Sparse multi-view hand-object reconstruction for unseen environments

0
🤷
Sign in to get full access
Overview
- This paper explores the problem of hand-object reconstruction in the sparse multi-view setting, which aims to reconstruct the 3D shape of a hand and object from multiple RGB images.
- The paper introduces a model called SVHO that combines predictions from each view to produce a unified reconstruction, without the need for optimization across views.
- The model is trained on a synthetic hand-object dataset and evaluated on a real-world dataset with unseen objects, demonstrating the potential of sparse multi-view methods to tackle occlusion while keeping computational costs low.
Plain English Explanation
The paper focuses on the task of reconstructing the 3D shape of a hand and an object it is holding, based on multiple camera views. Reconstructing Hand-Held Objects in 3D is a challenging problem in computer vision, as the presence of the hand can occlude parts of the object, making it difficult to reconstruct its full shape.
Previous approaches have explored either single-view methods, which use learned shape priors to generalize to unseen objects but struggle with occlusions, or dense multi-view methods, which are accurate but require collecting a lot of data for new objects. In contrast, this paper investigates the use of sparse multi-view methods, which can take advantage of additional views to tackle occlusion, while keeping the computational cost low compared to dense multi-view approaches.
The paper introduces a model called SVHO that combines the predictions from each camera view into a unified 3D reconstruction, without the need for optimization across views. This model is trained on a synthetic dataset of hand-object interactions and then evaluated on a real-world dataset with unseen objects. The results show that while reconstructing unseen hands and objects from RGB images alone is challenging, the additional camera views can help improve the reconstruction quality.
Technical Explanation
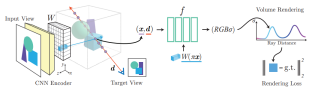
The paper proposes a model called SVHO (Sparse multi-View Hand-Object reconstruction) for the task of hand-object reconstruction in the sparse multi-view setting. The key idea is to leverage multiple camera views to address the occlusion issues that arise in single-view methods, while avoiding the high computational cost of dense multi-view approaches.
SVHO takes as input multiple RGB images of a hand-object interaction captured from different viewpoints and produces a unified 3D reconstruction of the hand and object. The model combines the predictions from each view, without the need for optimization across views. This makes SVHO computationally efficient compared to methods that require such optimization.
The authors train SVHO on a synthetic dataset of hand-object interactions and then evaluate it on a real-world dataset with unseen objects. The results show that while reconstructing unseen hands and objects from RGB images alone is challenging, the additional camera views can help improve the reconstruction quality.
This work builds on previous research in hand-object reconstruction and 3D scene reconstruction from multiple views. It also relates to work on multi-view 3D object recognition and 3D hand mesh reconstruction.
Critical Analysis
The paper presents a novel approach to hand-object reconstruction that leverages sparse multi-view information to address the occlusion issues that arise in single-view methods. The authors demonstrate the effectiveness of their SVHO model on a real-world dataset with unseen objects, which is a significant achievement.
However, the paper does not provide a detailed analysis of the limitations of their approach. For example, it is unclear how the model would perform in scenarios with more complex hand-object interactions or in the presence of significant occlusions. Additionally, the paper does not discuss the scalability of the approach, i.e., how it would perform with a larger number of camera views or more complex scenes.
Further research could explore the robustness of the SVHO model to variations in camera placement, object complexity, and occlusion levels. It would also be interesting to see how the model could be extended to handle dynamic hand-object interactions or integrate additional sensing modalities, such as depth information, to further improve reconstruction accuracy.
Conclusion
This paper presents an innovative approach to hand-object reconstruction in the sparse multi-view setting. By combining predictions from multiple camera views, the SVHO model is able to mitigate the occlusion issues that plague single-view methods, while maintaining computational efficiency. The results on a real-world dataset with unseen objects demonstrate the potential of this approach to advance the state of the art in 3D hand-object reconstruction.
Overall, this research contributes to the ongoing efforts to develop robust and practical 3D reconstruction techniques that can handle the challenges of real-world scenarios, with implications for applications ranging from augmented reality to robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Sparse multi-view hand-object reconstruction for unseen environments
Yik Lung Pang, Changjae Oh, Andrea Cavallaro
Recent works in hand-object reconstruction mainly focus on the single-view and dense multi-view settings. On the one hand, single-view methods can leverage learned shape priors to generalise to unseen objects but are prone to inaccuracies due to occlusions. On the other hand, dense multi-view methods are very accurate but cannot easily adapt to unseen objects without further data collection. In contrast, sparse multi-view methods can take advantage of the additional views to tackle occlusion, while keeping the computational cost low compared to dense multi-view methods. In this paper, we consider the problem of hand-object reconstruction with unseen objects in the sparse multi-view setting. Given multiple RGB images of the hand and object captured at the same time, our model SVHO combines the predictions from each view into a unified reconstruction without optimisation across views. We train our model on a synthetic hand-object dataset and evaluate directly on a real world recorded hand-object dataset with unseen objects. We show that while reconstruction of unseen hands and objects from RGB is challenging, additional views can help improve the reconstruction quality.
Read more5/3/2024

0
Reconstructing Hand-Held Objects in 3D
Jane Wu, Georgios Pavlakos, Georgia Gkioxari, Jitendra Malik
Objects manipulated by the hand (i.e., manipulanda) are particularly challenging to reconstruct from in-the-wild RGB images or videos. Not only does the hand occlude much of the object, but also the object is often only visible in a small number of image pixels. At the same time, two strong anchors emerge in this setting: (1) estimated 3D hands help disambiguate the location and scale of the object, and (2) the set of manipulanda is small relative to all possible objects. With these insights in mind, we present a scalable paradigm for handheld object reconstruction that builds on recent breakthroughs in large language/vision models and 3D object datasets. Our model, MCC-Hand-Object (MCC-HO), jointly reconstructs hand and object geometry given a single RGB image and inferred 3D hand as inputs. Subsequently, we use GPT-4(V) to retrieve a 3D object model that matches the object in the image and rigidly align the model to the network-inferred geometry; we call this alignment Retrieval-Augmented Reconstruction (RAR). Experiments demonstrate that MCC-HO achieves state-of-the-art performance on lab and Internet datasets, and we show how RAR can be used to automatically obtain 3D labels for in-the-wild images of hand-object interactions.
Read more4/11/2024
0
1st Place Solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction
Hang Du, Yaping Xue, Weidong Dai, Xuejun Yan, Jingjing Wang
In this report, we present the 1st place solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction. The challenge aims to evaluate approaches for novel view synthesis and surface reconstruction using only a few posed images of each object. We utilize Pixel-NeRF as the basic model, and apply depth supervision as well as coarse-to-fine positional encoding. The experiments demonstrate the effectiveness of our approach in improving sparse-view reconstruction quality. We ranked first in the final test with a PSNR of 25.44614.
Read more4/17/2024
🏋️
0
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
Kaiwen Jiang, Yang Fu, Mukund Varma T, Yash Belhe, Xiaolong Wang, Hao Su, Ravi Ramamoorthi
Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset. Project page: https://raymondjiangkw.github.io/cogs.github.io/
Read more6/12/2024