Scaling A Simple Approach to Zero-Shot Speech Recognition

0

Sign in to get full access
Overview
- Scaling A Simple Approach to Zero-Shot Speech Recognition
- Presents a simple yet effective framework for zero-shot speech recognition
- Demonstrates the capability to recognize speech in 10,000+ languages without any language-specific training data
Plain English Explanation
The paper introduces a novel approach to zero-shot speech recognition, which enables speech recognition in thousands of languages without requiring any training data for those languages. This is a significant advancement, as traditional speech recognition systems are typically limited to a small set of languages they were explicitly trained on.
The key idea is to leverage a large language model that has been trained on a vast amount of text data in many languages. This language model can then be used to map the acoustic features of speech to the corresponding text in any language, without the need for language-specific training data.
The authors demonstrate that their approach can recognize speech in over 10,000 languages, significantly expanding the reach and accessibility of speech recognition technology. This has important implications for universal speech recognition, making it possible to communicate in a wide variety of languages without the need for specialized language models.
Technical Explanation
The paper presents a simple yet effective framework for zero-shot speech recognition. The core idea is to leverage a pre-trained language model, such as a large transformer-based model, to map acoustic features of speech directly to text in any language.
The system consists of two main components:
- Acoustic Encoder: A convolutional neural network that takes raw audio as input and produces a sequence of acoustic features.
- Language Model Decoder: A transformer-based language model that takes the acoustic features and generates the corresponding text, without any language-specific training.
The authors show that this simple approach can achieve impressive performance on zero-shot speech recognition tasks, outperforming more complex models that require language-specific training data. They demonstrate the scalability of their method by evaluating it on a dataset of over 10,000 languages, showcasing its ability to handle a vast linguistic diversity.
Critical Analysis
The paper presents a compelling approach to zero-shot speech recognition, which addresses a significant limitation of traditional speech recognition systems. By leveraging a powerful language model, the authors are able to bypass the need for language-specific training data, making speech recognition more accessible and inclusive.
However, the paper does not discuss some potential limitations of the approach. For example, it is unclear how the system would perform on low-resource languages with limited text data available for pre-training the language model. Additionally, the paper does not explore the impact of language model bias or the ability to handle regional dialects and accents.
Further research could investigate ways to fine-tune or adapt the language model to specific domains or user groups, improving the overall robustness and accuracy of the zero-shot speech recognition system. Exploring techniques to mitigate language model biases would also be an important area of study.
Conclusion
The paper presents a novel and scalable approach to zero-shot speech recognition, which has the potential to significantly expand the reach and accessibility of speech recognition technology. By leveraging a powerful language model, the authors demonstrate the ability to recognize speech in over 10,000 languages without any language-specific training data.
This research represents an important step towards universal speech recognition, which could have far-reaching implications for communication, education, and accessibility. The simplicity and scalability of the approach make it a promising foundation for further advancements in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling A Simple Approach to Zero-Shot Speech Recognition
Jinming Zhao, Vineel Pratap, Michael Auli
Despite rapid progress in increasing the language coverage of automatic speech recognition, the field is still far from covering all languages with a known writing script. Recent work showed promising results with a zero-shot approach requiring only a small amount of text data, however, accuracy heavily depends on the quality of the used phonemizer which is often weak for unseen languages. In this paper, we present MMS Zero-shot a conceptually simpler approach based on romanization and an acoustic model trained on data in 1,078 different languages or three orders of magnitude more than prior art. MMS Zero-shot reduces the average character error rate by a relative 46% over 100 unseen languages compared to the best previous work. Moreover, the error rate of our approach is only 2.5x higher compared to in-domain supervised baselines, while our approach uses no labeled data for the evaluation languages at all.
Read more7/26/2024
0
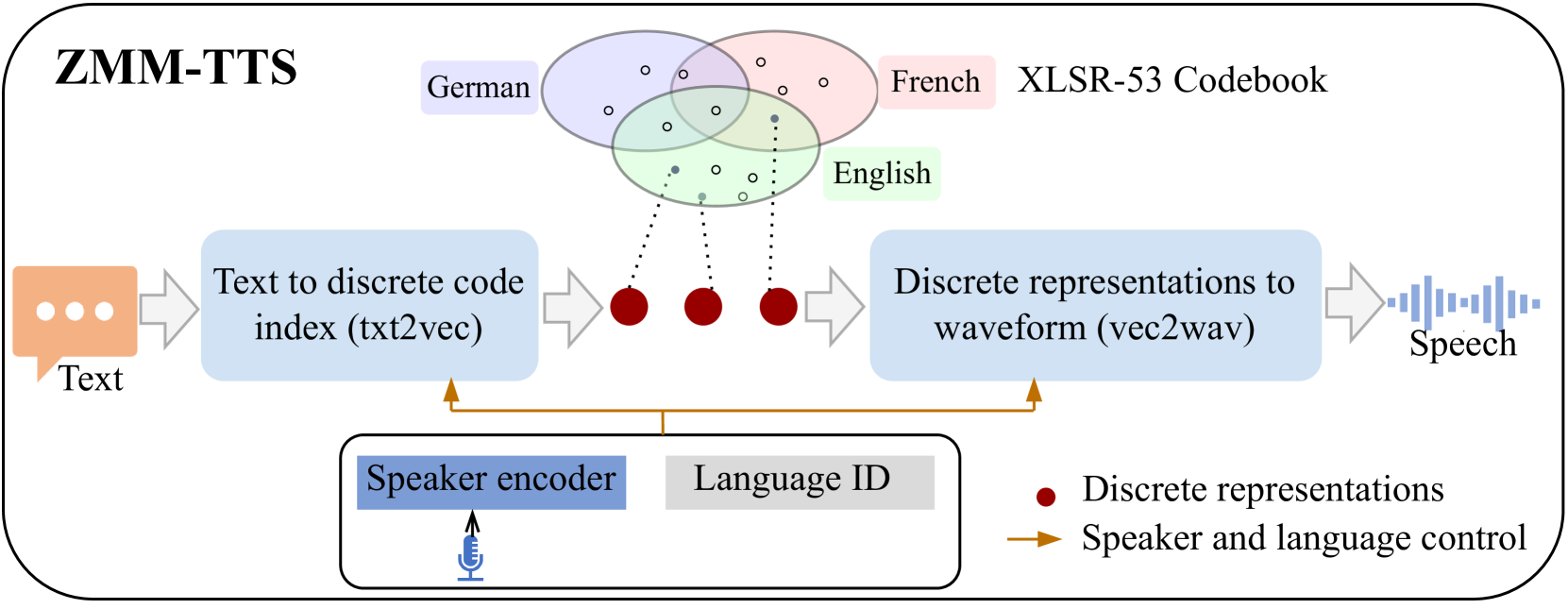
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Cheng Gong, Xin Wang, Erica Cooper, Dan Wells, Longbiao Wang, Jianwu Dang, Korin Richmond, Junichi Yamagishi
Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. TTS systems are typically built using a single speaker's voices, but there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper combines text-based and speech-based self-supervised learning models for multilingual speech synthesis. Our proposed model has zero-shot generalization ability not only for unseen speakers but also for unseen languages. We have conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetically low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
Read more8/28/2024

0
Zero Shot Text to Speech Augmentation for Automatic Speech Recognition on Low-Resource Accented Speech Corpora
Francesco Nespoli, Daniel Barreda, Patrick A. Naylor
In recent years, automatic speech recognition (ASR) models greatly improved transcription performance both in clean, low noise, acoustic conditions and in reverberant environments. However, all these systems rely on the availability of hundreds of hours of labelled training data in specific acoustic conditions. When such a training dataset is not available, the performance of the system is heavily impacted. For example, this happens when a specific acoustic environment or a particular population of speakers is under-represented in the training dataset. Specifically, in this paper we investigate the effect of accented speech data on an off-the-shelf ASR system. Furthermore, we suggest a strategy based on zero-shot text-to-speech to augment the accented speech corpora. We show that this augmentation method is able to mitigate the loss in performance of the ASR system on accented data up to 5% word error rate reduction (WERR). In conclusion, we demonstrate that by incorporating a modest fraction of real with synthetically generated data, the ASR system exhibits superior performance compared to a model trained exclusively on authentic accented speech with up to 14% WERR.
Read more9/18/2024

0
A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
Thomas Stegmuller, Tim Lebailly, Nikola Dukic, Behzad Bozorgtabar, Tinne Tuytelaars, Jean-Philippe Thiran
Zero-shot classification capabilities naturally arise in models trained within a vision-language contrastive framework. Despite their classification prowess, these models struggle in dense tasks like zero-shot open-vocabulary segmentation. This deficiency is often attributed to the absence of localization cues in captions and the intertwined nature of the learning process, which encompasses both image representation learning and cross-modality alignment. To tackle these issues, we propose SimZSS, a Simple framework for open-vocabulary Zero-Shot Segmentation. The method is founded on two key principles: i) leveraging frozen vision-only models that exhibit spatial awareness while exclusively aligning the text encoder and ii) exploiting the discrete nature of text and linguistic knowledge to pinpoint local concepts within captions. By capitalizing on the quality of the visual representations, our method requires only image-caption pairs datasets and adapts to both small curated and large-scale noisy datasets. When trained on COCO Captions across 8 GPUs, SimZSS achieves state-of-the-art results on 7 out of 8 benchmark datasets in less than 15 minutes.
Read more7/2/2024