SmartMem: Layout Transformation Elimination and Adaptation for Efficient DNN Execution on Mobile

0

Sign in to get full access
Overview
- This paper introduces "SmartMem", a novel layout transformation elimination and adaptation technique for efficient execution of deep neural networks (DNNs) on mobile devices.
- The paper addresses the challenge of memory layout transformation, which can significantly impact the performance and energy efficiency of DNN inference on mobile platforms.
- SmartMem aims to eliminate unnecessary layout transformations and adapt the memory layout to the specific hardware constraints, leading to improved inference speed and reduced energy consumption.
Plain English Explanation
Deep neural networks (DNNs) have become increasingly powerful and are used in a wide range of applications, from image recognition to natural language processing. However, running these complex models on mobile devices can be a challenge due to the limited computing resources and memory available.
One key issue is the memory layout transformation, which is the process of reorganizing the data in memory to match the specific requirements of the hardware. This transformation can be time-consuming and energy-intensive, which can significantly impact the performance of DNN inference on mobile devices.
The researchers behind this paper have developed a solution called "SmartMem" that aims to address this problem. SmartMem eliminates unnecessary layout transformations and adapts the memory layout to the specific hardware constraints of the mobile device. By doing this, SmartMem can improve the inference speed and reduce the energy consumption of DNN models running on mobile devices.
The core idea behind SmartMem is to analyze the DNN model and the target hardware platform to identify opportunities where layout transformations can be avoided or optimized. This allows the system to minimize the impact of these transformations and improve the overall efficiency of DNN execution on mobile devices.
Technical Explanation
The paper first provides background on the recent advances in DNN architectures, particularly the rise of Transformer-based models, and the challenges of deploying these models on resource-constrained mobile devices.
The authors then discuss the issue of memory layout transformation, which can significantly impact the performance and energy efficiency of DNN inference on mobile platforms. They highlight how existing techniques, such as Optimizing Deployment of Tiny Transformers on Low-Power MCUs and Vision Transformer Computation Resilience for Dynamic Inference, have focused on other optimization strategies but have not fully addressed the layout transformation problem.
The core contribution of this paper is the SmartMem approach, which consists of two key components:
-
Layout Transformation Elimination: SmartMem analyzes the DNN model and the target hardware to identify opportunities where layout transformations can be eliminated or simplified, reducing the computational overhead.
-
Layout Adaptation: SmartMem adaptively selects the memory layout that best fits the hardware constraints, further optimizing the performance and energy efficiency of DNN inference.
The paper describes the design and implementation of the SmartMem system, including the algorithms and heuristics used to make layout transformation decisions. The authors also present a comprehensive experimental evaluation, comparing SmartMem against state-of-the-art DNN optimization techniques on a range of mobile devices and DNN models.
Critical Analysis
The paper provides a thorough and well-designed solution to the memory layout transformation problem, which is a significant challenge for efficient DNN execution on mobile devices. The authors have addressed a crucial aspect of mobile DNN optimization that has not been fully explored in previous work.
One potential limitation of the research is that the evaluation is primarily focused on image classification tasks, and it would be interesting to see how well SmartMem performs on other types of DNN models, such as language models or object detection. Additionally, the paper does not provide a detailed analysis of the computational overhead and memory footprint of the SmartMem system itself, which could be an important consideration for resource-constrained mobile devices.
Overall, the SmartMem approach presents a promising solution to the memory layout transformation problem and could have significant implications for the deployment of advanced DNN models on a wide range of mobile and embedded devices.
Conclusion
The "SmartMem" paper introduces a novel technique for efficient DNN execution on mobile devices by addressing the challenge of memory layout transformation. The authors have developed a comprehensive solution that eliminates unnecessary layout transformations and adaptively selects the optimal memory layout for the target hardware, leading to significant improvements in inference speed and energy efficiency.
This research represents an important step forward in the field of mobile DNN optimization, addressing a crucial aspect that has not been fully explored in previous work. The comprehensive evaluation and the potential for broader applicability to different DNN models and hardware platforms make this a valuable contribution to the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SmartMem: Layout Transformation Elimination and Adaptation for Efficient DNN Execution on Mobile
Wei Niu, Md Musfiqur Rahman Sanim, Zhihao Shu, Jiexiong Guan, Xipeng Shen, Miao Yin, Gagan Agrawal, Bin Ren
This work is motivated by recent developments in Deep Neural Networks, particularly the Transformer architectures underlying applications such as ChatGPT, and the need for performing inference on mobile devices. Focusing on emerging transformers (specifically the ones with computationally efficient Swin-like architectures) and large models (e.g., Stable Diffusion and LLMs) based on transformers, we observe that layout transformations between the computational operators cause a significant slowdown in these applications. This paper presents SmartMem, a comprehensive framework for eliminating most layout transformations, with the idea that multiple operators can use the same tensor layout through careful choice of layout and implementation of operations. Our approach is based on classifying the operators into four groups, and considering combinations of producer-consumer edges between the operators. We develop a set of methods for searching such layouts. Another component of our work is developing efficient memory layouts for 2.5 dimensional memory commonly seen in mobile devices. Our experimental results show that SmartMem outperforms 5 state-of-the-art DNN execution frameworks on mobile devices across 18 varied neural networks, including CNNs, Transformers with both local and global attention, as well as LLMs. In particular, compared to DNNFusion, SmartMem achieves an average speedup of 2.8$times$, and outperforms TVM and MNN with speedups of 6.9$times$ and 7.9$times$, respectively, on average.
Read more4/23/2024
💬
0
Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs
Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie
The Large Language Model (LLM) is widely employed for tasks such as intelligent assistants, text summarization, translation, and multi-modality on mobile phones. However, the current methods for on-device LLM deployment maintain slow inference speed, which causes poor user experience. To facilitate high-efficiency LLM deployment on device GPUs, we propose four optimization techniques: (a) a symbolic expression-based approach to support dynamic shape model inference; (b) operator optimizations and execution priority setting to enhance inference speed and reduce phone lagging; (c) an FP4 quantization method termed M0E4 to reduce dequantization overhead; (d) a sub-tensor-based technique to eliminate the need for copying KV cache after LLM inference. Furthermore, we implement these methods in our mobile inference engine, Transformer-Lite, which is compatible with both Qualcomm and MTK processors. We evaluated Transformer-Lite's performance using LLMs with varied architectures and parameters ranging from 2B to 14B. Specifically, we achieved prefill and decoding speeds of 121 token/s and 14 token/s for ChatGLM2 6B, and 330 token/s and 30 token/s for smaller Gemma 2B, respectively. Compared with CPU-based FastLLM and GPU-based MLC-LLM, our engine attains over 10x speedup for the prefill speed and 2~3x speedup for the decoding speed.
Read more7/8/2024

0
Efficiently Training 7B LLM with 1 Million Sequence Length on 8 GPUs
Pinxue Zhao, Hailin Zhang, Fangcheng Fu, Xiaonan Nie, Qibin Liu, Fang Yang, Yuanbo Peng, Dian Jiao, Shuaipeng Li, Jinbao Xue, Yangyu Tao, Bin Cui
Nowadays, Large Language Models (LLMs) have been trained using extended context lengths to foster more creative applications. However, long context training poses great challenges considering the constraint of GPU memory. It not only leads to substantial activation memory consumption during training, but also incurs considerable memory fragmentation. To facilitate long context training, existing frameworks have adopted strategies such as recomputation and various forms of parallelisms. Nevertheless, these techniques rely on redundant computation or extensive communication, resulting in low Model FLOPS Utilization (MFU). In this paper, we propose MEMO, a novel LLM training framework designed for fine-grained activation memory management. Given the quadratic scaling of computation and linear scaling of memory with sequence lengths when using FlashAttention, we offload memory-consuming activations to CPU memory after each layer's forward pass and fetch them during the backward pass. To maximize the swapping of activations without hindering computation, and to avoid exhausting limited CPU memory, we implement a token-wise activation recomputation and swapping mechanism. Furthermore, we tackle the memory fragmentation issue by employing a bi-level Mixed Integer Programming (MIP) approach, optimizing the reuse of memory across transformer layers. Empirical results demonstrate that MEMO achieves an average of 2.42x and 2.26x MFU compared to Megatron-LM and DeepSpeed, respectively. This improvement is attributed to MEMO's ability to minimize memory fragmentation, reduce recomputation and intensive communication, and circumvent the delays associated with the memory reorganization process due to fragmentation. By leveraging fine-grained activation memory management, MEMO facilitates efficient training of 7B LLM with 1 million sequence length on just 8 A800 GPUs, achieving an MFU of 52.30%.
Read more7/18/2024
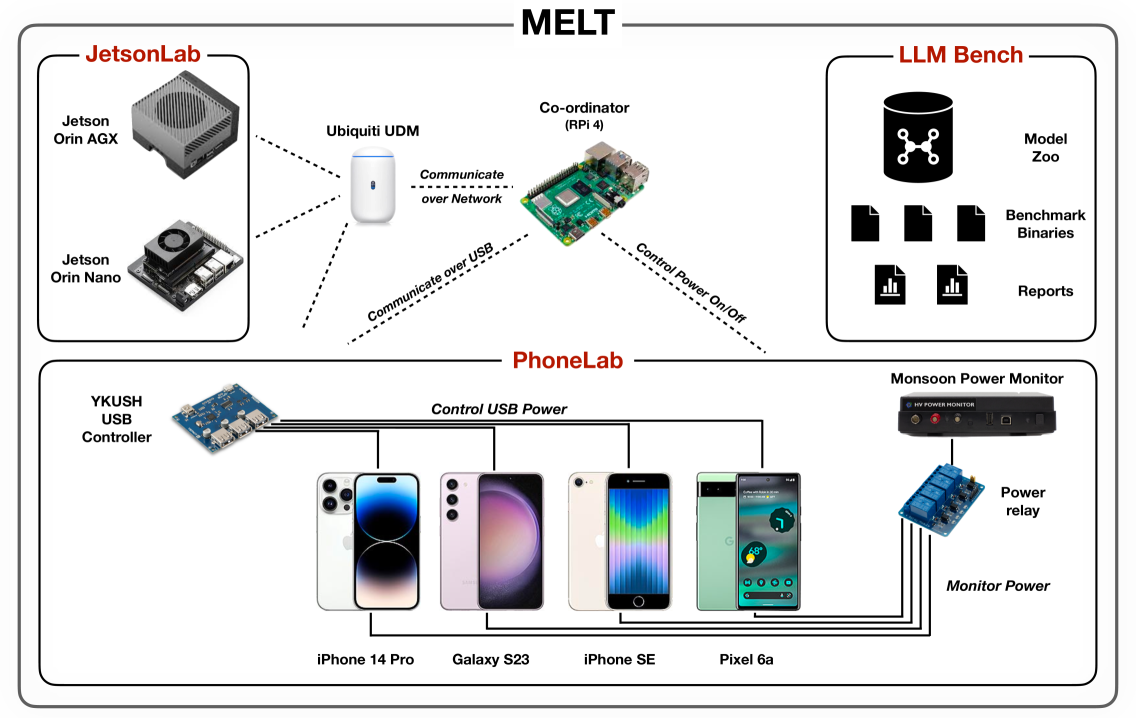
22
MELTing point: Mobile Evaluation of Language Transformers
Stefanos Laskaridis, Kleomenis Katevas, Lorenzo Minto, Hamed Haddadi
Transformers have revolutionized the machine learning landscape, gradually making their way into everyday tasks and equipping our computers with sparks of intelligence. However, their runtime requirements have prevented them from being broadly deployed on mobile. As personal devices become increasingly powerful and prompt privacy becomes an ever more pressing issue, we explore the current state of mobile execution of Large Language Models (LLMs). To achieve this, we have created our own automation infrastructure, MELT, which supports the headless execution and benchmarking of LLMs on device, supporting different models, devices and frameworks, including Android, iOS and Nvidia Jetson devices. We evaluate popular instruction fine-tuned LLMs and leverage different frameworks to measure their end-to-end and granular performance, tracing their memory and energy requirements along the way. Our analysis is the first systematic study of on-device LLM execution, quantifying performance, energy efficiency and accuracy across various state-of-the-art models and showcases the state of on-device intelligence in the era of hyperscale models. Results highlight the performance heterogeneity across targets and corroborates that LLM inference is largely memory-bound. Quantization drastically reduces memory requirements and renders execution viable, but at a non-negligible accuracy cost. Drawing from its energy footprint and thermal behavior, the continuous execution of LLMs remains elusive, as both factors negatively affect user experience. Last, our experience shows that the ecosystem is still in its infancy, and algorithmic as well as hardware breakthroughs can significantly shift the execution cost. We expect NPU acceleration, and framework-hardware co-design to be the biggest bet towards efficient standalone execution, with the alternative of offloading tailored towards edge deployments.
Read more7/29/2024