SepVAE: a contrastive VAE to separate pathological patterns from healthy ones
2307.06206
0
0

Abstract
Contrastive Analysis VAE (CA-VAEs) is a family of Variational auto-encoders (VAEs) that aims at separating the common factors of variation between a background dataset (BG) (i.e., healthy subjects) and a target dataset (TG) (i.e., patients) from the ones that only exist in the target dataset. To do so, these methods separate the latent space into a set of salient features (i.e., proper to the target dataset) and a set of common features (i.e., exist in both datasets). Currently, all models fail to prevent the sharing of information between latent spaces effectively and to capture all salient factors of variation. To this end, we introduce two crucial regularization losses: a disentangling term between common and salient representations and a classification term between background and target samples in the salient space. We show a better performance than previous CA-VAEs methods on three medical applications and a natural images dataset (CelebA). Code and datasets are available on GitHub https://github.com/neurospin-projects/2023_rlouiset_sepvae.
Create account to get full access
Overview
- This paper introduces SepVAE, a novel contrastive Variational Autoencoder (VAE) model designed to separate pathological patterns from healthy ones in biomedical images.
- The goal is to improve the interpretability and performance of VAE models in the context of neuropsychiatric and biomedical imaging applications.
- SepVAE leverages contrastive learning to disentangle the latent representations of pathological and healthy patterns, allowing for better discrimination and analysis.
Plain English Explanation
The paper presents a new machine learning model called SepVAE that is designed to help separate unhealthy or abnormal patterns from healthy ones in medical images. This could be useful for applications like detecting signs of illness or disease in brain scans or other biomedical data.
The key idea is to use a technique called "contrastive learning" to train the model to better distinguish between the latent (hidden) representations of healthy and unhealthy patterns in the data. This allows the model to more accurately identify and analyze the differences between normal and abnormal features, which could lead to improved diagnostic tools and a better understanding of various medical conditions.
The authors demonstrate the effectiveness of SepVAE on several neuropsychiatric and biomedical imaging datasets, showing that it outperforms standard VAE models in terms of interpretability and performance. This suggests that the contrastive approach used in SepVAE could be a valuable addition to the toolkit of machine learning researchers and medical professionals working to leverage advanced techniques like Variational Autoencoders and Convolutional Neural Networks for biomedical applications.
Technical Explanation
The paper introduces SepVAE, a novel contrastive Variational Autoencoder (VAE) model designed to improve the separation of pathological and healthy patterns in biomedical imaging data. VAEs are a type of deep learning model that can learn efficient low-dimensional representations of complex data, such as medical images, in an unsupervised manner.
The key innovation in SepVAE is the addition of a contrastive loss term to the standard VAE objective. This contrastive loss encourages the model to learn latent representations that maximize the distance between pathological and healthy patterns, while minimizing the distance between similar patterns within each class. This disentanglement of the latent space is hypothesized to enhance the interpretability and performance of the model in downstream tasks, such as disease classification or anomaly detection.
The authors evaluate SepVAE on several neuropsychiatric and biomedical imaging datasets, including brain MRI scans and retinal fundus images. The results demonstrate that SepVAE outperforms standard VAE models in terms of classification accuracy, anomaly detection, and latent space interpretability. Furthermore, the authors provide visualizations and analyses to show how SepVAE's latent representations better capture the underlying pathological and healthy patterns in the data.
Critical Analysis
The authors present a well-designed and insightful study that addresses an important challenge in the application of machine learning to biomedical imaging: the need for models that can effectively separate pathological patterns from healthy ones. The contrastive learning approach used in SepVAE is a promising direction, as it aligns with the broader trend of leveraging contrastive objectives to enhance the interpretability and performance of deep learning models.
However, the paper does not fully address the potential limitations and caveats of the SepVAE approach. For instance, the authors do not discuss the sensitivity of the model to variations in the training data or the generalizability of the results to other biomedical domains. Additionally, the computational complexity and training requirements of SepVAE compared to standard VAE models are not thoroughly examined, which could be an important consideration for real-world deployment.
Furthermore, the paper would be strengthened by a more comprehensive discussion of the potential ethical and societal implications of such a model. As with any advanced machine learning system applied to healthcare, there are important considerations around bias, fairness, and the responsible use of the technology that warrant further exploration.
Conclusion
The SepVAE model presented in this paper represents a significant advancement in the field of biomedical machine learning, with the potential to improve the interpretability and performance of VAE-based models in neuropsychiatric and other medical imaging applications. By leveraging contrastive learning to disentangle pathological and healthy patterns in the latent space, SepVAE offers a promising approach to enhancing the capabilities of generative models for biomedical analysis and decision support.
As the field of medical AI continues to evolve, innovations like SepVAE will be crucial in ensuring that these powerful technologies are developed and deployed in a responsible and impactful manner, ultimately benefiting patients and advancing our understanding of complex medical conditions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
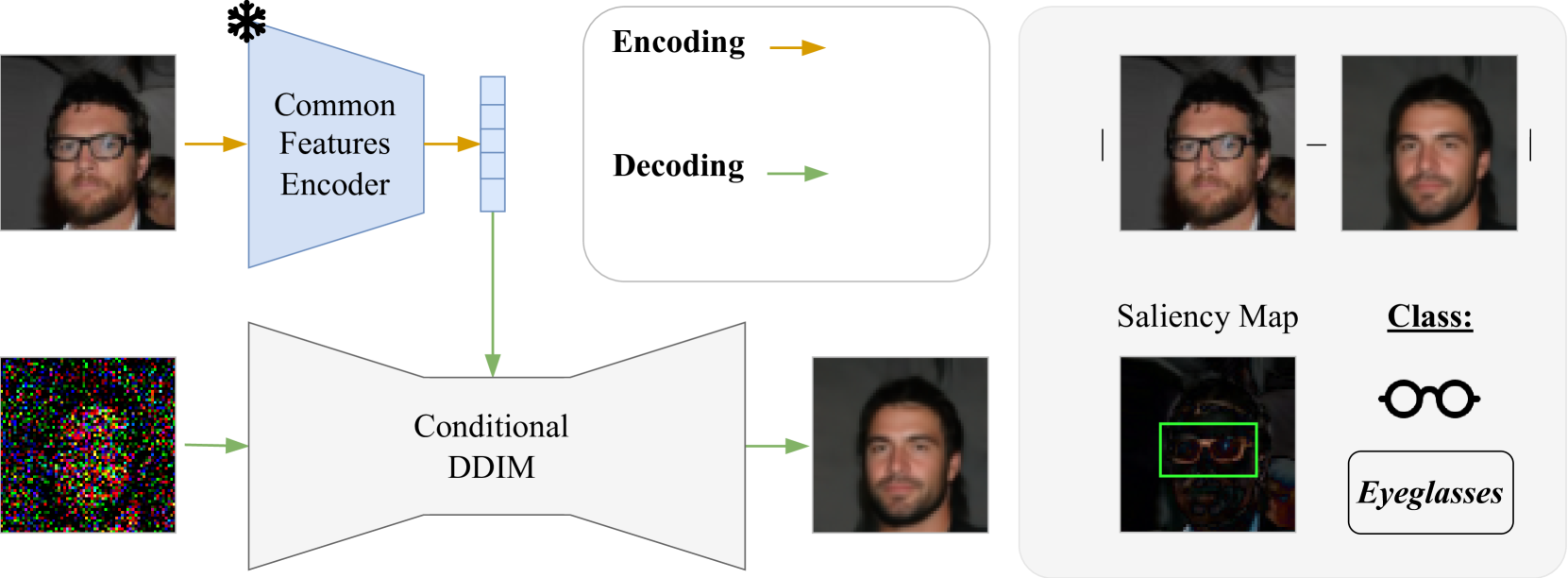
Unsupervised Contrastive Analysis for Salient Pattern Detection using Conditional Diffusion Models
Cristiano Patr'icio, Carlo Alberto Barbano, Attilio Fiandrotti, Riccardo Renzulli, Marco Grangetto, Luis F. Teixeira, Jo~ao C. Neves
0
0
Contrastive Analysis (CA) regards the problem of identifying patterns in images that allow distinguishing between a background (BG) dataset (i.e. healthy subjects) and a target (TG) dataset (i.e. unhealthy subjects). Recent works on this topic rely on variational autoencoders (VAE) or contrastive learning strategies to learn the patterns that separate TG samples from BG samples in a supervised manner. However, the dependency on target (unhealthy) samples can be challenging in medical scenarios due to their limited availability. Also, the blurred reconstructions of VAEs lack utility and interpretability. In this work, we redefine the CA task by employing a self-supervised contrastive encoder to learn a latent representation encoding only common patterns from input images, using samples exclusively from the BG dataset during training, and approximating the distribution of the target patterns by leveraging data augmentation techniques. Subsequently, we exploit state-of-the-art generative methods, i.e. diffusion models, conditioned on the learned latent representation to produce a realistic (healthy) version of the input image encoding solely the common patterns. Thorough validation on a facial image dataset and experiments across three brain MRI datasets demonstrate that conditioning the generative process of state-of-the-art generative methods with the latent representation from our self-supervised contrastive encoder yields improvements in the generated image quality and in the accuracy of image classification. The code is available at https://github.com/CristianoPatricio/unsupervised-contrastive-cond-diff.
6/5/2024
How to train your VAE
Mariano Rivera
0
0
Variational Autoencoders (VAEs) have become a cornerstone in generative modeling and representation learning within machine learning. This paper explores a nuanced aspect of VAEs, focusing on interpreting the Kullback-Leibler (KL) Divergence, a critical component within the Evidence Lower Bound (ELBO) that governs the trade-off between reconstruction accuracy and regularization. Meanwhile, the KL Divergence enforces alignment between latent variable distributions and a prior imposing a structure on the overall latent space but leaves individual variable distributions unconstrained. The proposed method redefines the ELBO with a mixture of Gaussians for the posterior probability, introduces a regularization term to prevent variance collapse, and employs a PatchGAN discriminator to enhance texture realism. Implementation details involve ResNetV2 architectures for both the Encoder and Decoder. The experiments demonstrate the ability to generate realistic faces, offering a promising solution for enhancing VAE-based generative models.
6/26/2024
🔎
Poisson Variational Autoencoder
Hadi Vafaii, Dekel Galor, Jacob L. Yates
0
0
Variational autoencoders (VAE) employ Bayesian inference to interpret sensory inputs, mirroring processes that occur in primate vision across both ventral (Higgins et al., 2021) and dorsal (Vafaii et al., 2023) pathways. Despite their success, traditional VAEs rely on continuous latent variables, which deviates sharply from the discrete nature of biological neurons. Here, we developed the Poisson VAE (P-VAE), a novel architecture that combines principles of predictive coding with a VAE that encodes inputs into discrete spike counts. Combining Poisson-distributed latent variables with predictive coding introduces a metabolic cost term in the model loss function, suggesting a relationship with sparse coding which we verify empirically. Additionally, we analyze the geometry of learned representations, contrasting the P-VAE to alternative VAE models. We find that the P-VAEencodes its inputs in relatively higher dimensions, facilitating linear separability of categories in a downstream classification task with a much better (5x) sample efficiency. Our work provides an interpretable computational framework to study brain-like sensory processing and paves the way for a deeper understanding of perception as an inferential process.
5/24/2024

CV-VAE: A Compatible Video VAE for Latent Generative Video Models
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, Ying Shan
0
0
Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
5/31/2024