STELLA: Continual Audio-Video Pre-training with Spatio-Temporal Localized Alignment

0
🛸
Sign in to get full access
Overview
- Continual learning of audio-video semantics is crucial for audio-related reasoning tasks, but poses challenges like sparse spatio-temporal correlation and multimodal correlation overwriting.
- The paper proposes a new continual audio-video pre-training method with two key ideas: Localized Patch Importance Scoring and Replay-guided Correlation Assessment.
- The method achieves improved performance in zero-shot retrieval tasks while reducing memory consumption compared to strong continual learning baselines.
Plain English Explanation
The paper addresses the problem of continuously learning the relationship between audio and video data over time, which is important for tasks like understanding sound in videos. This is a difficult challenge because the connection between audio and video can be sparse and change over time, causing the model to forget previous audio-video relationships.
To tackle this, the researchers developed a new approach for continual audio-video pre-training with two main innovations. First, they use a multimodal encoder to determine which parts of the audio and video are most semantically connected, and focus on those areas. Second, they assess how the current audio-video data relates to what the model has learned in the past, to avoid forgetting previous knowledge.
By using these techniques, the model is able to continuously learn the relationship between audio and video better than previous methods. This leads to improved performance on tasks like retrieving relevant videos based on audio, while also requiring less memory to store the learned information.
Technical Explanation
The paper proposes a new method for continual audio-video pre-training, which aims to continuously learn the semantics linking audio and video data over time. This is a challenging problem due to two key issues:
- Sparse Spatio-Temporal Correlation: The relationship between audio and video can be sparse, with only certain parts of the audio and video being semantically correlated.
- Multimodal Correlation Overwriting: As the model learns new audio-video relationships, it can overwrite and forget previously learned connections.
To address these problems, the authors introduce two novel components:
- Localized Patch Importance Scoring: The method uses a multimodal encoder to determine the importance score of each patch (a small region) in the audio and video, focusing on the patches where the semantics are most intertwined. This builds on prior work in learning spatial features from audio-visual correspondence.
- Replay-guided Correlation Assessment: To reduce the risk of forgetting previous audio-video knowledge, the method assesses how the current patches relate to the patches learned in past steps. This helps identify the patches that exhibit high correlation with the past, preventing their overwriting.
Based on the results of these two components, the method performs a probabilistic patch selection process to effectively continually pre-train the audio-video model. This helps the model retain previously learned knowledge while continuously acquiring new audio-video semantics.
The researchers validate their method on multiple benchmarks, showing that it achieves a 3.69% relative performance gain in zero-shot retrieval tasks compared to strong continual learning baselines. Additionally, the method reduces memory consumption by approximately 45%, demonstrating its efficiency.
Critical Analysis
The paper introduces a novel and promising approach to the challenge of continual audio-video learning. The two key ideas, Localized Patch Importance Scoring and Replay-guided Correlation Assessment, provide a thoughtful way to address the issues of sparse spatio-temporal correlation and multimodal correlation overwriting.
However, the paper does not address some potential limitations of the approach. For example, the method may struggle with scenarios where the audio-video relationships are more complex or dynamic, requiring more sophisticated modeling techniques. Additionally, the reliance on patch-level processing could limit the model's ability to capture higher-level, holistic audio-video semantics.
Furthermore, the paper could have provided more detailed analysis and discussion of the method's limitations, such as the potential impact of dataset biases or the generalizability of the approach to different types of audio-video data. Incorporating these aspects could have strengthened the critical analysis and encouraged readers to think more deeply about the implications and future research directions.
Despite these potential areas for improvement, the paper presents a valuable contribution to the field of unified audio-visual perception and text-guided visual sound source localization, demonstrating the potential of continual learning techniques to enhance audio-video understanding.
Conclusion
This paper addresses the crucial challenge of continuously learning the semantics linking audio and video data over time, which is essential for audio-related reasoning tasks in our ever-evolving world. By introducing the novel concepts of Localized Patch Importance Scoring and Replay-guided Correlation Assessment, the proposed method is able to outperform strong continual learning baselines while requiring less memory.
The implications of this work extend beyond audio-video understanding, as the principles of continual learning and multimodal correlation preservation could be applied to a wide range of multimodal perception and reasoning tasks. As the field of AI continues to advance, the ability to learn and retain knowledge in a dynamic, lifelong manner will become increasingly important for building intelligent systems that can adapt and thrive in our complex, changing world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
STELLA: Continual Audio-Video Pre-training with Spatio-Temporal Localized Alignment
Jaewoo Lee, Jaehong Yoon, Wonjae Kim, Yunji Kim, Sung Ju Hwang
Continuously learning a variety of audio-video semantics over time is crucial for audio-related reasoning tasks in our ever-evolving world. However, this is a nontrivial problem and poses two critical challenges: sparse spatio-temporal correlation between audio-video pairs and multimodal correlation overwriting that forgets audio-video relations. To tackle this problem, we propose a new continual audio-video pre-training method with two novel ideas: (1) Localized Patch Importance Scoring: we introduce a multimodal encoder to determine the importance score for each patch, emphasizing semantically intertwined audio-video patches. (2) Replay-guided Correlation Assessment: to reduce the corruption of previously learned audiovisual knowledge due to drift, we propose to assess the correlation of the current patches on the past steps to identify the patches exhibiting high correlations with the past steps. Based on the results from the two ideas, we perform probabilistic patch selection for effective continual audio-video pre-training. Experimental validation on multiple benchmarks shows that our method achieves a 3.69%p of relative performance gain in zero-shot retrieval tasks compared to strong continual learning baselines, while reducing memory consumption by ~45%.
Read more5/29/2024
0
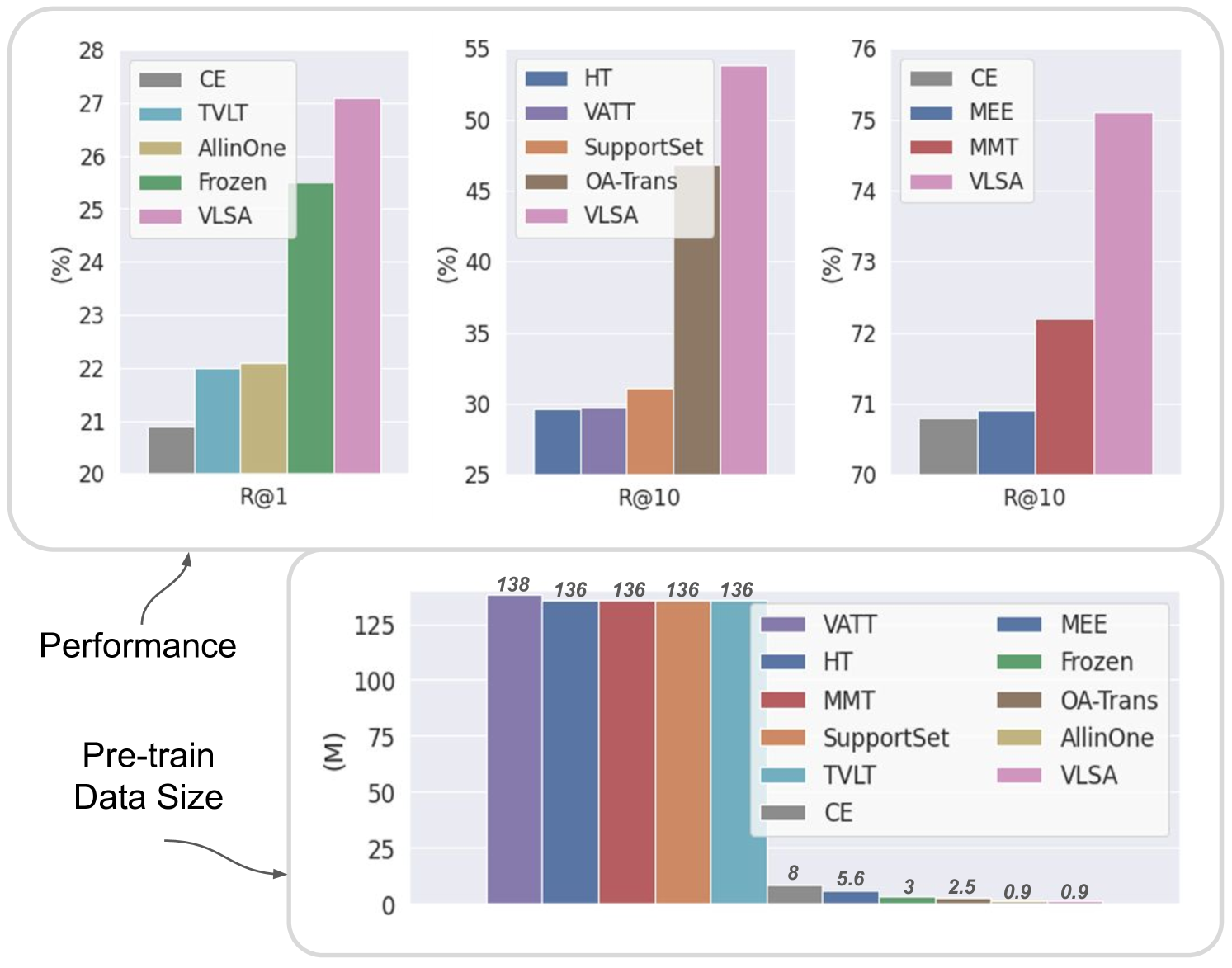
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
Read more5/14/2024

0
New!STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment
Yong Ren, Chenxing Li, Manjie Xu, Wei Liang, Yu Gu, Rilin Chen, Dong Yu
Visual and auditory perception are two crucial ways humans experience the world. Text-to-video generation has made remarkable progress over the past year, but the absence of harmonious audio in generated video limits its broader applications. In this paper, we propose Semantic and Temporal Aligned Video-to-Audio (STA-V2A), an approach that enhances audio generation from videos by extracting both local temporal and global semantic video features and combining these refined video features with text as cross-modal guidance. To address the issue of information redundancy in videos, we propose an onset prediction pretext task for local temporal feature extraction and an attentive pooling module for global semantic feature extraction. To supplement the insufficient semantic information in videos, we propose a Latent Diffusion Model with Text-to-Audio priors initialization and cross-modal guidance. We also introduce Audio-Audio Align, a new metric to assess audio-temporal alignment. Subjective and objective metrics demonstrate that our method surpasses existing Video-to-Audio models in generating audio with better quality, semantic consistency, and temporal alignment. The ablation experiment validated the effectiveness of each module. Audio samples are available at https://y-ren16.github.io/STAV2A.
Read more9/16/2024

0
Video-Language Alignment Pre-training via Spatio-Temporal Graph Transformer
Shi-Xue Zhang, Hongfa Wang, Xiaobin Zhu, Weibo Gu, Tianjin Zhang, Chun Yang, Wei Liu, Xu-Cheng Yin
Video-language alignment is a crucial multi-modal task that benefits various downstream applications, e.g., video-text retrieval and video question answering. Existing methods either utilize multi-modal information in video-text pairs or apply global and local alignment techniques to promote alignment precision. However, these methods often fail to fully explore the spatio-temporal relationships among vision tokens within video and across different video-text pairs. In this paper, we propose a novel Spatio-Temporal Graph Transformer module to uniformly learn spatial and temporal contexts for video-language alignment pre-training (dubbed STGT). Specifically, our STGT combines spatio-temporal graph structure information with attention in transformer block, effectively utilizing the spatio-temporal contexts. In this way, we can model the relationships between vision tokens, promoting video-text alignment precision for benefiting downstream tasks. In addition, we propose a self-similarity alignment loss to explore the inherent self-similarity in the video and text. With the initial optimization achieved by contrastive learning, it can further promote the alignment accuracy between video and text. Experimental results on challenging downstream tasks, including video-text retrieval and video question answering, verify the superior performance of our method.
Read more7/25/2024