Sanskrit Knowledge-based Systems: Annotation and Computational Tools

0
🗣️
Sign in to get full access
Overview
- The paper addresses the challenges and opportunities in developing knowledge systems for the Sanskrit language, with a focus on question answering.
- The researchers propose a framework for automated construction of knowledge graphs, introduce annotation tools for ontology-driven and general-purpose tasks, and offer a collection of web interfaces, tools, and software libraries.
- These contributions enhance the accessibility and accuracy of Sanskrit text analysis, and pave the way for advancements in knowledge representation and language processing.
- The research aims to preserve, understand, and utilize the rich linguistic information in Sanskrit texts.
Plain English Explanation
The researchers are working on building better systems to understand and work with the Sanskrit language. Sanskrit is an ancient Indian language with a rich history and a vast body of literature. However, it can be challenging to work with Sanskrit texts using computers and technology.
To address this, the researchers have developed several new tools and frameworks. They have created a way to automatically build knowledge graphs from Sanskrit texts. This allows computers to better understand the relationships and connections between different concepts in the language.
The researchers have also created annotation tools that can help humans and computers work together to analyze Sanskrit texts. These tools make it easier to organize and structure the information in Sanskrit writings.
In addition, the researchers have developed a variety of web-based interfaces, software libraries, and other tools that make it simpler for people to access and work with Sanskrit language resources. All of these contributions are aimed at making it easier to preserve, understand, and utilize the wealth of information contained in Sanskrit texts.
Technical Explanation
The paper proposes a framework for the automated construction of knowledge graphs from Sanskrit texts. This involves developing techniques to extract entities, relationships, and other relevant information from the unstructured text and represent it in a structured knowledge graph format.
The researchers also introduce annotation tools for both ontology-driven and general-purpose tasks related to Sanskrit language processing. These tools allow human experts to collaborate with computational systems to accurately analyze and annotate Sanskrit texts.
Furthermore, the paper presents a diverse collection of web interfaces, software libraries, and other tools that facilitate access to and utilization of Sanskrit language resources. This includes question answering systems and benchmarking datasets that can help advance research in areas like automatic speech recognition for Hindi.
Critical Analysis
The paper presents a comprehensive set of contributions to the field of computational Sanskrit, addressing key challenges in knowledge representation, text analysis, and language processing. The proposed frameworks and tools show promising results and potential for further development and application.
However, the paper does not delve deeply into the specific limitations or challenges encountered in the development and deployment of these systems. It would be valuable to understand the technical hurdles, data quality issues, or scalability concerns that the researchers faced, and how they plan to address them in future work.
Additionally, the paper could benefit from a more critical examination of the broader implications and potential societal impact of this research. Questions around the accessibility, fairness, and ethical considerations of such language technologies could be explored to provide a more well-rounded evaluation of the work.
Conclusion
The research presented in this paper represents significant advancements in the field of computational Sanskrit. By developing innovative frameworks for knowledge graph construction, annotation tools, and a diverse set of language processing resources, the researchers have made important contributions to enhancing the accessibility, accuracy, and utilization of Sanskrit texts.
These developments not only benefit scholars and researchers working with Sanskrit but also have the potential to contribute to the preservation, understanding, and appreciation of this rich linguistic and cultural heritage. As the researchers continue to refine and expand their work, it will be interesting to see how these tools and techniques can be further applied to unlock the wealth of knowledge contained in Sanskrit literature.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Sanskrit Knowledge-based Systems: Annotation and Computational Tools
Hrishikesh Terdalkar
We address the challenges and opportunities in the development of knowledge systems for Sanskrit, with a focus on question answering. By proposing a framework for the automated construction of knowledge graphs, introducing annotation tools for ontology-driven and general-purpose tasks, and offering a diverse collection of web-interfaces, tools, and software libraries, we have made significant contributions to the field of computational Sanskrit. These contributions not only enhance the accessibility and accuracy of Sanskrit text analysis but also pave the way for further advancements in knowledge representation and language processing. Ultimately, this research contributes to the preservation, understanding, and utilization of the rich linguistic information embodied in Sanskrit texts.
Read more6/27/2024
💬
0
Tamil Language Computing: the Present and the Future
Kengatharaiyer Sarveswaran
This paper delves into the text processing aspects of Language Computing, which enables computers to understand, interpret, and generate human language. Focusing on tasks such as speech recognition, machine translation, sentiment analysis, text summarization, and language modelling, language computing integrates disciplines including linguistics, computer science, and cognitive psychology to create meaningful human-computer interactions. Recent advancements in deep learning have made computers more accessible and capable of independent learning and adaptation. In examining the landscape of language computing, the paper emphasises foundational work like encoding, where Tamil transitioned from ASCII to Unicode, enhancing digital communication. It discusses the development of computational resources, including raw data, dictionaries, glossaries, annotated data, and computational grammars, necessary for effective language processing. The challenges of linguistic annotation, the creation of treebanks, and the training of large language models are also covered, emphasising the need for high-quality, annotated data and advanced language models. The paper underscores the importance of building practical applications for languages like Tamil to address everyday communication needs, highlighting gaps in current technology. It calls for increased research collaboration, digitization of historical texts, and fostering digital usage to ensure the comprehensive development of Tamil language processing, ultimately enhancing global communication and access to digital services.
Read more8/13/2024
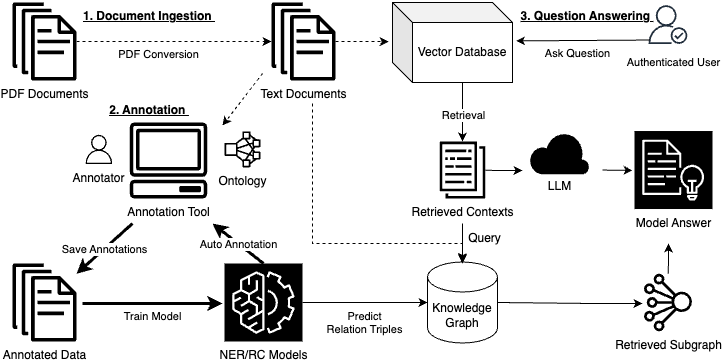
0
KnowledgeHub: An end-to-end Tool for Assisted Scientific Discovery
Shinnosuke Tanaka, James Barry, Vishnudev Kuruvanthodi, Movina Moses, Maxwell J. Giammona, Nathan Herr, Mohab Elkaref, Geeth De Mel
This paper describes the KnowledgeHub tool, a scientific literature Information Extraction (IE) and Question Answering (QA) pipeline. This is achieved by supporting the ingestion of PDF documents that are converted to text and structured representations. An ontology can then be constructed where a user defines the types of entities and relationships they want to capture. A browser-based annotation tool enables annotating the contents of the PDF documents according to the ontology. Named Entity Recognition (NER) and Relation Classification (RC) models can be trained on the resulting annotations and can be used to annotate the unannotated portion of the documents. A knowledge graph is constructed from these entity and relation triples which can be queried to obtain insights from the data. Furthermore, we integrate a suite of Large Language Models (LLMs) that can be used for QA and summarisation that is grounded in the included documents via a retrieval component. KnowledgeHub is a unique tool that supports annotation, IE and QA, which gives the user full insight into the knowledge discovery pipeline.
Read more6/18/2024
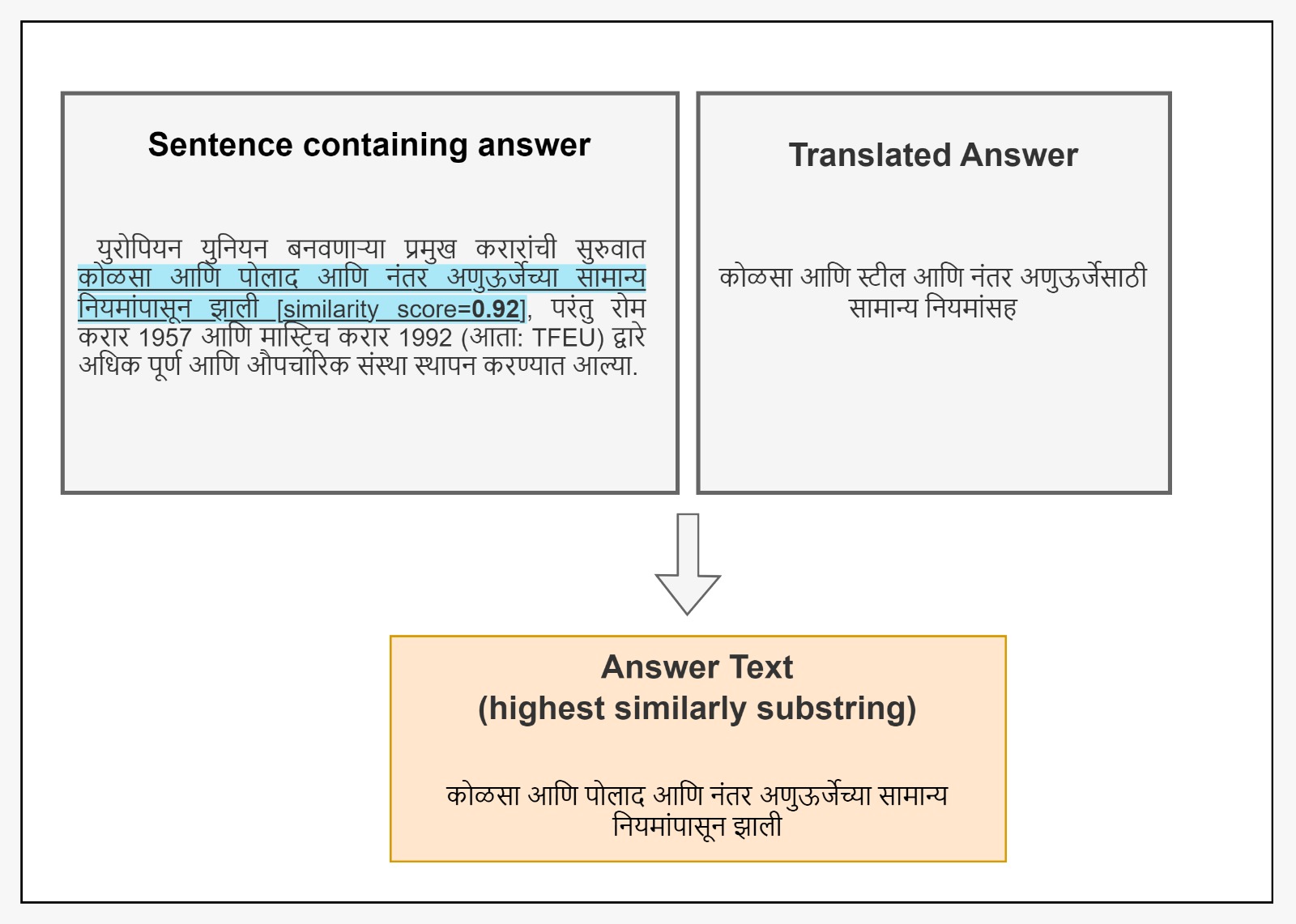
0
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
Read more4/23/2024