benefits of RL over imitating positive data alone.
Read more6/21/2024

0
An Empirical Study of Validating Synthetic Data for Formula Generation
Usneek Singh, Jos'e Cambronero, Sumit Gulwani, Aditya Kanade, Anirudh Khatry, Vu Le, Mukul Singh, Gust Verbruggen
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Read more7/24/2024

0
Exploring Mathematical Extrapolation of Large Language Models with Synthetic Data
Haolong Li, Yu Ma, Yinqi Zhang, Chen Ye, Jie Chen
Large Language Models (LLMs) have shown excellent performance in language understanding, text generation, code synthesis, and many other tasks, while they still struggle in complex multi-step reasoning problems, such as mathematical reasoning. In this paper, through a newly proposed arithmetical puzzle problem, we show that the model can perform well on multi-step reasoning tasks via fine-tuning on high-quality synthetic data. Experimental results with the open-llama-3B model on three different test datasets show that not only the model can reach a zero-shot pass@1 at 0.44 on the in-domain dataset, it also demonstrates certain generalization capabilities on the out-of-domain datasets. Specifically, this paper has designed two out-of-domain datasets in the form of extending the numerical range and the composing components of the arithmetical puzzle problem separately. The fine-tuned models have shown encouraging performance on these two far more difficult tasks with the zero-shot pass@1 at 0.33 and 0.35, respectively.
Read more6/5/2024

0
Unveiling the Flaws: Exploring Imperfections in Synthetic Data and Mitigation Strategies for Large Language Models
Jie Chen, Yupeng Zhang, Bingning Wang, Wayne Xin Zhao, Ji-Rong Wen, Weipeng Chen
Synthetic data has been proposed as a solution to address the issue of high-quality data scarcity in the training of large language models (LLMs). Studies have shown that synthetic data can effectively improve the performance of LLMs on downstream benchmarks. However, despite its potential benefits, our analysis suggests that there may be inherent flaws in synthetic data. The uniform format of synthetic data can lead to pattern overfitting and cause significant shifts in the output distribution, thereby reducing the model's instruction-following capabilities. Our work delves into these specific flaws associated with question-answer (Q-A) pairs, a prevalent type of synthetic data, and presents a method based on unlearning techniques to mitigate these flaws. The empirical results demonstrate the effectiveness of our approach, which can reverse the instruction-following issues caused by pattern overfitting without compromising performance on benchmarks at relatively low cost. Our work has yielded key insights into the effective use of synthetic data, aiming to promote more robust and efficient LLM training.
Read more6/19/2024