Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs

0

Sign in to get full access
Overview
- This paper presents a novel approach to leveraging slim "proxy" models to decide when and what to retrieve for large language models (LLMs).
- The researchers develop a slim proxy model that can efficiently predict when the LLM will make a mistake and what information it needs to correct that mistake.
- By selectively retrieving relevant information based on the proxy model's predictions, the system can improve the LLM's performance while reducing the computational cost.
Plain English Explanation
The paper introduces a way to make large language models (LLMs) more efficient and effective. LLMs are powerful AI systems that can understand and generate human-like text, but they can also make mistakes or give inaccurate responses.
The researchers created a smaller "proxy" model that can quickly predict when the LLM is likely to make a mistake and what kind of information it needs to fix that mistake. This proxy model is much smaller and faster than the full LLM, so it can be used to selectively retrieve only the most relevant information to help the LLM.
By using this proxy model to decide when and what to retrieve, the system can improve the LLM's performance without having to run the full LLM on every input. This makes the overall system more cost-efficient and quality-aware, allowing the LLM to focus its resources on the areas where it needs the most help.
The key insight is that a small, specialized model can provide big insights about when and how to best utilize a larger, more powerful model like an LLM. This allows the system to teach the LLM when to rely on its own knowledge versus when to retrieve additional information to improve its answers.
Technical Explanation
The paper introduces a novel approach called "Retrieval-Augmented Generation with Proxy Models" (RAG-PM) that uses a small, efficient "proxy" model to decide when and what to retrieve for a large language model (LLM).
The key components of the system are:
- Proxy Model: A smaller, specialized model that is trained to predict when the LLM will make a mistake and what information it needs to correct that mistake.
- Retrieval Module: A module that can quickly retrieve relevant information from a knowledge base based on the proxy model's predictions.
- LLM: The large, powerful language model that generates the final output, with the help of the retrieved information.
The proxy model is trained on a dataset of LLM inputs and outputs, along with annotations of when the LLM made mistakes and what information would have been helpful. The proxy model learns to map LLM inputs to predictions about whether the LLM will make a mistake and what to retrieve to fix that mistake.
During inference, the proxy model first processes the input and makes its predictions. The retrieval module then fetches the relevant information, and the LLM uses that information to generate the final output. By selectively retrieving only the most helpful information, the system can improve the LLM's performance while reducing the overall computational cost.
The researchers evaluate the RAG-PM system on several language understanding and generation tasks, and show that it outperforms both the standalone LLM and other retrieval-augmented approaches in terms of accuracy, efficiency, and cost-effectiveness.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the RAG-PM system, testing it on a variety of tasks and comparing it to relevant baselines. The results demonstrate the effectiveness of the proxy model approach in improving LLM performance while reducing computational costs.
However, the paper does not extensively discuss the limitations of the system or potential areas for further research. For example, it would be interesting to explore how the proxy model's performance and the overall system's efficiency scales with the size and complexity of the LLM and the knowledge base.
Additionally, the paper does not address the potential challenges of training the proxy model, such as the difficulty of accurately annotating LLM mistakes and the appropriate information to retrieve. Further research could investigate more automated or scalable methods for proxy model training.
Another area for further exploration is the generalizability of the RAG-PM approach. The paper focuses on a specific set of tasks and datasets, and it would be valuable to understand how well the system would perform on a broader range of applications and real-world scenarios.
Overall, the paper presents a compelling and well-executed approach to improving the efficiency and effectiveness of large language models, and the ideas and insights it provides can inform future research in this important area of AI development.
Conclusion
The "Small Models, Big Insights" paper introduces a novel approach called Retrieval-Augmented Generation with Proxy Models (RAG-PM) that leverages a small, efficient proxy model to selectively retrieve relevant information for a large language model (LLM). By using the proxy model to predict when the LLM will make mistakes and what it needs to correct those mistakes, the system can improve the LLM's performance while reducing the overall computational cost.
This work demonstrates the value of combining small, specialized models with large, powerful models to create more cost-efficient and quality-aware AI systems. The insights and techniques presented in this paper can inform future research on how to effectively leverage large language models and teach them to utilize external knowledge in a more targeted and efficient manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, Ji-Rong Wen
The integration of large language models (LLMs) and search engines represents a significant evolution in knowledge acquisition methodologies. However, determining the knowledge that an LLM already possesses and the knowledge that requires the help of a search engine remains an unresolved issue. Most existing methods solve this problem through the results of preliminary answers or reasoning done by the LLM itself, but this incurs excessively high computational costs. This paper introduces a novel collaborative approach, namely SlimPLM, that detects missing knowledge in LLMs with a slim proxy model, to enhance the LLM's knowledge acquisition process. We employ a proxy model which has far fewer parameters, and take its answers as heuristic answers. Heuristic answers are then utilized to predict the knowledge required to answer the user question, as well as the known and unknown knowledge within the LLM. We only conduct retrieval for the missing knowledge in questions that the LLM does not know. Extensive experimental results on five datasets with two LLMs demonstrate a notable improvement in the end-to-end performance of LLMs in question-answering tasks, achieving or surpassing current state-of-the-art models with lower LLM inference costs.
Read more5/31/2024
🛸
0
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Tiziano Labruna, Jon Ander Campos, Gorka Azkune
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, , when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
Read more5/8/2024
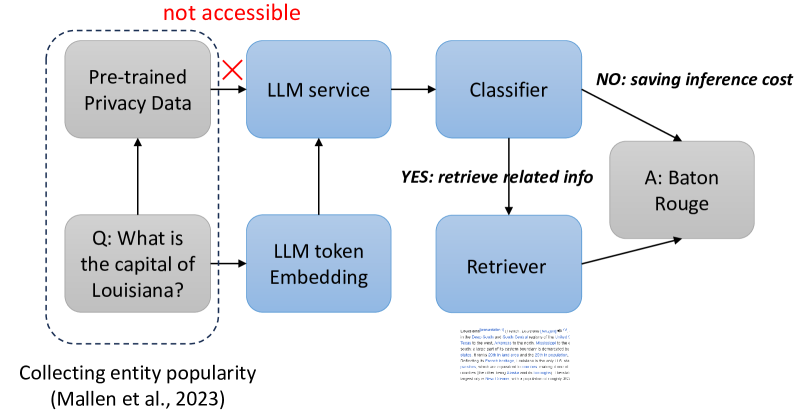
0
Learn When (not) to Trust Language Models: A Privacy-Centric Adaptive Model-Aware Approach
Chengkai Huang, Rui Wang, Kaige Xie, Tong Yu, Lina Yao
Retrieval-augmented large language models (LLMs) have been remarkably competent in various NLP tasks. Despite their great success, the knowledge provided by the retrieval process is not always useful for improving the model prediction, since in some samples LLMs may already be quite knowledgeable and thus be able to answer the question correctly without retrieval. Aiming to save the cost of retrieval, previous work has proposed to determine when to do/skip the retrieval in a data-aware manner by analyzing the LLMs' pretraining data. However, these data-aware methods pose privacy risks and memory limitations, especially when requiring access to sensitive or extensive pretraining data. Moreover, these methods offer limited adaptability under fine-tuning or continual learning settings. We hypothesize that token embeddings are able to capture the model's intrinsic knowledge, which offers a safer and more straightforward way to judge the need for retrieval without the privacy risks associated with accessing pre-training data. Moreover, it alleviates the need to retain all the data utilized during model pre-training, necessitating only the upkeep of the token embeddings. Extensive experiments and in-depth analyses demonstrate the superiority of our model-aware approach.
Read more4/5/2024
🏅
0
What is the Role of Small Models in the LLM Era: A Survey
Lihu Chen, Gael Varoquaux
Large Language Models (LLMs) have made significant progress in advancing artificial general intelligence (AGI), leading to the development of increasingly large models such as GPT-4 and LLaMA-405B. However, scaling up model sizes results in exponentially higher computational costs and energy consumption, making these models impractical for academic researchers and businesses with limited resources. At the same time, Small Models (SMs) are frequently used in practical settings, although their significance is currently underestimated. This raises important questions about the role of small models in the era of LLMs, a topic that has received limited attention in prior research. In this work, we systematically examine the relationship between LLMs and SMs from two key perspectives: Collaboration and Competition. We hope this survey provides valuable insights for practitioners, fostering a deeper understanding of the contribution of small models and promoting more efficient use of computational resources. The code is available at https://github.com/tigerchen52/role_of_small_models
Read more9/14/2024