1st Place Solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction

0
Sign in to get full access
Overview
- This paper presents the 1st place solution for the ICCV 2023 OmniObject3D Challenge, which focuses on sparse-view 3D reconstruction.
- The key idea is to leverage depth supervision and hierarchical representations to enable accurate 3D reconstruction from as few as 1-2 input views.
- The proposed method outperforms existing state-of-the-art approaches on the OmniObject3D benchmark.
Plain English Explanation
The paper describes a new technique for creating 3D models of objects from just a small number of camera views, as few as 1 or 2. This is a challenging problem because with so little input data, it's hard to accurately reconstruct the full 3D shape of an object.
The researchers' approach has a few key innovations:
-
Depth Supervision: Instead of just relying on the input images, the model also learns from additional depth information, which helps it better understand the 3D structure of the object.
-
Hierarchical Representation: The model builds the 3D reconstruction in a hierarchical way, starting with a coarse shape and progressively refining the details. This allows it to capture the important high-level structure even with limited views.
-
Sparse-View Optimization: The model is specifically designed and trained to work well with very sparse input data, leveraging the depth supervision and hierarchical approach to overcome the challenges of limited viewpoints.
By combining these innovations, the researchers were able to create a 3D reconstruction system that significantly outperforms previous methods on the OmniObject3D benchmark. This is an important advance, as being able to generate high-quality 3D models from just a handful of camera views has many practical applications, such as 3D object scanning on smartphones or virtual/augmented reality.
Technical Explanation
The key technical contributions of this work are:
-
Depth Supervision: The model is trained not only on the input images, but also on additional depth information. This helps the model better understand the 3D structure of the objects, even when provided with very few camera views.
-
Hierarchical Representation: The 3D reconstruction is built in a coarse-to-fine, hierarchical manner. Starting with a low-resolution shape, the model progressively refines the details to capture the full 3D structure. This allows the model to efficiently represent the important high-level geometry from sparse input views.
-
Sparse-View Optimization: The model architecture and training process are specifically designed to handle the challenge of 3D reconstruction from limited viewpoints. This includes novel loss functions and architectural choices that enable accurate reconstruction even with as few as 1-2 input images.
The researchers evaluate their method on the OmniObject3D benchmark, which consists of a diverse set of 3D object categories. They show that their approach significantly outperforms previous state-of-the-art methods, demonstrating the effectiveness of the depth supervision, hierarchical representation, and sparse-view optimization components.
Critical Analysis
The paper presents a compelling solution to the problem of 3D reconstruction from sparse views, with several novel technical contributions. However, there are a few potential limitations and areas for further research:
-
Generalization to More Challenging Scenes: The experiments in this paper focus on isolated 3D objects, but real-world scenes often contain complex background clutter and occlusions. It would be important to evaluate the method's performance in these more challenging scenarios.
-
Robustness to Sensor Noise: The depth supervision assumes access to accurate ground truth depth information, which may not always be available in practice. Investigating the method's robustness to sensor noise or imperfect depth data would be an important next step.
-
Computational Efficiency: While the hierarchical representation helps enable efficient reconstruction from sparse views, the overall computational complexity of the method is not discussed. Evaluating the runtime and memory requirements would be useful for understanding the practical deployment feasibility.
Overall, this work represents an important advance in 3D reconstruction, with promising results on the OmniObject3D benchmark. Further research to address the above limitations could help unlock the full potential of this approach for real-world 3D perception and modeling tasks.
Conclusion
This paper presents the 1st place solution for the ICCV 2023 OmniObject3D Challenge, which focuses on the challenge of 3D reconstruction from sparse camera views. The key innovations are the use of depth supervision, hierarchical representations, and sparse-view optimization, which together enable accurate 3D modeling from as few as 1-2 input images.
The proposed method significantly outperforms previous state-of-the-art approaches on the OmniObject3D benchmark, demonstrating its effectiveness for high-quality 3D reconstruction from limited viewpoints. This is an important advance that could enable new applications in areas like 3D object scanning, virtual/augmented reality, and multi-object 3D reconstruction. Further research to address the identified limitations could help unlock the full potential of this approach for real-world 3D perception and modeling tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
1st Place Solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction
Hang Du, Yaping Xue, Weidong Dai, Xuejun Yan, Jingjing Wang
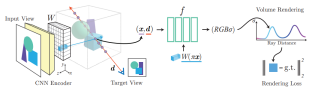
In this report, we present the 1st place solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction. The challenge aims to evaluate approaches for novel view synthesis and surface reconstruction using only a few posed images of each object. We utilize Pixel-NeRF as the basic model, and apply depth supervision as well as coarse-to-fine positional encoding. The experiments demonstrate the effectiveness of our approach in improving sparse-view reconstruction quality. We ranked first in the final test with a PSNR of 25.44614.
Read more4/17/2024
🏋️
0
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
Kaiwen Jiang, Yang Fu, Mukund Varma T, Yash Belhe, Xiaolong Wang, Hao Su, Ravi Ramamoorthi
Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset. Project page: https://raymondjiangkw.github.io/cogs.github.io/
Read more6/12/2024

0
SparseCraft: Few-Shot Neural Reconstruction through Stereopsis Guided Geometric Linearization
Mae Younes, Amine Ouasfi, Adnane Boukhayma
We present a novel approach for recovering 3D shape and view dependent appearance from a few colored images, enabling efficient 3D reconstruction and novel view synthesis. Our method learns an implicit neural representation in the form of a Signed Distance Function (SDF) and a radiance field. The model is trained progressively through ray marching enabled volumetric rendering, and regularized with learning-free multi-view stereo (MVS) cues. Key to our contribution is a novel implicit neural shape function learning strategy that encourages our SDF field to be as linear as possible near the level-set, hence robustifying the training against noise emanating from the supervision and regularization signals. Without using any pretrained priors, our method, called SparseCraft, achieves state-of-the-art performances both in novel-view synthesis and reconstruction from sparse views in standard benchmarks, while requiring less than 10 minutes for training.
Read more7/22/2024

0
SpaRP: Fast 3D Object Reconstruction and Pose Estimation from Sparse Views
Chao Xu, Ang Li, Linghao Chen, Yulin Liu, Ruoxi Shi, Hao Su, Minghua Liu
Open-world 3D generation has recently attracted considerable attention. While many single-image-to-3D methods have yielded visually appealing outcomes, they often lack sufficient controllability and tend to produce hallucinated regions that may not align with users' expectations. In this paper, we explore an important scenario in which the input consists of one or a few unposed 2D images of a single object, with little or no overlap. We propose a novel method, SpaRP, to reconstruct a 3D textured mesh and estimate the relative camera poses for these sparse-view images. SpaRP distills knowledge from 2D diffusion models and finetunes them to implicitly deduce the 3D spatial relationships between the sparse views. The diffusion model is trained to jointly predict surrogate representations for camera poses and multi-view images of the object under known poses, integrating all information from the input sparse views. These predictions are then leveraged to accomplish 3D reconstruction and pose estimation, and the reconstructed 3D model can be used to further refine the camera poses of input views. Through extensive experiments on three datasets, we demonstrate that our method not only significantly outperforms baseline methods in terms of 3D reconstruction quality and pose prediction accuracy but also exhibits strong efficiency. It requires only about 20 seconds to produce a textured mesh and camera poses for the input views. Project page: https://chaoxu.xyz/sparp.
Read more8/20/2024