SIDEs: Separating Idealization from Deceptive Explanations in xAI
2404.16534
0
0
🎯
Abstract
Explainable AI (xAI) methods are important for establishing trust in using black-box models. However, recent criticism has mounted against current xAI methods that they disagree, are necessarily false, and can be manipulated, which has started to undermine the deployment of black-box models. Rudin (2019) goes so far as to say that we should stop using black-box models altogether in high-stakes cases because xAI explanations must be wrong. However, strict fidelity to the truth is historically not a desideratum in science. Idealizations -- the intentional distortions introduced to scientific theories and models -- are commonplace in the natural sciences and are seen as a successful scientific tool. Thus, it is not falsehood qua falsehood that is the issue. In this paper, I outline the need for xAI research to engage in idealization evaluation. Drawing on the use of idealizations in the natural sciences and philosophy of science, I introduce a novel framework for evaluating whether xAI methods engage in successful idealizations or deceptive explanations (SIDEs). SIDEs evaluates whether the limitations of xAI methods, and the distortions that they introduce, can be part of a successful idealization or are indeed deceptive distortions as critics suggest. I discuss the role that existing research can play in idealization evaluation and where innovation is necessary. Through a qualitative analysis we find that leading feature importance methods and counterfactual explanations are subject to idealization failure and suggest remedies for ameliorating idealization failure.
Create account to get full access
Overview
- Explainable AI (xAI) methods are crucial for building trust in black-box models, but recent criticism has called into question their reliability and validity
- The paper argues that xAI research should focus on evaluating whether the explanations provided by these methods are successful "idealizations" or deceptive distortions
- The paper introduces a novel framework called "SIDEs" (Successful Idealization or Deceptive Explanations) to assess the limitations and distortions introduced by xAI methods
Plain English Explanation
Black-box models, such as deep neural networks, are powerful but can be difficult to understand. Explainable AI (xAI) methods aim to provide explanations for the decisions made by these models, which is important for building trust and ensuring they are used responsibly.
However, some researchers have criticized current xAI methods, arguing that the explanations they provide are necessarily false and can be manipulated. This criticism has started to undermine the deployment of black-box models in high-stakes applications.
The paper argues that this criticism is misguided. In science, it is common to use "idealizations" - intentional distortions introduced to simplify theories and models. These idealizations are not necessarily false, but rather a successful scientific tool.
The paper proposes a new framework called "SIDEs" (Successful Idealization or Deceptive Explanations) to evaluate whether the limitations and distortions introduced by xAI methods are part of a successful idealization or are indeed deceptive, as the critics suggest. By drawing on examples from the natural sciences and philosophy of science, the paper aims to provide a more nuanced understanding of the role of idealizations in xAI.
Through a qualitative analysis, the paper finds that some leading xAI methods, such as feature importance and counterfactual explanations, are subject to "idealization failure" and proposes ways to address this issue.
Technical Explanation
The paper starts by acknowledging the importance of explainable AI (xAI) methods for building trust in the use of black-box models. However, it also notes that recent criticism has called into question the reliability and validity of current xAI methods.
The paper then introduces the concept of "idealization" - the intentional distortions introduced to simplify scientific theories and models. The author argues that these idealizations are commonplace in the natural sciences and are often seen as a successful scientific tool, rather than a failure.
Building on this, the paper proposes a novel framework called "SIDEs" (Successful Idealization or Deceptive Explanations) to evaluate whether the limitations and distortions introduced by xAI methods are part of a successful idealization or are indeed deceptive, as the critics suggest.
The paper then provides a qualitative analysis of leading xAI methods, such as feature importance and counterfactual explanations, to assess whether they are subject to "idealization failure." The paper also suggests remedies for ameliorating this issue, such as adapting counterfactual explanations to specific user needs.
Critical Analysis
The paper makes a compelling case for the need to evaluate xAI methods through the lens of idealization, rather than simply dismissing them as necessarily false or deceptive. The author's use of examples from the natural sciences and philosophy of science provides a solid foundation for this argument.
However, the paper does not address the potential risks and harms that can arise from the use of black-box models, even with the application of xAI methods. While the author argues that idealization is a common and successful scientific tool, the stakes in high-stakes applications of AI, such as healthcare or criminal justice, may be much higher than in traditional scientific domains.
Additionally, the paper's qualitative analysis of specific xAI methods is limited, and more empirical research may be needed to fully validate the SIDEs framework and its ability to distinguish successful idealizations from deceptive explanations.
Overall, the paper provides a thought-provoking perspective on the role of idealization in xAI and highlights the need for more nuanced evaluation of these methods. Readers are encouraged to think critically about the research and its implications for the responsible deployment of black-box models in high-stakes domains.
Conclusion
This paper argues that the recent criticism of explainable AI (xAI) methods as necessarily false or deceptive is misguided. By drawing on the concept of "idealization" from the natural sciences and philosophy of science, the author introduces a novel framework called "SIDEs" to evaluate whether the limitations and distortions introduced by xAI methods are part of a successful idealization or are indeed deceptive.
The paper's qualitative analysis suggests that leading xAI methods, such as feature importance and counterfactual explanations, are subject to "idealization failure." The author proposes remedies to address this issue, highlighting the need for more nuanced evaluation of xAI methods and their role in building trust and responsible deployment of black-box models.
This research has important implications for the future of AI, as the ability to explain and justify the decisions of these powerful models will be crucial for their widespread adoption in high-stakes domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Position: Explain to Question not to Justify
Przemyslaw Biecek, Wojciech Samek
0
0
Explainable Artificial Intelligence (XAI) is a young but very promising field of research. Unfortunately, the progress in this field is currently slowed down by divergent and incompatible goals. We separate various threads tangled within the area of XAI into two complementary cultures of human/value-oriented explanations (BLUE XAI) and model/validation-oriented explanations (RED XAI). This position paper argues that the area of RED XAI is currently under-explored, i.e., more methods for explainability are desperately needed to question models (e.g., extract knowledge from well-performing models as well as spotting and fixing bugs in faulty models), and the area of RED XAI hides great opportunities and potential for important research necessary to ensure the safety of AI systems. We conclude this paper by presenting promising challenges in this area.
7/1/2024
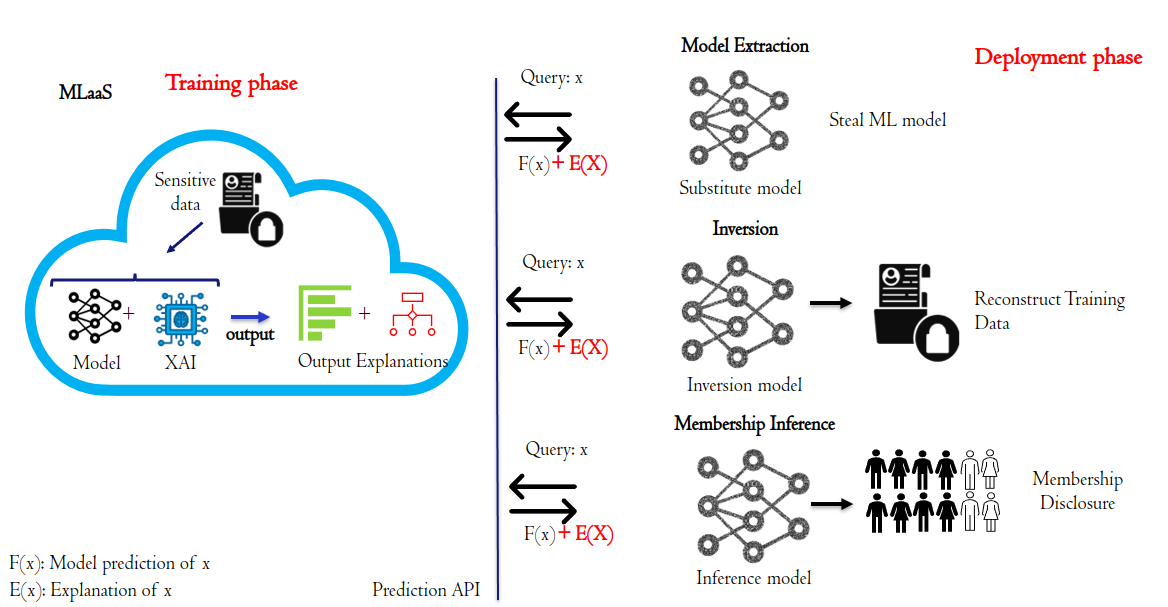
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
0
0
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
6/26/2024
🖼️
Relevant Irrelevance: Generating Alterfactual Explanations for Image Classifiers
Silvan Mertes, Tobias Huber, Christina Karle, Katharina Weitz, Ruben Schlagowski, Cristina Conati, Elisabeth Andr'e
0
0
In this paper, we demonstrate the feasibility of alterfactual explanations for black box image classifiers. Traditional explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, most common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. However, to fully understand a decision, not only knowledge about relevant features is needed, but the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. To this end, a novel approach for explaining AI systems called alterfactual explanations was recently proposed on a conceptual level. It is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which input data characteristics can change arbitrarily without influencing the AI's decision. In this paper, we show for the first time that it is possible to apply this idea to black box models based on neural networks. To this end, we present a GAN-based approach to generate these alterfactual explanations for binary image classifiers. Further, we present a user study that gives interesting insights on how alterfactual explanations can complement counterfactual explanations.
5/10/2024
🔮
Counterfactual Explanations of Black-box Machine Learning Models using Causal Discovery with Applications to Credit Rating
Daisuke Takahashi, Shohei Shimizu, Takuma Tanaka
0
0
Explainable artificial intelligence (XAI) has helped elucidate the internal mechanisms of machine learning algorithms, bolstering their reliability by demonstrating the basis of their predictions. Several XAI models consider causal relationships to explain models by examining the input-output relationships of prediction models and the dependencies between features. The majority of these models have been based their explanations on counterfactual probabilities, assuming that the causal graph is known. However, this assumption complicates the application of such models to real data, given that the causal relationships between features are unknown in most cases. Thus, this study proposed a novel XAI framework that relaxed the constraint that the causal graph is known. This framework leveraged counterfactual probabilities and additional prior information on causal structure, facilitating the integration of a causal graph estimated through causal discovery methods and a black-box classification model. Furthermore, explanatory scores were estimated based on counterfactual probabilities. Numerical experiments conducted employing artificial data confirmed the possibility of estimating the explanatory score more accurately than in the absence of a causal graph. Finally, as an application to real data, we constructed a classification model of credit ratings assigned by Shiga Bank, Shiga prefecture, Japan. We demonstrated the effectiveness of the proposed method in cases where the causal graph is unknown.
4/30/2024